 Browser
Browser
# 浏览器
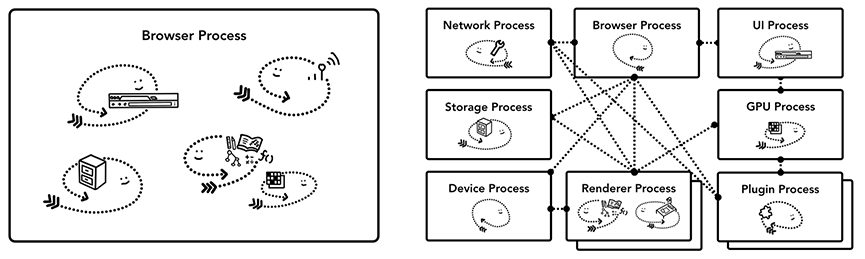
浏览器是一个多进程架构,我们关心渲染进程(核心进程)
为何使用多进程架构?
多个线程共享 相同地址空间和资源,存在 线程之间可能恶意修改/获取 非授权数据 等 安全问题
单进程浏览器: 1、不稳定。单进程中 插件、渲染线程崩溃导致 浏览器崩溃 2、不流畅。脚本(死循环)/插件会使浏览器卡顿 3、不安全。插件和脚本可获取OS 任意资源
多进程浏览器: 1、解决不稳定。进程 相互隔离,一个页面/插件崩溃时,仅影响当前插件/页面 2、解决不流畅。脚本阻塞当前页面渲染进程,不影响其他页面 3、解决不安全。多进程架构使用沙箱。沙箱看成是OS给进程上一把锁,沙箱的程序可以运行,不能在硬盘上写入数据,不能在敏感位置读取数据
沙箱 将渲染进程和OS隔离
利用OS提供的安全技术,渲染进程在执行过程中无法访问OS的数据,渲染进程需要访问系统资源时,通过浏览器内核实现,将访问结果通过IPC转发给渲染进程
# 主要进程
1、浏览器主进程
控制页面创建、销毁、网络资源管理、下载等, 提供存储等功能
浏览器进程中线程:
- UI进程
- 存储线程:控制文件的访问
2、插件进程
负责插件运行,插件易崩溃,需通过插件进程隔离,保证插件进程崩溃不会对浏览器/页面造成影响
3、GPU进程
最多一个,用于3D绘制等,从浏览器进程中独立出来
4、浏览器渲染进程(浏览器内核)
**每个Tab页对应一个进程,互不影响 , 将HTML、CSS 和 JS转换为可以与用户交互的网页 **
5、网络进程
从浏览器进程中独立出来, 负责页面的网络资源加载
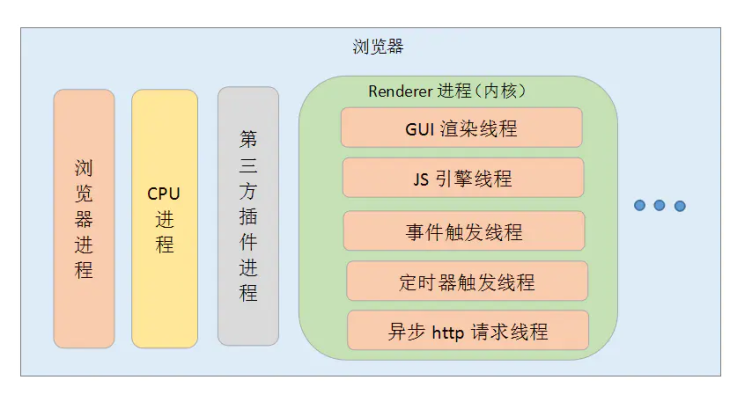
# 渲染进程多线程
1、GUI 线程
渲染页面。在JS引擎运行脚本期间**,GUI渲染线程都是处于挂起状态的,被”冻结”了**
2、JS 引擎线程
**解析和执行 JS ,v8 引擎 跑在 JS 引擎线程上,没有单/多线程之说,因为解释这个语言的是 的线程 是单线程;**JS 引擎线程与 GUI 线程互斥,浏览器执行 JS 程序的时候,GUI 渲染线程 保存在一个队列当中;直到 JS 程序执行完成,才接着执行;如果 JS 执行时间过长,会影响页面的渲染,所有要尽量控制 JS 的大小
3、定时触发线程
JS引擎是单线程**, 处于阻塞线程状态会影响记计时的准确, 因此通过单独线程来计时并触发定时是更为合理的方案**
为什么 setTimeout 不阻塞后面程序的运行,因为 setTimeout 不是由 JS 引擎线程完成,是由定时器触发线程完的,所以它们可以同时进行,定时器触发线程 在定时任务完成后 通知事件触发线程 往任务队列里添加事件
4、事件触发线程
当一个事件被触发时该线程把事件添加到待处理队列的队尾,等待JS引擎处理。这些事件可以是当前执行的代码块如定时任务、也可来自浏览器内核的其他线程如鼠标点击、AJAX异步请求等
5、异步 HTTP 请求线程
XMLHttpRequest 连接 通过浏览器新开线程请求, 检测到状态变更,如果设置有回调,异步线程就产生状态变更事件放到 JS引擎的处理队列中等待处理
# 内核
浏览器内核 通过取得页面内容、整理信息、计算和组合最终输出可视化图像结果(渲染引擎)
每一个tab页面可以看作是浏览器内核进程,浏览器内核是多线程的
# 常见浏览器内核?
Trident内核:IE,360,搜狗等浏览器
Gecko内核:Firefox
Blink内核:Opera7及以上
Webkit内核:Safari,Chrome
# 检测版本
window.navigator.userAgent不可靠,因为userAgent可被改写,早期浏览器如 ie,会伪装自己的userAgent值为Mozilla躲过检测- 功能检测,根据每个浏览器独有特性判断,如 ie 独有
ActiveXObject
# 判断访问设备
navigator.userAgent
设备屏幕的宽度大小
客户端操作系统类型(platform)
# ⚠️Event Loop
面试率超高的JS事件循环,看这篇就够了 (opens new window)
面试必问之 JS 事件循环(Event Loop),看这一篇足够 (opens new window)
事件循环,是指浏览器或Node解决JS单线程运行时不会阻塞的一种机制——我们经常使用异步的原理
设置 2 个线程,一个负责程序本身的运行——“主线程”
另一个负责主线程和其他进程(主要是各种 I/O 操作)的通信 ——“Event Loop 线程”
JS 采用这种机制,解决单线程带来的问题
JS 引擎执行代码时会产生执行栈,调用异步 API,例如
setTimeout,setInterval,Promise等回调触发时,会进入异步任务队列,当同步代码执行完成后,会去异步队列取出回调函数执行,形成事件循环
事件循环任务:将队列和调用堆栈连接起来
执行栈类似于函数调用栈的运行容器,当其为空,JS检查事件队列,将第一个任务压入栈中执行。若调用栈和微任务队列为空,事件循环检查宏任务队列是否还有任务,弹出进入调用栈执行再弹出
setTimeout回调 不是马上执行,而是最快可以多久后执行,因为它会等待调用 栈为空
浏览器的渲染必须要调用栈为空时才会执行
一个回调出栈,另一个回调进栈的间隙(此时栈空),渲染得以顺利进行
# JS单线程问题
setTimeout如果在主线程上运行会阻塞其他活动
所以,需要做的就是,离开这个线程,同时运行这个任务
作为浏览器脚本语言,JS主要用于 用户互动、操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题
比如,假定JS同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?所以,为了避免复杂
JS异步实现?
浏览器的内核多线程实现
# Event Loop
任务被分为 宏任务 和 微任务
- 宏观:浏览器多线程(从宏观来看是多线程实现了异步)
- 微观:Event Loop
**常见的macrotask有:(一般由浏览器发起)**DOM渲染后触发
- script整体代码
- setImmediate(node )
- setTimeout 和 setInterval
- requestAnimationFrame??不是宏任务!(CSS详述)
- I/O
- UI rendering
POSTMessage
常见的microtask有:(一般由JS自身创建)DOM渲染前触发
- process.nextTick (Node)
- Promise callback(例如 promise.then)
- Object.observe (基本已废弃)
- MutationObserver
# 运行过程
JS 有一个 main thread 主线程和 call-stack 调用栈(执行栈),所有的任务都放到调用栈等待主线程执行
单线程任务分为同步/异步任务,同步任务在调用栈中按照顺序等待主线程执行,异步任务在有了结果后,将注册的回调放入任务队列中等待主线程空闲时(调用栈被清空),被读取到栈内等待主线程执行
线程都有自己的运行数据存储空间,堆的空间比较大,所以存储对象
函数调用就入栈,执行完函数体的代码自动从栈中弹出——调用栈
当栈中的函数出栈时,栈为空的话,我们会调用一些异步函数,这个异步函数会找它们的异步处理模块,异步处理模块包括定时器、promise、Ajax等,异步处理模块会找它们各自对应的线程,线程向任务队列中添加事件,再从任务队列中取出事件,执行对应的回调
3个注意点:
- 当宏任务执行完,会去执行所有微任务
- 微任务执行完再去执行下一个宏任务,等调用栈为空时执行一个微任务;调用栈不为空时,任务队列的微任务一直等;微任务执行完又去取任务队列的宏任务**,依次执行宏任务,执行宏任务时检查当前是否存在微任务,若有微任务就去 执行完所有微任务,然后 再去执行宏任务 **
注意点:
- 一个 Event Loop 有一/多个 task queue(任务队列)
- 每个 Event Loop 有一个 microtask queue(微任务队列)
- requestAnimationFrame 不在任务队列也不在微任务队列,在渲染阶段执行
- 任务需要多次事件循环才能执行完,微任务是一次性执行完
- 第一个宏任务(主程序)执行完,执行全部的微任务(一个 promise),再执行下一个宏任务(settimeout)
(1)所有同步任务都在主线程上执行,形成 执行栈
(2)主线程之外, 存在 "任务队列"(task queue)。只要异步任务有 结果,就在"任务队列"之中放置一个事件
(3)同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入Event Table并注册
(4)当指定 事情完成 ,Event Table 将这个函数移入Event Queue
(3)一旦"执行栈"中的所有同步任务执行完毕,系统 读取"任务队列(event Queue)"的异步任务,如果有就推入主线程
(4)主线程不断重复以上步骤
要把本次宏任务下所产生的微任务全部执行完才会执行下一个宏任务,记住是产生的,没有产生的不会执行!
async函数是对一些异步操作的处理方式,一旦调用会立即执行,其中可包含微任务和宏任务
await语句后面的代码回放进微任务队列执行
2
3
**一轮事件循环就是第一轮宏任务和微任务结束。**当微任务队列清空后,一个事件循环结束
正确的一次 Event loop 顺序是:
- 执行同步代码,这属于宏任务
- 执行栈为空,查询是否有微任务需要执行
- 执行所有微任务
- 必要的话渲染 UI
- 然后开始下一轮 Event loop,执行宏任务中的异步代码
如果宏任务中的异步代码有大量的计算并且需要操作 DOM 的话,为了更快的 界面响应,我们可以把操作 DOM 放入微任务中
# JS处理异步事件
- 同步任务:主线程排队执行的任务,只有前一个执行完毕,才能执行后一个
- 异步任务:不进入主线程、进入"任务队列"(task queue)的任务,只有"任务队列"通知主线程,某个异步任务可以执行,该任务才进入主线程执行
既然JS是单线程的,只能在一条线程上执行, 如何实现异步 ?——事件循环(event loop)
执行栈
js 生成 与 方法对应的执行环境(context)——执行上下文。这个执行环境中存在着这个方法的私有作用域,上层作用域的指向,方法的参数,这个作用域中定义的变量以及这个作用域的this。当方法被依次调用,同一时间只能执行一个,于是这些方法被排队在单独的地方——执行栈
任务队列
js的另一大特点——非阻塞, 关键在于任务队列
js引擎遇到 异步任务后 不会一直等待其返回结果,而是 将这个任务 压入到任务队列 ,继续执行执行栈中的 任务。当 异步任务返回结果后,js 将这个任务加入与当前执行栈不同的另一个队列——任务队列
被放入任务队列不会立刻执行,而是等待当前执行栈中的所有任务 执行完毕, 主线程处于闲置状态时,去查找任务队列是否有任务。如果有, 主线程会从中取出排在第一位的事件, 把这个任务对应的回调放入执行栈中, 执行其 同步代码, 反复 形成 无限的循环
# 事件队列有优先级吗
# Node事件循环
官网描述:
Node.js启动时,初始化事件循环,处理输入脚本,这个脚本可能异步API调用、调度计时器/调用process.nextTick(),然后开始处理事件循环
JS和Node.js 基于V8 引擎 ,浏览器 包含 异步方式在 Node 是一样的。除此之外,Node 还有一些其他的异步形式
microtask 在事件循环的各个阶段之间执行(一个阶段执行完毕,就去执行microtask队列)。和浏览器不同,nodejs是来都来了,一次执行完该阶段的任务好了
# 事件循环顺序
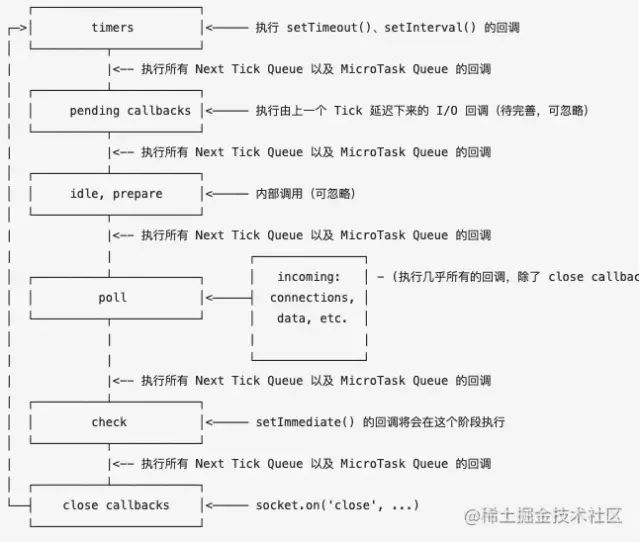
timers 阶段 :执行setTimeout和setInterval的callback
pending IO callbacks:系统操作的回调,如定时器和
setImmediate回调,上一轮循环中少数callback的执行idle,prepare:仅在内部使用
poll:等待新的 I/O 事件进来,其他所有宏任务都属于poll阶段,最重要的阶段,执行pending callback,适当的情况会阻塞在这个阶段
- 当 poll 中没有定时器,发生两件事
poll 队列不为空,遍历回调队列并同步执行,直到队列为空或者系统限制
poll 队列为空,两件事
- 有
setImmediate需要执行,poll 阶段停止并进入到 check 阶段执行setImmediate - 没有
setImmediate需要执行,等待回调被加入到队列中并立即执行回调
如果有别的定时器需被执行,回到 timer 阶段执行回调
- 有
check:setImmediate回调执行
close callbacks:内部使用,关闭回调执行
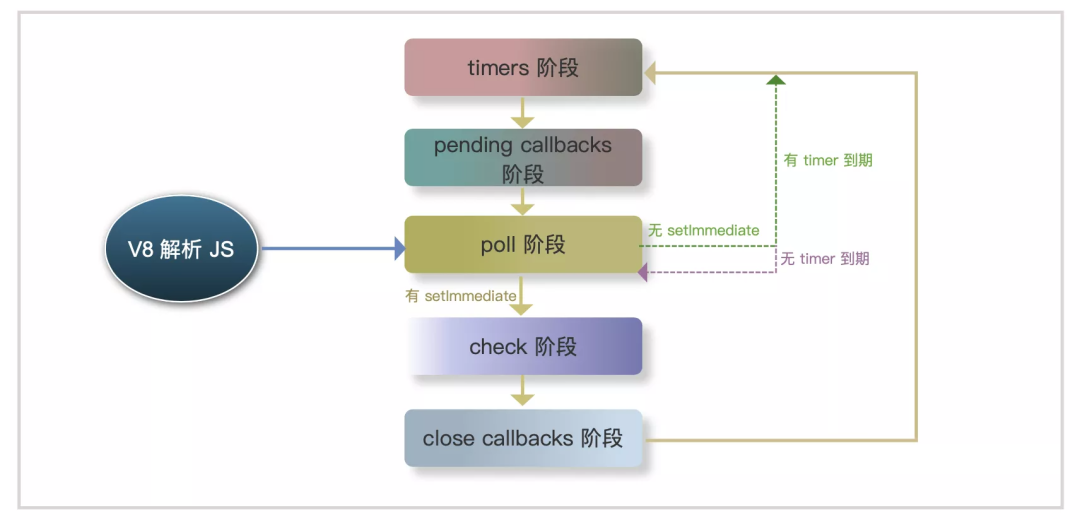
每个阶段都去执行完当前阶段的任务队列,继续执行当前阶段的微任务队列,只有当前阶段所有微任务都执行完,才进入下阶段。这里也是与浏览器中逻辑差异较大的地方,不过浏览器不区分这些阶段,也少了很多异步操作类型,不用刻意区分两者区别
另一个与浏览器的差异体现在同一个阶段不同任务执行
- 浏览器,宏任务完成优先处理微任务
- Node,处于 timers 阶段,先将所有 timer 回调执行完之后再执行微任务
差异可以用浏览器和 NodeJS 10 对比验证。感觉有点反程序员?因此 NodeJS 在 11 后,修改了此处逻辑使其与浏览器尽量一致,每个 timer 执行后都检查微任务队列, NodeJS 11 后的输出已经和浏览器一致了
# process.nextTick
将一个函数推迟到代码中所书写的下一个同步方法执行完毕或异步方法的事件回调开始执行时调用,该方法 参数是被推迟的函数
process.nextTic和微任务啥时候执行?process.nextTick优先于微任务
# setTimeout、setImmediate
二者相似,区别在调用时机不同
setImmediate —— check 阶段
setTimeout poll 阶段为空闲时,且设定时间到达后执行, timer 阶段执行
# setTimeout
每一个setTimeout在执行时,会返回唯一ID
for ( var i=1; i<=5; i++) {
setTimeout( function timer(j) {
console.log( j );
}, i*1000, i);
}
2
3
4
5
利用setTimeout第三个参数解决循环输出问题
process.nextTick() 比 promise.then()执行早,同步任务后,其他所有异步任务前,优先执行 nextTick。可以想象是把 nextTick 的任务放到了当前循环的后面,与 promise.then() 类似,但比 promise.then() 更前面。
当前同步代码执行完成后,不管其他异步任务,尽快执行 nextTick
# 栗子
function cb(msg) {
return function () {
console.log(msg)
}
}
setTimeout(cb('setTimeout'), 100)
setTimeout(cb('setImmediate'))
process.nextTick(cb('process.nextTick'))
cb('Main process')()
2
3
4
5
6
7
8
9
10
# node和浏览器事件循环区别
流程对比:
- 执行 Script 代码
- 把微任务队列清空:Node 清空微任务队列的手法比较特别。在浏览器中,我们只有一个微任务队列需要接受处理;但在 Node 中,有两类微任务队列:next-tick 队列和其它队列。next-tick 队列专门收敛 process.nextTick 派发的异步任务。清空队列时,优先清空 next-tick 队列中的任务,随后才会清空其它微任务
- 开始执行 macro-task(宏任务)。Node 执行宏任务的方式与浏览器不同:在浏览器中,每次出队执行一个宏任务; Node 中,我们每次会尝试清空当前阶段对应宏任务队列里的所有任务
- 步骤3开始,进入 3 -> 2 -> 3 -> 2…的循环
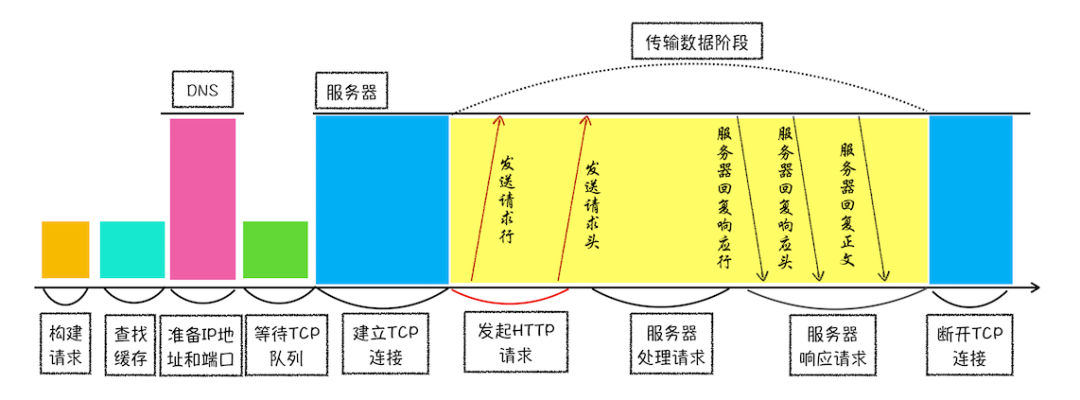
# ✅ 输入URL回车后……
- URL解析
- 查找缓存
- 域名解析:浏览器>系统>本地hosts>根域名>顶级域名>二级域名>三级域名
- TCP三次握手
- 发送HTTP请求
- 处理请求并返回
- 解析渲染页面
- TCP四次挥手
# 🅰️ 导航阶段
# ①浏览器主进程
# 1.输入URL
**1、**浏览器进程检查url,组装协议,构成完整url,两种情况:
- 输入 搜索内容:地址栏使用浏览器默认搜索引擎,合成新的带搜索关键字的
URL - 输入 URL:地址栏根据规则,给这段内容加上协议,合成为完整
URL
**2、**浏览器进程通过进程间通信(IPC)把url请求发送给网络进程
URL一般包括几大部分:
protocol,协议头,如http,ftphost,主机域名/IP地址port,端口号path,目录路径query,查询参数fragment,#后的hash值,一般用来定位到某个位置

# ②网络进程
# 2.URL请求
**3、**网络进程接收到url请求后检查本地是否缓存
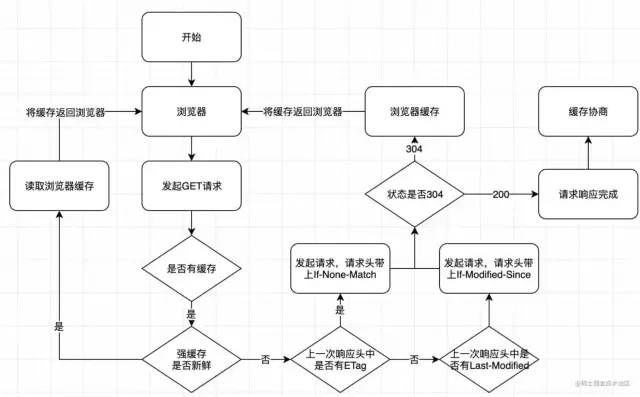
浏览器发送请求前,根据请求头的
expires和cache-control判断是否命中(包括是否过期)强缓存策略,如果命中,直接从缓存获取资源,不会发送请求。如果没有命中,进入下一步没有命中强缓存规则,浏览器发送请求,根据请求头的
If-Modified-Since(last_modified)和If-None-Match(ETag)判断是否命中协商缓存,如果命中,直接从缓存获取资源。如果没有命中,进入下一步如果前两步都没有命中,直接从服务端获取资源
**4、**准备IP地址和端口:DNS解析时先查找缓存,没有再使用DNS服务器解析,查找顺序:
浏览器缓存
本机缓存
hosts文件路由器缓存
ISP DNS缓存DNS递归查询(本地DNS服务器 -> 权限DNS服务器 -> 顶级DNS服务器 ->13台根DNS服务器)
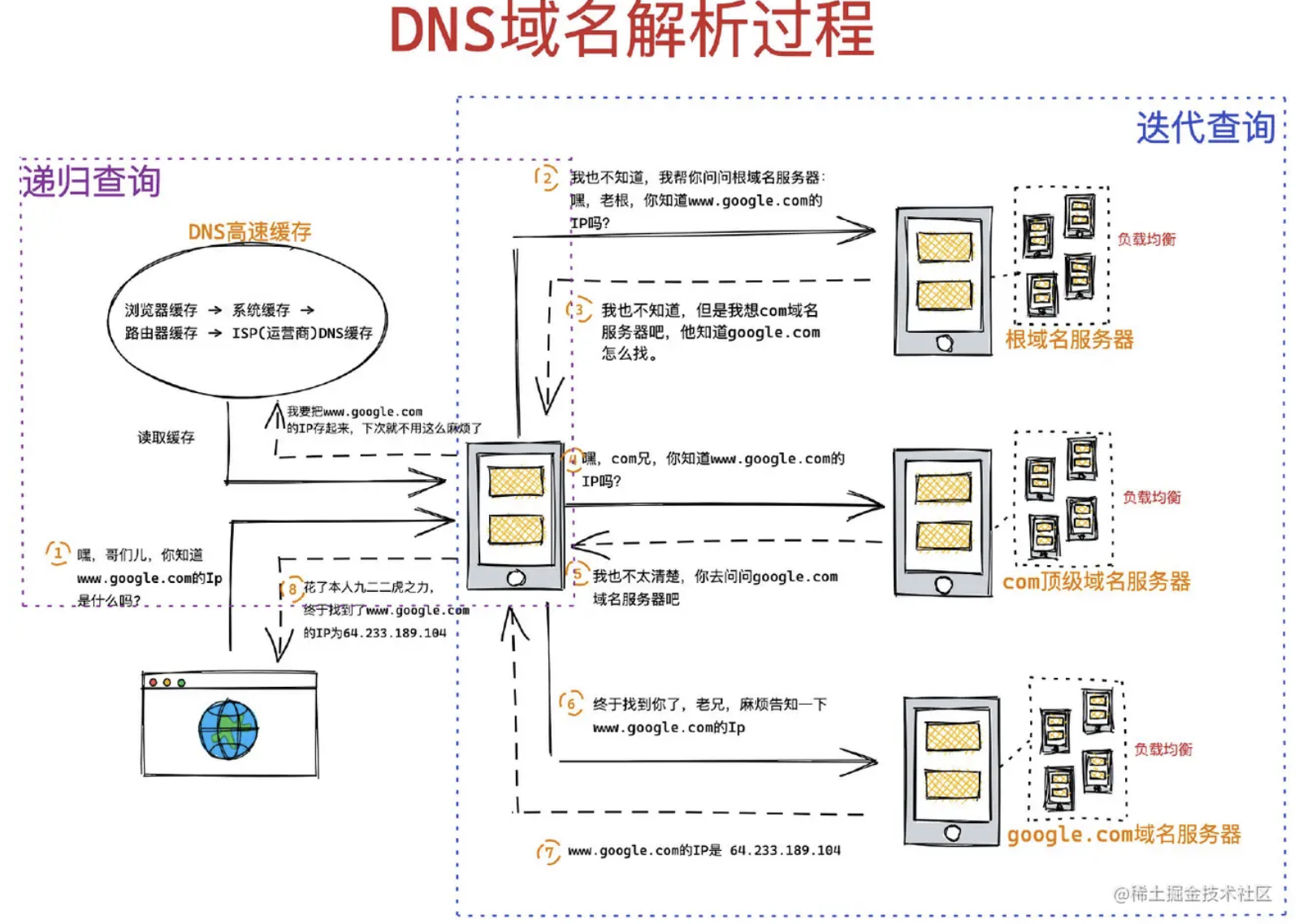
域名查询时可能经过了CDN调度器(如果有cdn存储功能的话)
dns解析很耗时,解析域名过多会让首屏加载变得过慢,可以考虑
dns-prefetch优化https://developer.mozilla.org/zh-CN/docs/Web/Performance/dns-prefetch
**5、**等待TCP队列:浏览器为每个域名最多维护6个TCP连接,如果发起一个HTTP请求时,这 6个 TCP连接都处于忙碌状态,请求会处于排队状态,解决:
采用域名分片技术:将一个站点的资源放在多个(
CDN)域名下面- 升级为
HTTP2,就没有6个TCP连接的限制了
- 升级为
**6、**三次握手建立TCP连接:
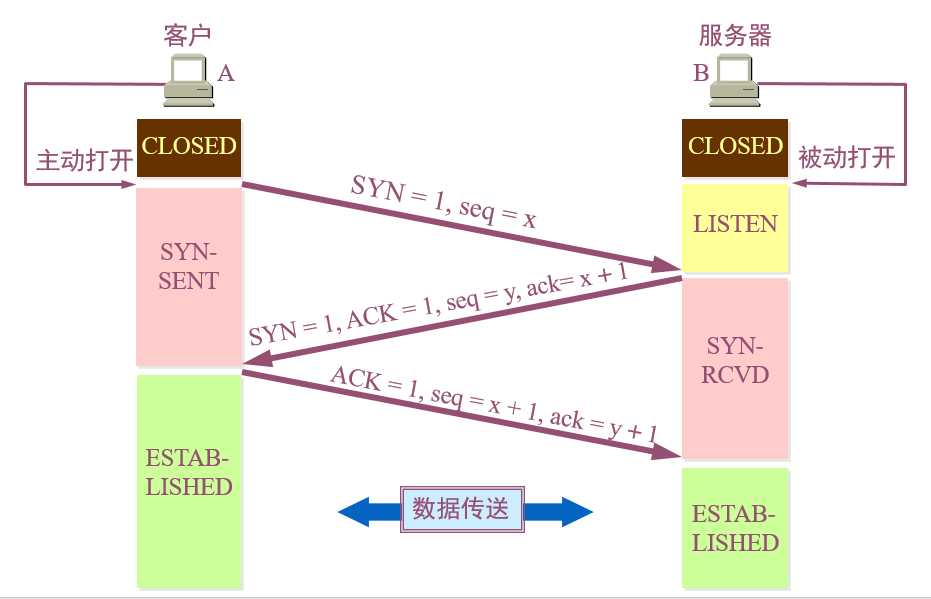
- 第一次:**客户端向服务器端发送一个同步数据包,报文的
TCP首部中:**同步SYN为1,表示这是一个请求建立连接的数据包;序号Seq=x,x为所传送数据的第一个字节的序号,随后进入SYN-SENT状态
标志位值为
1表示该标志位有效
- **第二次:**服务器根据收到数据包的
SYN标志位判断为建立连接的请求,返回一个确认数据包,标志位SYN=1,ACK=1,序号seq=y,确认号ack=x + 1表示收到了客户端传输过来的x字节数据,希望下次从x+1个字节开始传,并进入SYN-RCVD状态
要区分标志位
ACK和确认号ack
- **第三次:**客户端收到后,再给服务器发送一个确认数据包,标志位
ACK=1,序号seq=x+1,确认号ack=y+1,随后进入ESTABLISHED状态;
服务器端收到后,也进入ESTABLISHED状态,由此成功建立TCP连接,开始数据传送
- 为什么要三次握手?避免服务器等待造成资源浪费,具体原因:
如果没有最后一个数据包确认(第三次握手),
A先发出建立连接的请求数据包,由于网络原因绕远路了。A经过设定的超时时间后还未收到B的确认数据包于是发出第二个建立连接的请求数据包,这次网路通畅,
B的确认数据包也很快就到达A。于是A与B开始传输数据过了一会
A第一次发出的建立连接的请求数据包到达了B,B以为是再次建立连接,所以又发出一个确认数据包。由于A已经收到了一个确认数据包,所以忽略B发来的第二个确认数据包,但是B发出确认数据包之后就要一直等待A的回复,而A永远也不会回复由此造成服务器资源浪费,这种情况多了
B计算机可能就停止响应了
**7、**构建并发送HTTP请求
- 建立TCP连接后,浏览器发送http请求到服务器,请求的内容包括 请求行 请求头和请求体
- 当服务器接收到请求之后,处理完之后返回HTTP响应消息,包括,响应行,响应头和响应体
- 服务器响应之后,HTTP默认开启长连接,页面关闭后,TCP连接经过四次挥手断开
**8、**服务器端处理请求
**9、**客户端处理响应,检查服务器响应报文状态码
301/302表示服务器已更换域名需要重定向,网络进程会从响应头的Location字段里面读取重定向的地址,发起新的HTTP/HTTPS请求,跳回第4步200,检查Content-Type,值为text/html说明是HTML文档,是application/octet-stream说明是文件下载
**10、**请求结束,当通用首部字段Conection不是Keep-Alive时,即不为TCP长连接时,四次挥手断开TCP连接
四次挥手步骤(抽象派)
- 主动方:我已经关闭了向你那边的主动通道了,只能被动接收了
- 被动方:收到通道关闭的信息
- 被动方:那我也告诉你,我这边向你的主动通道也关闭了
- 主动方:最后收到数据,之后双方无法通信
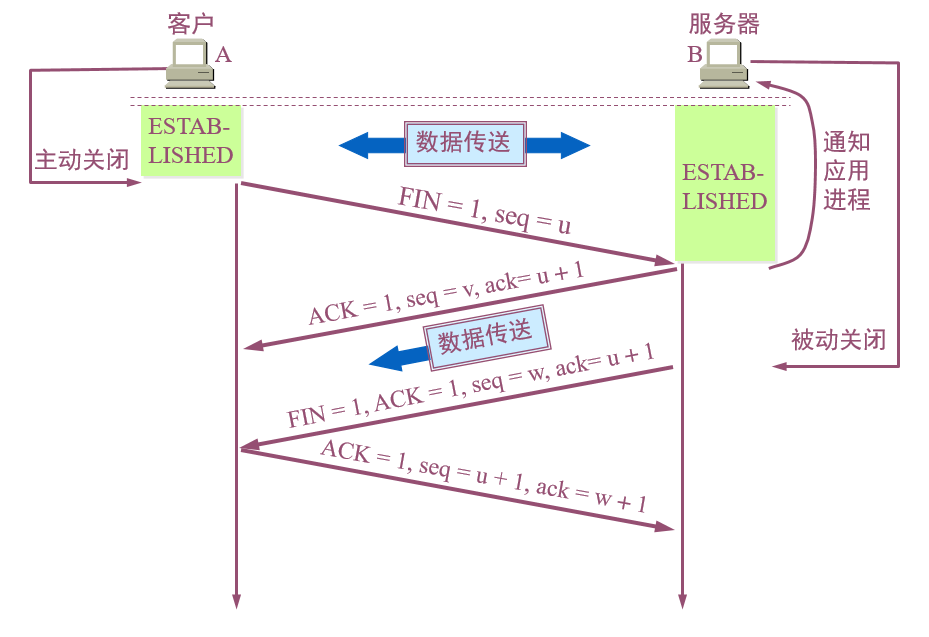
- **第一次:**客户端(主动断开连接)发送数据包给服务器,标志位
FIN=1,序号位seq=u,停止发送数据 - **第二次:**服务器收到数据包后,由于还需传输数据,无法立即关闭连接,先返回标志位
ACK=1,序号seq=v,确认号ack=u+1的数据包 - **第三次:**服务器准备好断开连接后,返回数据包,标志位
FIN=1,ACK=1,序号seq=w,确认号ack=u+1 - **第四次:**客户端收到数据包后,返回标志位
ACK=1,序号seq=u+1,确认号ack=w+1的数据包
由此通过四次挥手断开TCP连接
详细过程参见:https://www.cnblogs.com/AhuntSun-blog/p/12028636.html
为什么要四次挥手?
服务器不能马上断开连接,导致FIN释放连接报文与ACK确认接收报文需要分两次传输,即第二次和第三次"挥手"
# 3. 准备渲染进程
**11、**准备渲染进程:浏览器进程检查当前url是否与之前打开了渲染进程的页面的根域名相同,如果相同,则复用原来的进程,如果不同,则开启新的渲染进程
# 4. 提交文档
**12、**提交文档:
- 渲染进程准备好后,浏览器向渲染进程发起“提交文档”的消息,渲染进程接收到消息后与网络进程建立传输数据的“管道”
- 渲染进程接收完数据后,向浏览器发送“确认提交”
- 浏览器进程接收到确认消息后更新浏览器界面状态:安全状态、地址栏
url、前进后退的历史状态、更新web页面
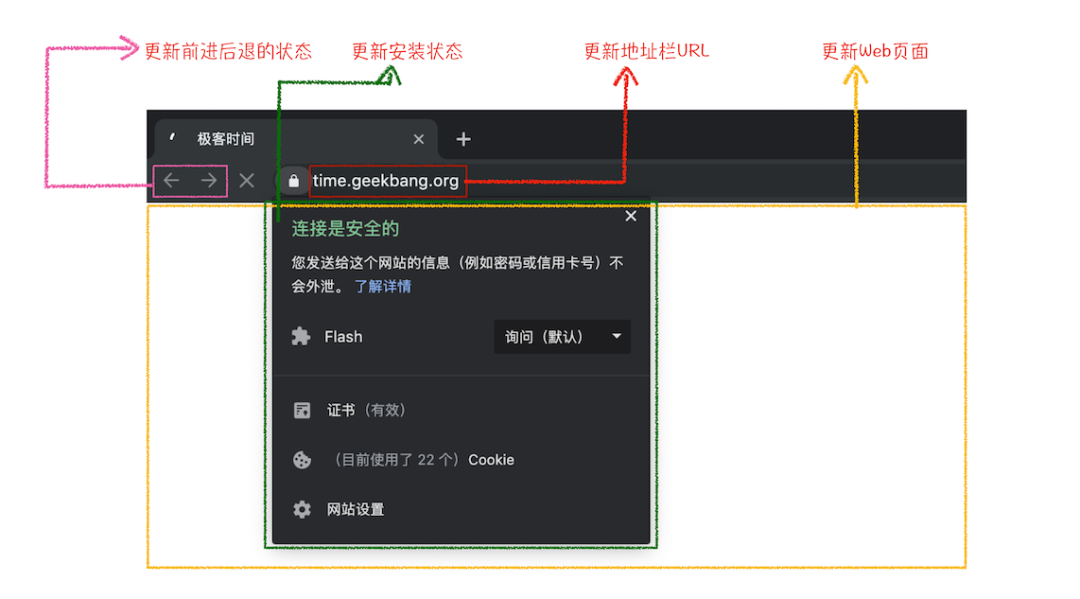
# 🅱️ 渲染阶段
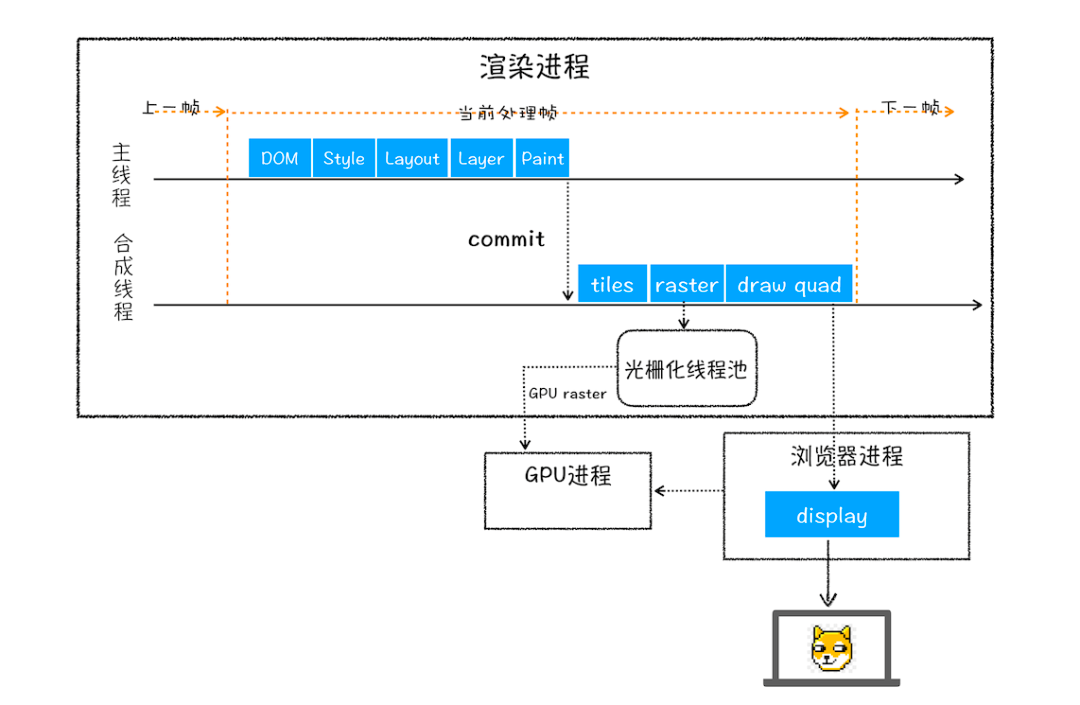
渲染步骤:
- 渲染进程解析HTML文本,解析
HTML同时,如果遇到内联样式,下载并构建样式规则(stytle rules)。遇到 JS 脚本下载并执行,构建dom树 - 构建
DOM过程若遇到外联样式/脚本声明,暂停文档解析,开始下载样式脚本和文件 - 样式文件下载完成后构建
CSSDOM;脚本文件下载完成后,解析并执行,继续解析文档构建DOM - 文档解析完成后,合成布局树(Layout/reflow),负责各元素尺寸、位置的计算
- 绘制render树(paint),绘制页面像素信息
- 渲染进程对布局树分层,分别栅格化每一层得到合成帧
- 渲染进程将合成帧发送给GPU将各层合成(composite)显示
渲染阶段通过渲染流水线在渲染进程的主线程和合成线程配合下,完成页面渲染;
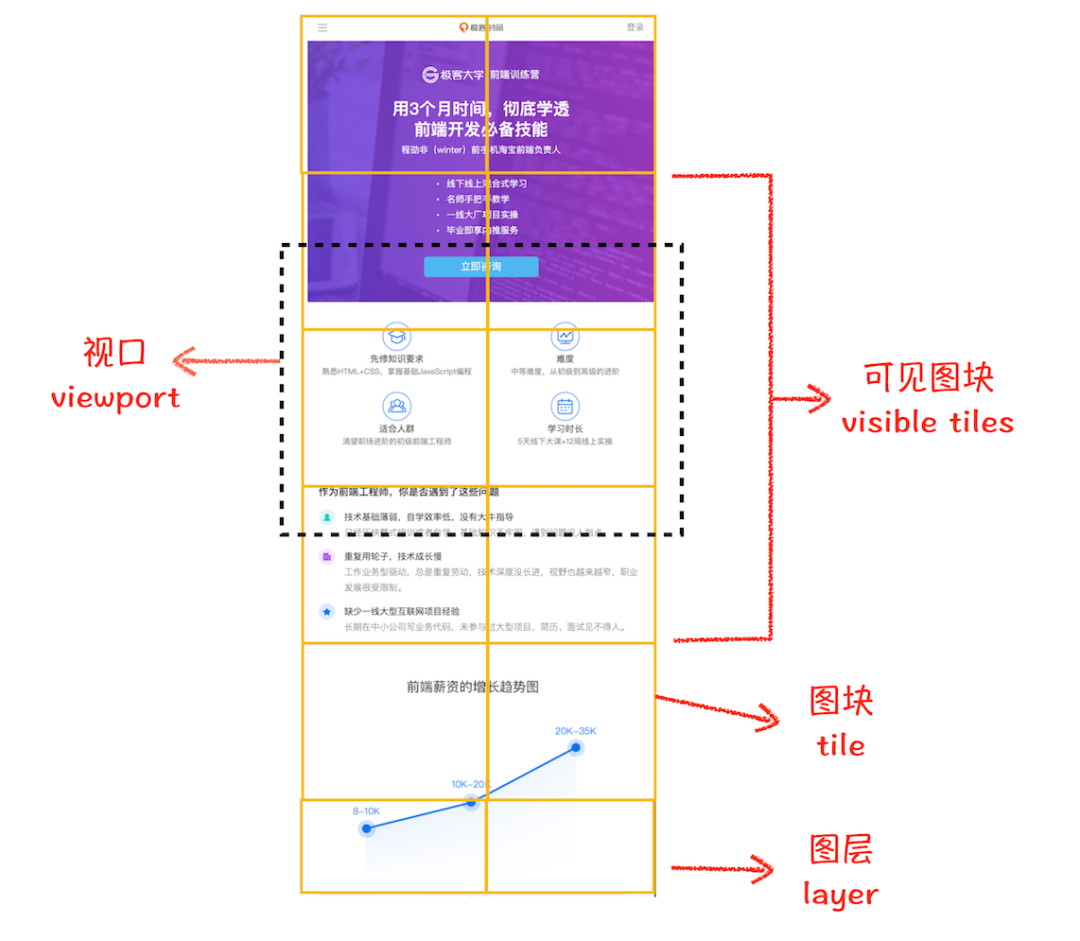
tiles 瓷砖,小瓦片
raster 光栅

③渲染进程

# 5. 构建DOM树
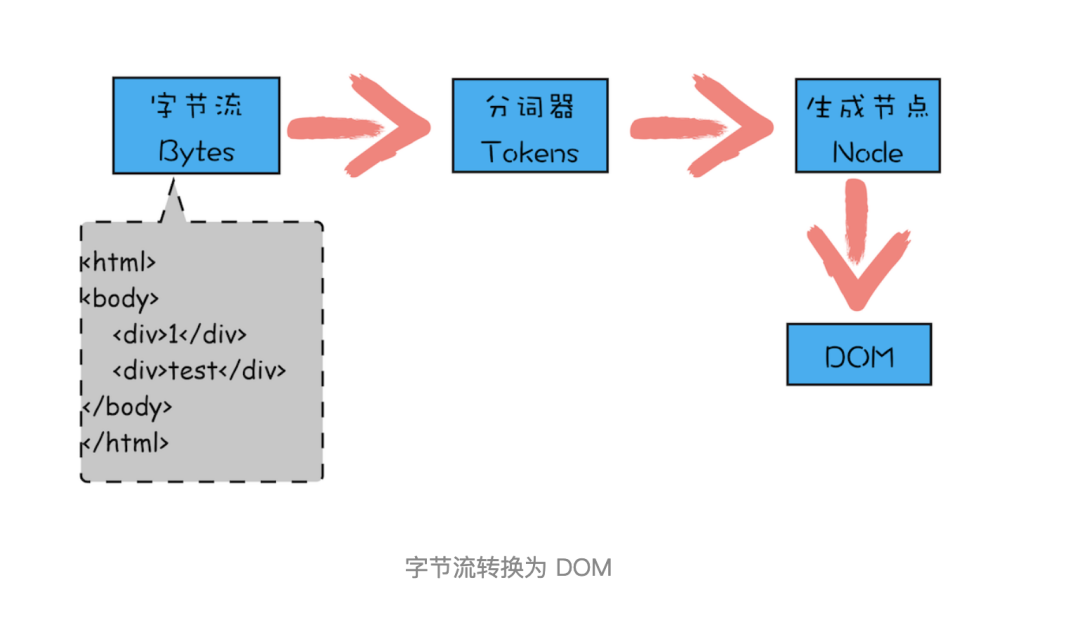
13、将请求回来的数据解压,HTML解析器HTML字节流通过分词器拆分为一个个Token,生成节点Node,最后解析成浏览器识别的DOM树结构[解析HTML,生成DOM树]
- 重点过程
- Conversion:浏览器将获得的HTML内容(Bytes)转换为单个字符
- Tokenizing分词:浏览器按照HTML规范标准将这些字符转换为不同的标记token。每个token都有自己独特的含义以及规则集
- Lexing词法分析:分词的结果是得到一堆token,把他们转换为对象,分别定义属性和规则
- DOM构建:HTML标记定义的是不同标签之间的关系,这个关系像树形结构。例如:body对象的父节点是HTML对象,p对象的父节点就是body对象
- 最后DOM树
Console选项打开控制台输入document查看DOM树
渲染引擎有一个安全检查模块叫
XSSAuditor,检测词法安全。在分词器解析出来Token之后,它会检测这些模块是否安全,比如是否引用了外部脚本,是否符合CSP规范,是否存在跨站点请求等。如果出现不符合规范的内容,XSSAuditor会对该脚本或者下载任务进行拦截
首次解析HTML时渲染进程开启一个预解析线程,遇到HTML文档中内嵌的JS和CSS外部引用会同步提前下载这些文件,下载时间以最后下载完的文件为准
# 6. 构建CSSOM
14、CSS解析器将CSS转换为浏览器能识别的styleSheets——CSSOM:通过控制台输入document.styleSheets查看
考虑一下阻塞的问题,JS有修改CSS和HTML的能力,所以需要先等到 CSS 文件下载完成并生成 CSSOM,再执行 JS 脚本,最后继续构建 DOM。由于这种阻塞,导致了解析白屏[解析CSS, 生成CSSOM]
优化:
- 移除JS/css的文件下载:通过内联 JS/ CSS
- 尽量减少文件大小:如通过 webpack 等工具移除不必要注释,压缩 JS 文件
- 将不进行DOM操作/CSS样式修改的 JS 标记上 sync/ defer异步引入
- 使用媒体查询属性:将大CSS文件拆分成多个用途的 CSS 文件,在特定的场景下会加载特定的 CSS 文件
通过浏览器调试工具的Network面板中的DOMContentLoaded查看最后生成DOM树所需的时间

# 7. 样式计算
**15、**转换样式表中的属性值,标准化。如将em转换为px,color转换为rgb
**16、**计算DOM树中每个节点具体样式,遵循CSS的继承和层叠规则
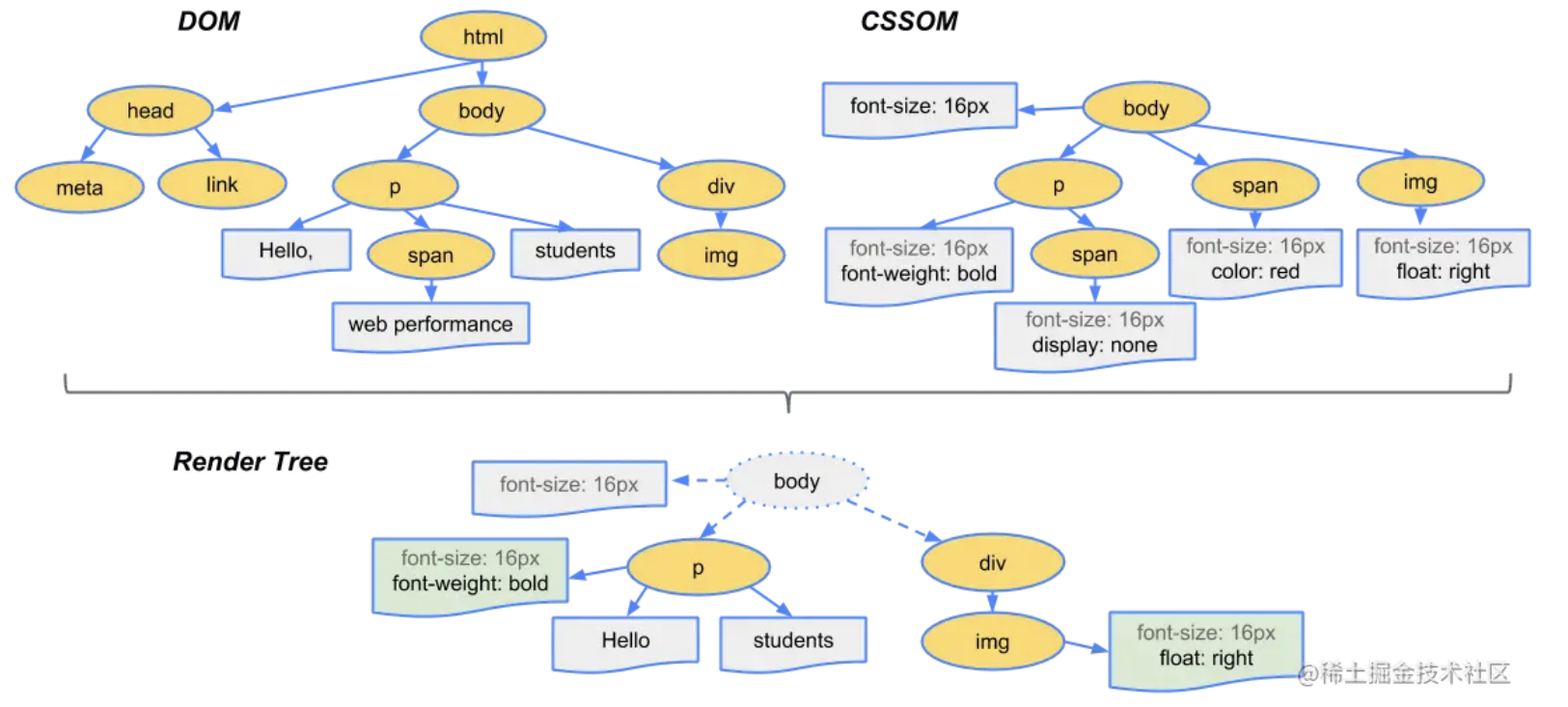
# 8. 布局阶段
[结合DOM和CSSOM树,生成渲染树]
**17、**创建布局树,遍历DOM树中所有节点,去掉所有隐藏的节点(比如head,添加了display:none的节点),保留可见的节点
**18、**计算布局树中节点的坐标位置(较复杂,这里不展开),对于每个可见的节点,找到CSSOM树中对应规则并应用,根据每个可见节点及其对应的样式,生成渲染树
# 9. 分层
**19、**对布局树分层,生成分层树(Layer Tree),通过Chrome调试工具的Layer查看。分层树中每一个节点都直接/间接的属于一个图层
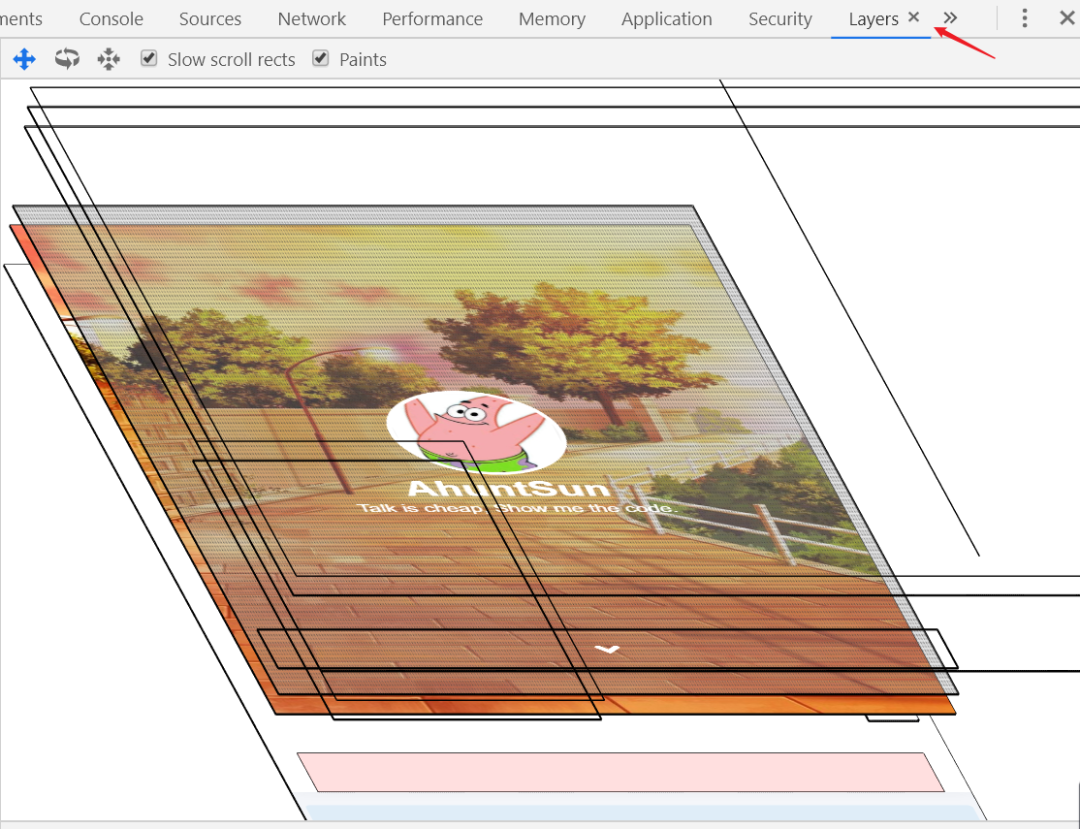
# 图层
可把普通文档流看成一个图层。特定属性可以生成一个新的图层。不同的图层渲染互不影响,对于某些频繁需要渲染的建议单独生成一个新图层,提高性能
以下几个常用属性可以生成新图层
- 3D 变换:
translate3d、translateZ will-changevideo、iframe- 动画实现的
opacity转换 position: fixed
页面分层后,会加大重绘开销??不会
使用GPU硬件加速的操作都由GPU进程负责??我觉得 是的!
# 10. 图层绘制
**20、**为每个图层生成绘制列表(即绘制指令),将其提交到合成线程。以上操作都是在渲染进程中主线程中进行,提交到合成线程后就不阻塞主线程了
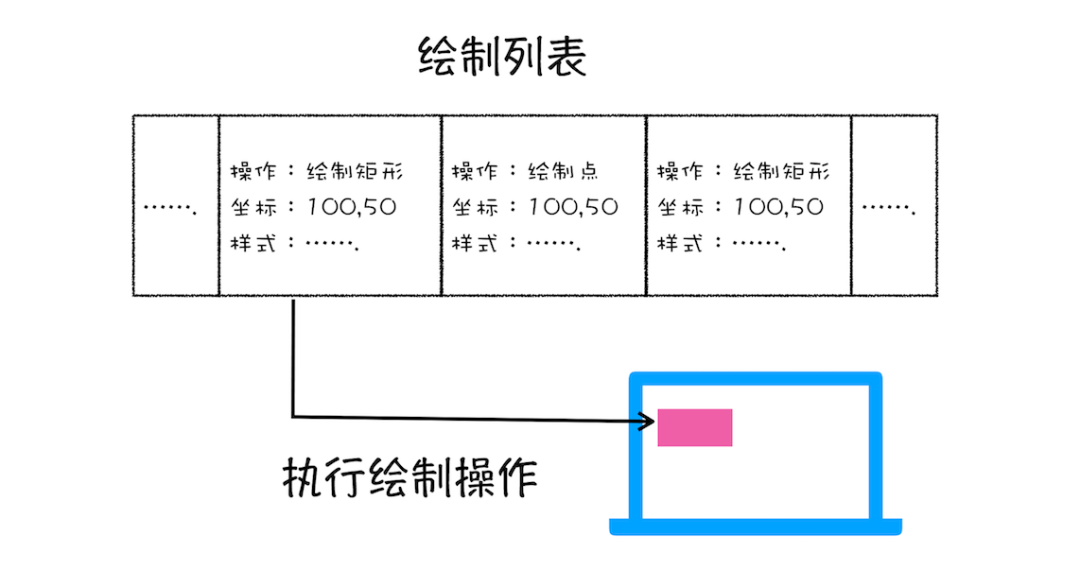
渲染进程中的合成线程部分
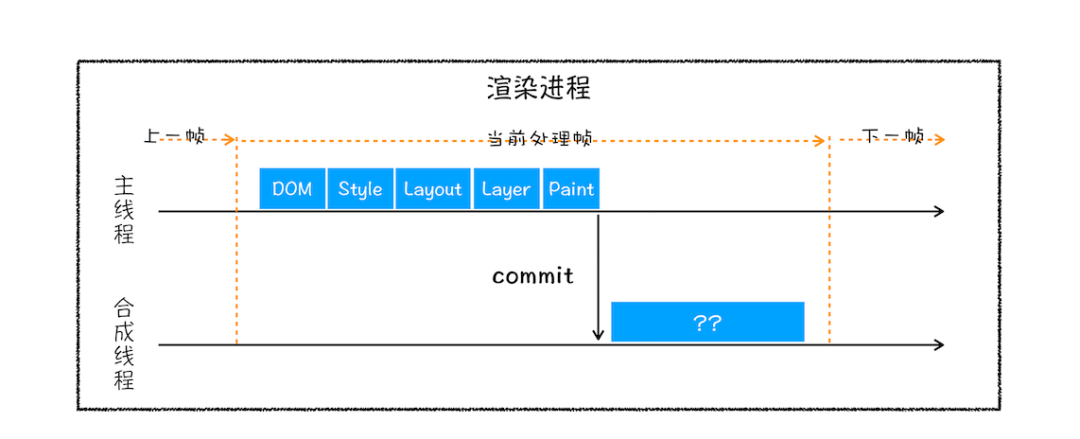
# 11. 切分图块
**21、**合成线程将图层切分成大小固定的图块(256x256或者512x512)优先绘制靠近视口的图块,可加速页面显示速度
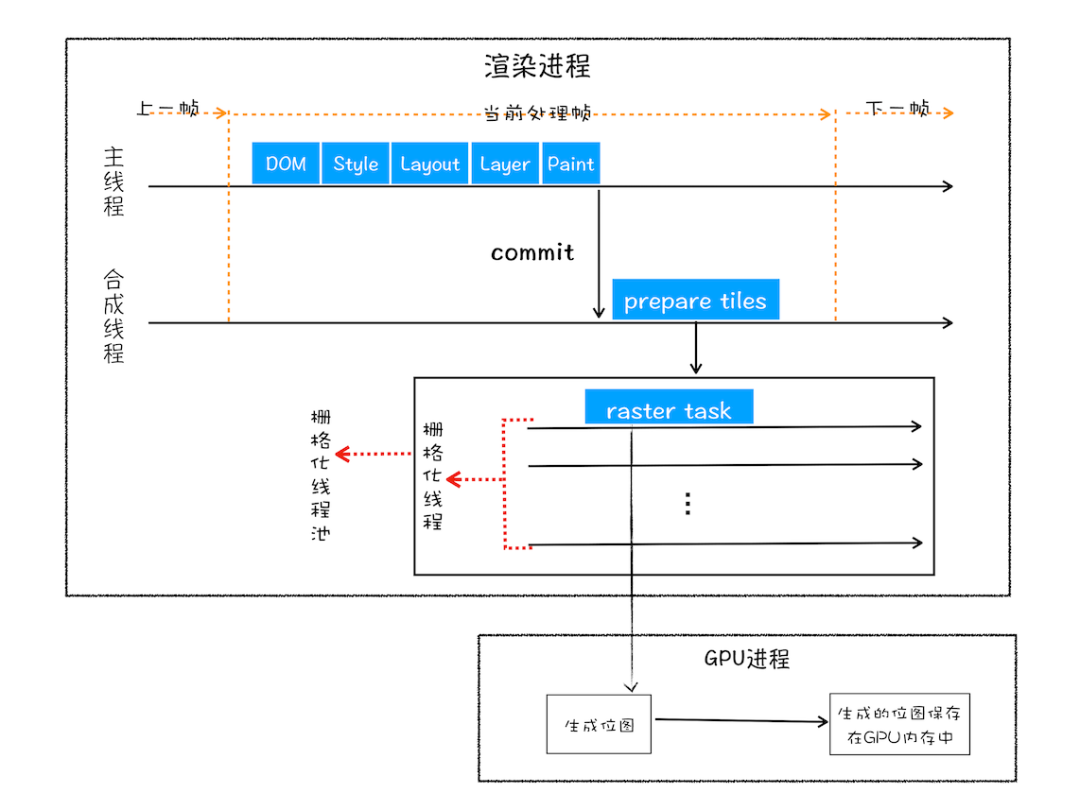
# ④GPU进程
# 12. 栅格化
22、在光栅化线程池中将图块转换成位图,通常这个过程会使用GPU加速生成,使用GPU生成位图的过程叫快速栅格化/GPU栅格化,生成的位图保存在GPU内存中
# ⑤浏览器主进程
# 13. 合成与显示
**23、**合成:一旦所有图块都被光栅化,合成线程将它们合成为一张图片,生成绘制图块的命令——“DrawQuad”,将该命令提交给浏览器进程
注意:合成过程在渲染进程的合成线程中完成,不影响渲染进程的主线程
**24、**显示:浏览器进程里面有一个叫viz的组件,接收合成线程发过来的DrawQuad命令,根据DrawQuad命令,将其页面内容绘制到内存中,最后将内存显示在屏幕上。将像素发送给GPU,展示在页面上(GPU将多个合成层合并成一个层,展示)
到这里,经过这一系列的阶段,编写好的HTML、CSS、JS等文件,经过浏览器就会显示出漂亮的页面了
Layout回流 [重排]:通过 JS 或者 CSS 修改元素几何位置属性,会触发重新布局,解析后面一系列子阶段
重绘:跳过布局阶段,直接进入绘制,然后分块、生成位图及以后子阶段;Painting 根据渲染树及回流得到的几何信息,得到节点的绝对像素
合成:渲染引擎跳过布局和绘制阶段,执行的后续操作,发生在合成线程,非主线程
# 🔥合成线程处理事件
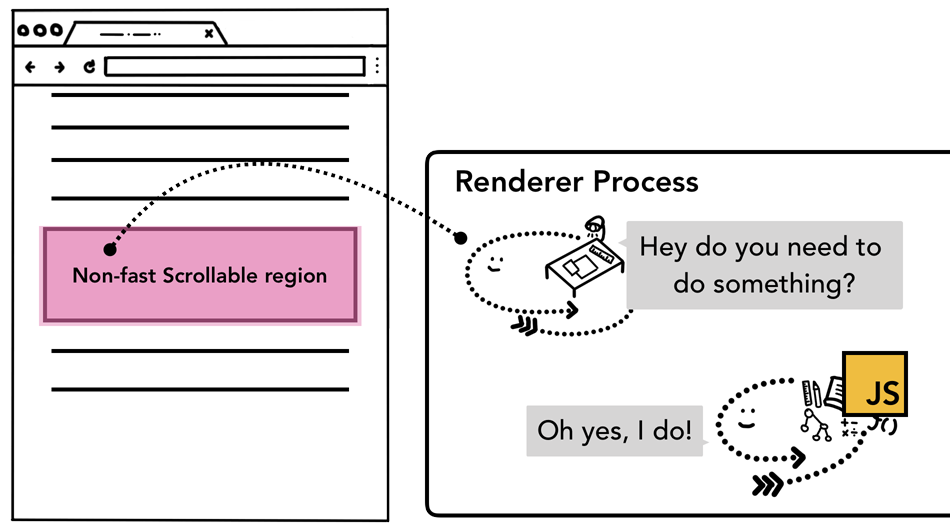
合成线程合成不同光栅层优化性能,若页面不监听事件,合成线程可完全独立于 主线程生成新的合成帧。但若监听了事件呢?
标记"慢滚动区域"
当页面被合成线程合成过,合成线程会标记哪些区域有事件,当事件发生在响应区域时,合成线程将事件发送给主线程处理,若在 非事件监听区域,则 渲染进程直接创建新的帧 不关心主线程
事件监听时标记
利用事件代理冒泡,在目标元素的上层元素中监听事件
document.body.addEventListener('touchstart',event=>{
if(event.target===area){
event.preventDefault()
}
});
2
3
4
5
确实 可以更高效监听事件
but,从浏览器角度看,此时 整个页面都会标记为 "慢滚动区域",意味着 虽然页面部分元素不需要事件监听,但 合成线程 依然在每次交互发生后等待主线程处理事件,弱化了合成线程的优化效果
解决
事件代理时传入 passive:true,告诉 渲染进程,依然需要将事件发送给主线程,但无需等待
document.body.addEventListener('touchstart',event=>{
if(event.target===area){
event.preventDefault()
}
},{passive:true});
2
3
4
5
passive 改善滚屏性能
# 前端缓存
前端缓存 主要分为http缓存和浏览器缓存
HTTP缓存:强缓存、协商缓存
浏览器缓存:storage 前端数据库和应用缓存
应用缓存主要通过manifest文件注册被缓存的静态资源,已被废弃,因为设计有些不合理,缓存静态文件的同时,默认缓存html文件。导致页面更新只能通过manifest文件中的版本号决定。所以,应用缓存只适合那种常年不变化的静态网站
优点
- 减少不必要网络传输,节约带宽(省钱)
- 降低客户端获取资源的延迟,读取缓存速度快,地理位置可能比源服务器更近
- 更快加载页面(加速)
- 减少 服务器 负载(减载)
缺点
- 占内存
# HTTP缓存
能用cache-control就不用expires
etag不是last-modified的完全替代方案,而是last-modified的补充方案,项目中使用etag还是last-modified取决于业务场景
2
HTTP控制缓存的字段主要包括Cache-Control/Expires,Last-Modified/Etag
本地强缓存过期了,就需要协商缓存,去看服务器上的资源改没有
# 强缓存
客户端请求后,先访问缓存数据库看缓存是否存在。存在则直接返回;不存在则请求真的服务器,响应后再写入缓存数据库
服务器与浏览器约定文件过期时间,向browser缓存查找请求结果,根据该结果的缓存规则决定是否使用该结果
- 强制缓存失效,发送请求(和第一次请求一样)200
- 存在缓存结果和标识但结果已失效,使用协商缓存
- 存在缓存结果和标识且未失效,直接返回结果,在 size 项中标识的是 200 from disk cache
发送请求,服务器把缓存规则放入HTTP响应报文的HTTP头中和请求结果一起返回给浏览器, 控制强制缓存的字段是Expires(HTTP1.0时期使用)
Cache-Control(HTTP/1.1 使用)
Cache-Control优先级比Expires高
# Expires(HTTP/1.0)
响应头,时间戳,控制网页缓存,**服务器返回请求结果缓存的到期时间,**再次发起该请求时,如果客户端的时间小于Expires的值, 直接使用HTTP本地缓存并返回200
缺点: Expires控制缓存的原理是使用客户端的时间与服务端返回时间做对比,如果客户端与服务端的时间因为某些原因(例如时区不同;客户端和服务端有一方的时间不准确)发生误差,强制缓存直接失效,这样的话强制缓存 毫无意义
# Cache-Control(HTTP/1.1)
响应头和请求头
没有采用具体的过期时间节点的方式,而是采用过期时长控制缓存,对应缓存为max-age
在HTTP/1.1中,Cache-Control是最重要的规则,服务端参数为:
public:都可以被缓存
private:只有客户端可以缓存,默认
no-cache:协商缓存验证
no-store:更狠,不使用任何缓存
max-age=x :缓存内容将在xxx秒后失效,单位是 s!!!
must-revalidate:一旦资源过期,在成功向原始服务器验证之前,不能使用
no-cache和no-store存在时 忽略max-age!
public和private ——决定资源是否可以在 代理服务器 缓存
Cache-Control实现流程:
- 浏览器第一次访问服务器资源时,服务器在response头部加上
Cache-Control, Cache-Control 设置 过期时间大小 - 浏览器再次访问服务器资源时,先通过请求资源的时间与cache-control中设置的过期时间对比,计算该资源是否过期,若没有则使用该缓存,否则重新请求
- 服务器再次收到请求后,更新
Response头部的Cache-Control
优先级:Cache-Control>Expires
# 协商缓存
与服务端协商之后,通过 协商结果 判断是否使用本地缓存,通过服务端告知客户端是否可以使用缓存——协商缓存
强制缓存失效后,browser携带缓存标识tag 发请求,由服务器根据缓存tag决定是否使用缓存
tag分为2组字段(不是两个):Last-Modified和ETag
# Last-Modified(HTTP/1.0)
Last-Modified(响应头),If-Modified-Since(请求头)
文件在服务端的最后修改时间
判断请求资源是否最新,浏览器第一次发送请求后,服务器会在响应头中加入这个字段
browser接收后,若再次请求,在请求头中携带If-Modified-Since字段,询问该时间之后,资源是否有被修改过,其实就是第一次访问服务器返回的Last-Modified的值
服务器拿到请求头中If-Modified-Since和该资源最后修改时间对比:
若请求头中这个值小于修改时间,说明应该更新了。返回新的资源,状态码为200
否则返回304,直接使用缓存
# ETag(HTTP/1.1)
服务器根据当前文件的内容,给文件页面生成唯一标识。通过响应头传送给浏览器,下次请求时,将这个值作为If-None-Match字段的内容
当第一次请求资源时,服务器返回资源的同时, Response 头部加上 ETag 唯一标识,这个唯一标识根据当前请求资源生成
当 再次请求访问服务器中的该资源,先检查强制缓存是否过期,如果没过期,直接使用本地缓存;如果过期,在 Request 头部加上 If-None-Match 字段,该字段是 ETag 唯一标识
服务器再次收到请求后,根据请求中的 If-None-Match 值与当前请求的资源生成的唯一标识比较:
- 值相等,返回 304 Not Modified,不会返回资源
- 不相等,则返回 200 状态码和资源,并在 Response 头部加上新的 ETag
如果浏览器收到 304 的响应状态码,从本地缓存中加载资源,否则更新资源??协商缓存 资源缓存在本地还是服务器??
# 强ETag
不论实体发生多么细微的变化都会改变其值,生成的哈希码深入每个字节,保证文件内容绝对不变
耗计算量
# 弱ETag
只用于提示资源是否相同。只有资源发生了根本改变,产生差异时才会改变
准确率不高
# 两者对比
如果 HTTP 响应头部同时有 Etag 和 Last-Modified 字段的时候, Etag 的优先级更高,先判断 Etag 是否变化,如果 Etag 没有变化,再看 Last-Modified
- 精确度**:ETag>Last_Modified**
- 编辑了资源文件,但内容没改变,造成缓存失效
- Last_Modified可感知的时间单位是s,若在1s内修改了文件,不能体现出来
- 性能上:Last_Modified优于Etag
有哈希值的文件设置 强缓存
没有哈希值(index.html)设置协商缓存
2
# 缓存存储
- 内存缓存:快速读取和实效性
- 硬盘缓存:写入硬盘文件,需要I/O操作,读取复杂,速度慢
浏览器中的缓存位置,按优先级从高到低排列:
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
都没命中的话,就发请求
大的JS 、CSS文件直接丢进磁盘,反之丢进内存
内存使用率高时,文件优先进入磁盘
# Service Worker
是web worker的一个类型
# Memory Cache
内存中的缓存,主要包含 当前中页面中已经抓取到的资源,例如已经下载的样式、脚本、图片等。读取内存中的数据肯定比磁盘快,内存缓存读取高效,可是缓存持续性很短 一旦关闭Tab页面,内存中的缓存也就被释放了
计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存不多
# Disk Cache
Disk Cache 存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上
在所有缓存中,它的覆盖面基本最大。它会根据HTTP Header中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需重新请求,而且即使在跨站点时,相同地址的资源一旦被硬盘缓存,就不会再请求
# Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在Chrome浏览器中只有5分钟左右,同时它也并非严格执行HTTP头中的缓存指令
- 所有的资源都能被推送,并且能够被缓存
- 可以推送
no-cache和no-store的资源 - 一旦连接被关闭,
Push Cache就被释放 - 多个页面可以使用同一个
HTTP/2的连接,也就可以使用同一个Push Cache。主要依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的tab标签使用同一个HTTP连接 Push Cache中的缓存只能被使用一次- 浏览器可以拒绝接受已经存在的资源推送
- 可以给其他域名推送资源
# 啥资源强/协商缓存?
- HTML:协商缓存
- CSS、JS、图片:强缓存,文件命名带上hash值
考虑缓存的内容:
- css文件
- js文件
- logo、图标
- html
- 可下载的内容
不应该缓存的内容:
- 业务敏感的 GET 请求
网站的缓存设置最佳实践——入口 html 文件 Cache-Control 设置 no-cache,其他文件 max-age,这样入口文件会用本地缓存但每次都协商,能及时更新,而其他资源不会发请求,减少服务端压力
如果要更新的话,html 文件协商后发现有更新会下载新 html,关联了其他 hash 的文件,浏览器会下载新的,不会走到之前文件的缓存
强制刷新的实现——设置了 Cache-Control 为 no-cache
清空缓存并强制刷新的功能,是清掉本地的强缓存再去协商,能保证一定是拿到最新的资源
# ⚠️前端安全
# XSS
跨站脚本攻击
Cross Site Scripting ,和 CSS 区别,CSS 是层叠样式表 (Cascading Style Sheets)
用户输入/向代码中注入JS,暗地执行脚本
- 写死循环
- 监听用户行为,窃取用户信息(cookie、token)
- 诱骗用户 点击/填写 表单
- 绘制UI(例如 弹窗)
# 存储型
stored xss
危害最大,对所有用户可见
XSS代码发送到数据库,前端请求数据时,将XSS代码发送到前端
场景:留言区提交一段脚本执行,若前后端未做好转义的工作,评论内容存在数据库,页面渲染过程中直接执行,相当于执行一段未知逻辑的JS代码
如论坛发帖、商品评论、用户私信等
- 1、攻击者网页回帖,帖子中包含JS脚本
- 2、回帖提交服务器后,存储至数据库
- 3、其他网友查看帖子,后台查询该帖子的回帖内容,构建完整网页,返回浏览器
- 4、该网友浏览器渲染返回的网页,中招!
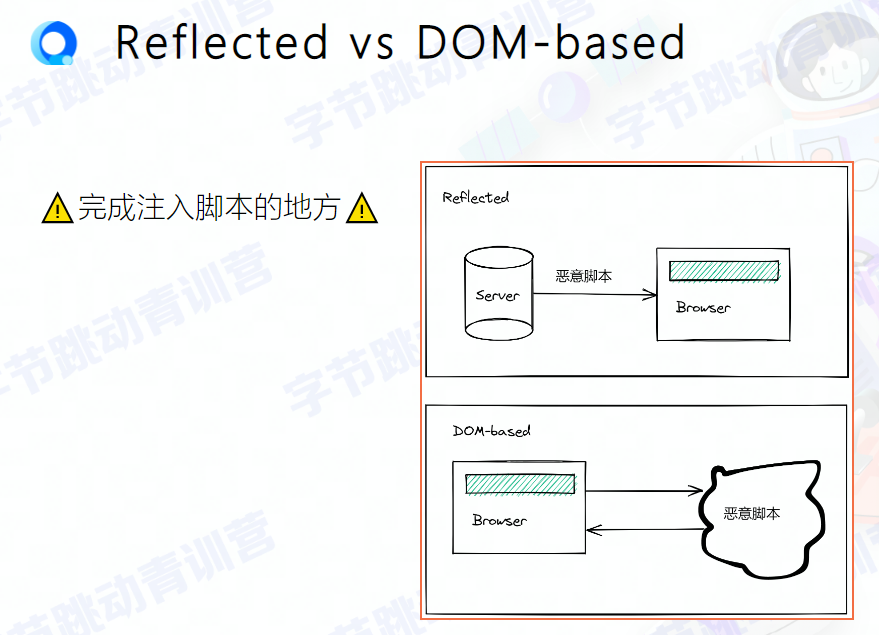
# 反射型
reflected xss
不涉及 数据库,将JS代码作为请求参数放置URL中,诱导用户点击
恶意脚本通过作为网络请求的参数,经过服务器,反射到HTML文档中执行解析,服务器不会存储这些恶意脚本
反射型 XSS 漏洞常见于通过 URL 传递参数的功能,如网站搜索、跳转等
- 用户点击后, JS作为 参数传给 后端
- 后端 没有检查过滤,简单处理后放入网页正文中返回给浏览器
- 浏览器解析返回的网页,中招!
# 文档型
DOM-based - xss
- 不需要 服务器 参与
- 恶意攻击的 发起+执行,全在浏览器 完成
XSS攻击作为中间人,劫持到网络数据包,修改里面的HTML
劫持包括:
- WIFI路由劫持
- 本地恶意软件
DOM 型 XSS 跟前两种 XSS 的区别:DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JS 自身安全漏洞,而其他两种 XSS 都属于服务端安全漏洞
# 突变型
mutation-based xss
- 利用 浏览器渲染 DOM 的特性
- 不同 浏览器 有区别
# 防范:一个信念,两个利用
# 1.对输入转码过滤
- 如果允许 用户上传 DOM,需要对 string 转义
- 上传 svg,需要扫描,因为 svg 标签中可能插入 脚本
- 尽量不做用户自定义跳转的行为,如果要的话,需要做好过滤,否则可能 会传递 JS代码
- 如果允许用户自定义样式的话(url 或 背景图片),可能导致xss攻击(非常巧妙)
# 2.利用CSP
Content Security Policy
浏览器内容安全策略

- 限制其他域下的资源加载
- 禁止向其它域提交数据
- 提供上报机制
# 3.HttpOnly
阻止JS对cookie的访问(标记或授权对话)
阻止 XSS 攻击:服务器对脚本进行过滤或转码,利用 CSP 策略
!!不能阻挡CSRF!!
# CSRF
也叫 XSRF
跨站伪造请求(钓鱼)
Cross-Site Request Forgery
打开A网站的情况 ,另开Tab 打开恶意网站B,此时在B页面的“唆使”下,浏览器发起 对网站A的 请求
1、这个 请求不是用户主动 ,而是B“唆使的”,如 危害较大的请求操作(发邮件?删数据?等等)那就麻烦了
2、因为 A网站已经打开了,浏览器存有A 的Cookie , 被“唆使”的请求 自动带上这些信息,A网站后端分不清楚这是否是用户真实的意愿
在用户不知情 的情况下
利用用户 权限
构造指定 HTTP 请求,窃取或修改 用户敏感信息
CSRF 蠕虫
CSRF 蠕虫指的是产生蠕虫效果,会将CSRF攻击一传十 十传百,当一个用户访问恶意页面后通过 CSRF 获取其好友列表信息,再利用私信好友的CSRF 漏洞给每个好友发送一条指向恶意页面的信息,只要有人查看信息链接,CSRF 蠕虫会不断传播!
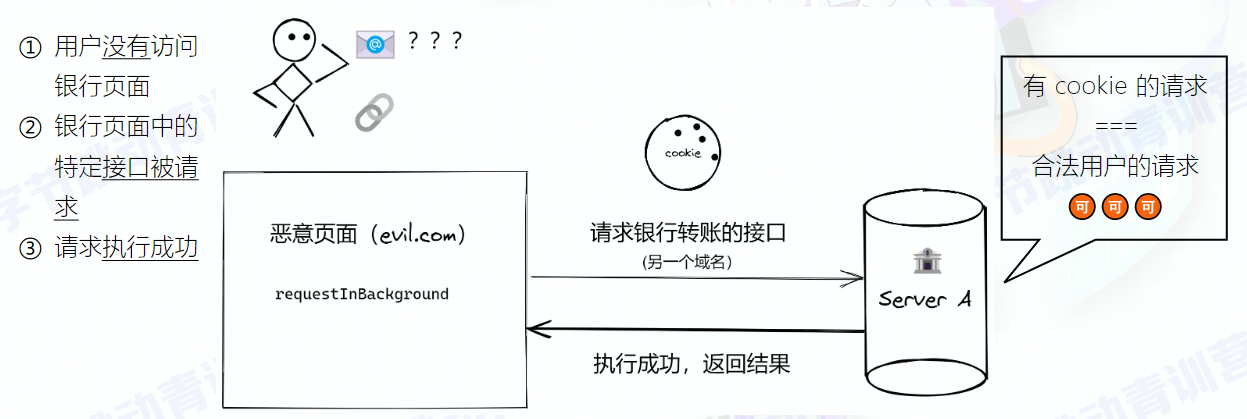
攻击者诱导受害者进入第三方网站,向被攻击网站发送跨站请求。利用受害者已经获取的注册凭证(如cookie) ,绕过后台验证,冒充用户对被攻击的网站执行某项操作
利用所在网站的目前登录信息,悄悄提交各种信息,比XSS更恶劣
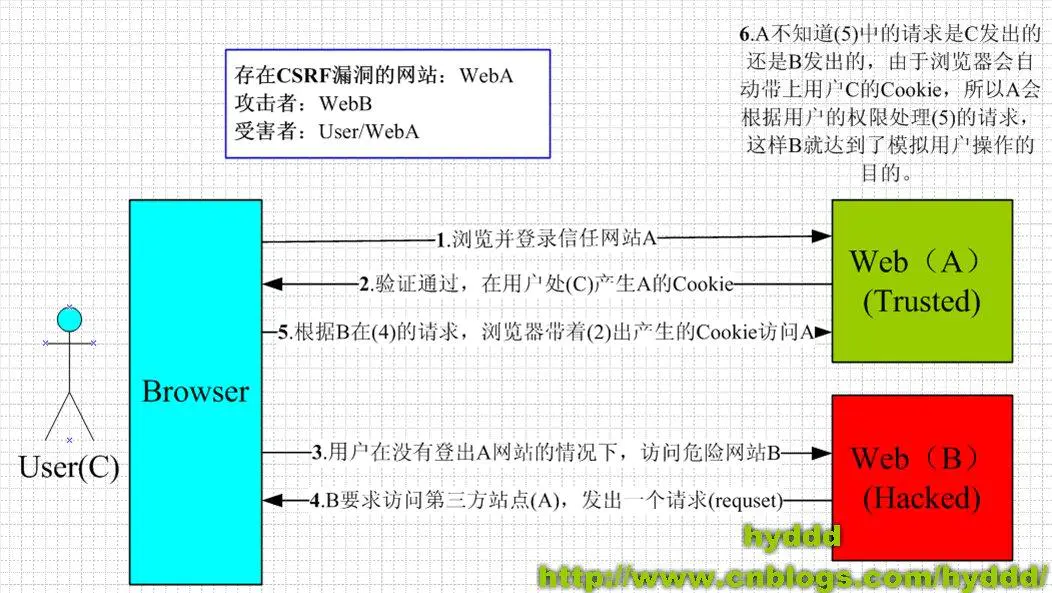
本质:利用cookie会在同源请求中携带发送给服务器的特点,冒充用户
点击链接后,可能发生
- 自动发送GET请求。利用src发送请求
- 自动发送POST请求
- 诱导点击发送GET请求
# 防范

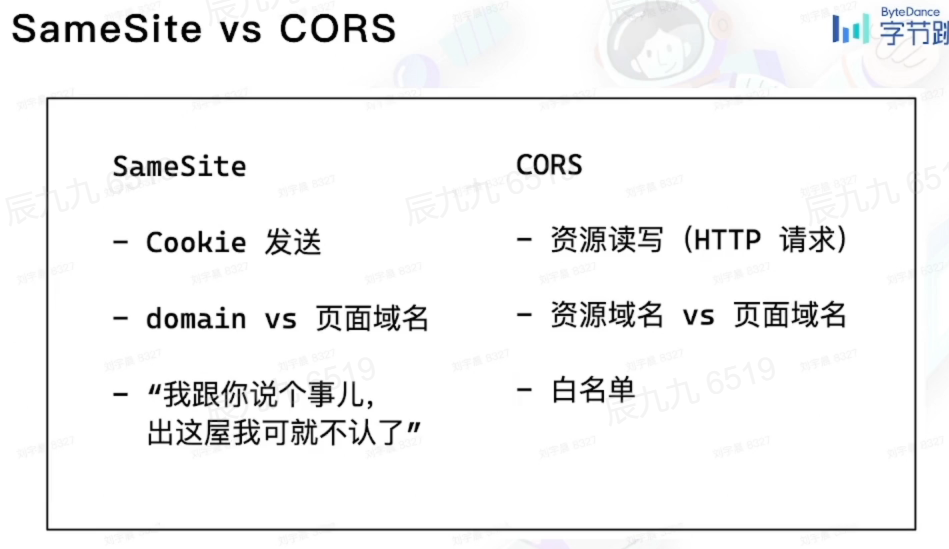
# 1.SameSite
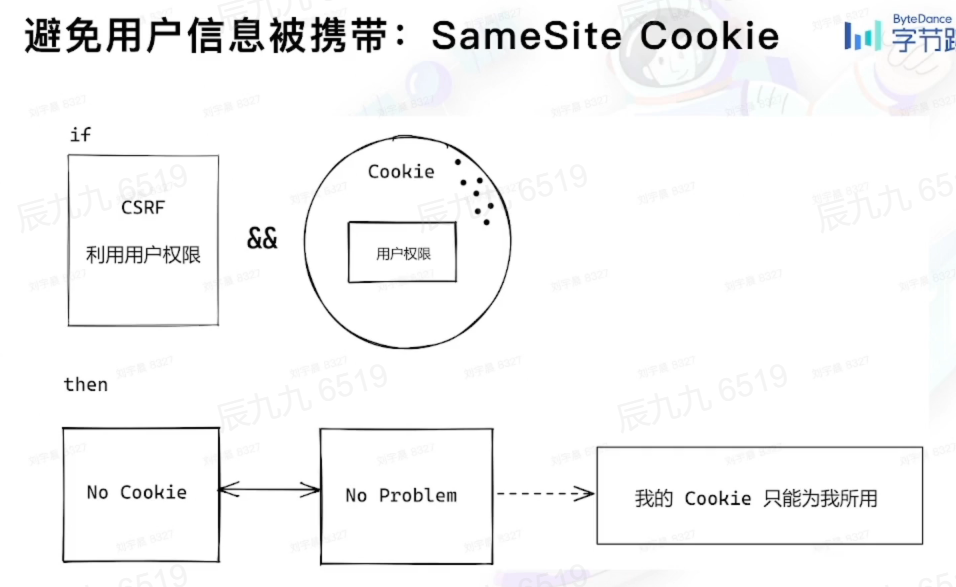
根源上解决 CSRF 攻击
SameSite 限制domain属性和 当前域名 是否匹配
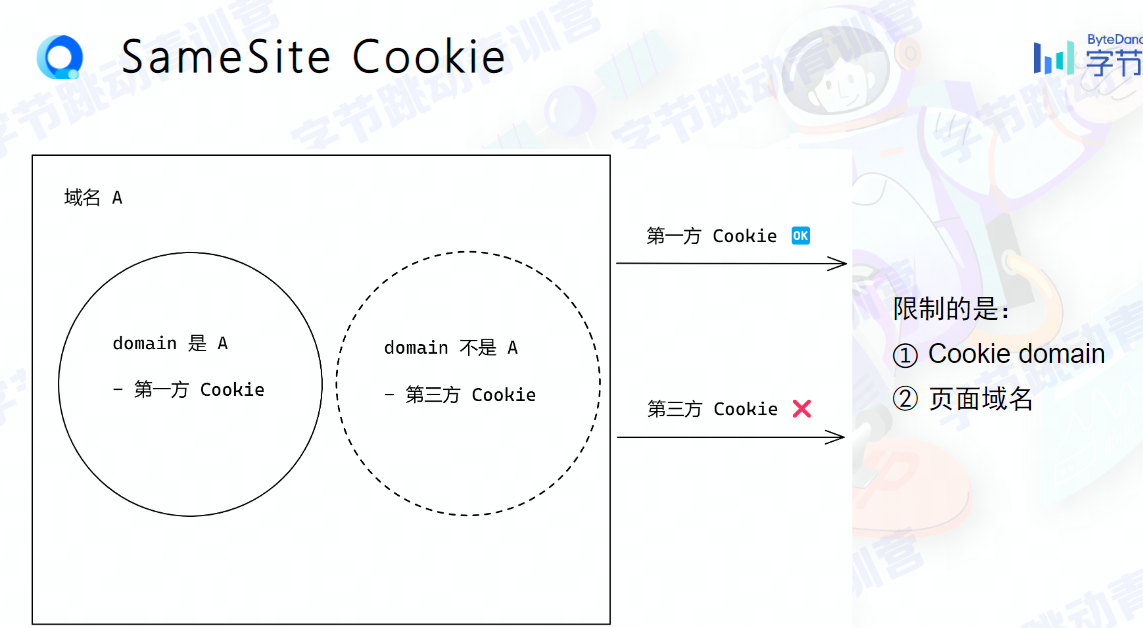
SameSite属性取值
Strict,仅允许同站请求携带 Cookie
Lax,宽松一点,允许部分第三方请求携带 Cookie
None,最宽松,默认模式,无论是否跨站都会发送 Cookie
Set-Cookie: name=lizheming; SameSite=None; Secure
浏览器针对HTTPS域名才支持SameSite=None,所以我们还需要携带 Secure 属性
SameSite和SameOrigin不同,同域判断 更严格,Cookie中的同站判断比较宽松,主要根据Mozilla维护的公共后缀表(Pulic Suffix List (opens new window))使用 有效顶级域名 effective top-level domains (eTLD) +1 的规则查找得到的一级域名是否相同 来判断是否 是同站请求
例如 .org 是在 PSL 中是有效顶级域名,imnerd.org 则是一级域名。所以 https://blog.imnerd.org 和 https://www.imnerd.org 是同站域名。
而 .github.io 也是有效顶级域名,所以 https://lizheming.github.io 和 https://blog.github.io 得到的一级域名不一样,他们两个是跨域请求
在类似 GitHub/GitLab Pages,Vercel 这种提供子域名给用户建站的第三方服务中,eTLD的同站判断非常有用,通过将原本是一级域 的域名 添加到 eTLD 列表中,让浏览器认为配有用户名 的完整域名才是一级域名,有效解决了 不同用户站点的 cookie 共享问题
eTLD 是有效顶级域名,和 Top-Level Domain顶级域名有区别。eTLD记录在 PST中,TLD记录在RZD(Root Zone Database——根区域数据库),RZD记录了所有的 跟域 列表
eTLD 主要为了解决 .com.cn,,com.hk,这种看起来像是 一级域名 但其实是 作为顶级域名 存在的场景
Schemeful Same Site 同站计划
# 2.验证来源站点
请求头中的origin和referer
referer表明请求来源于哪个地址
origin只包含域名信息,referer包含具体的URL路径
我们可以拒绝一切非本站发出的请求
简单,但是当网站域名有多个,或经常 变换域名时 会非常麻烦,具有 局限性
# 3.Token

利用token(后端生成的一个唯一登陆态,传给前端保存)每次前端请求都会带token,检验通过才同意请求
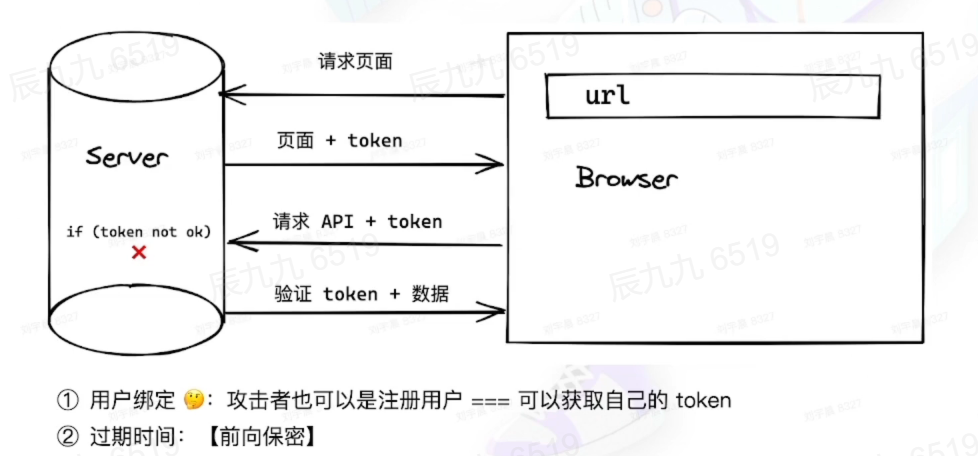
token 必须和具体用户绑定,才能确保不会被其他注册用户利用
token必须设置有效时间,保不齐哪天token被窃取,已请求的数据会被攻击者利用
为什么 token可以防止 csrf?
Token被用户端放在Cookie中(不设置HttpOnly),同源页面每次发请求都在请求头或者参数中加入Cookie中读取的Token来完成验证。 CSRF只能通过浏览器自己带上Cookie,不能操作Cookie来获取到Token并加到http请求的参数中
# 4.安全框架
如Spring Security
# SQL注入
将恶意的 Sql查询/添加语句插入到应用 输入参数 ,让服务器执行攻击者期望的SQL语句,得到数据库数据/对数据库 读取、修改、删除、插入
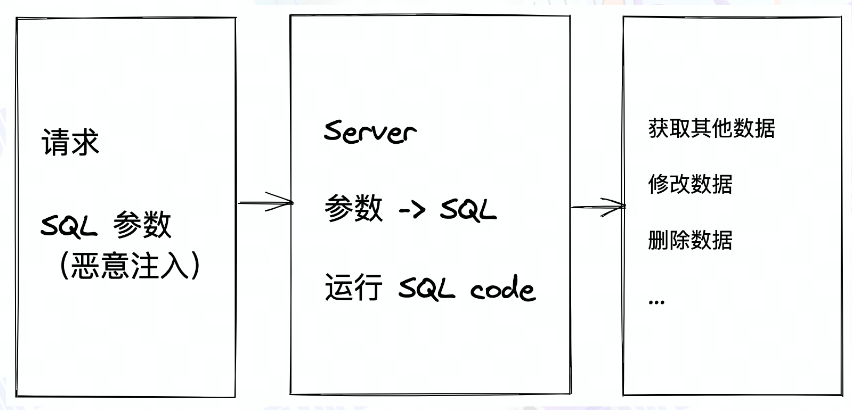
如何让Web服务器执行攻击者的SQL语句?
将有毒的SQL语句放置于Form表单/请求参数中,提交到 服务器,如果 服务器没有做输入安全检查,直接将变量取出执行SQL语句, 中招
预防方式 :
- 严格检查输入变量 类型和格式
- 过滤/转义特殊字符
- 对访问数据库的应用程序采用Web应用防火墙

# iframe 攻击
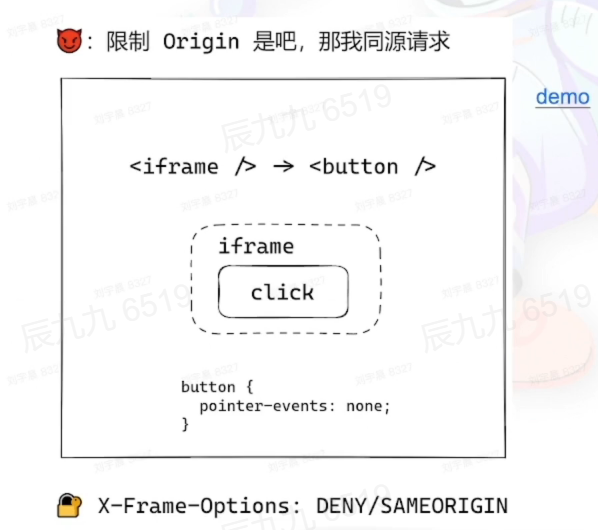
iframe是同源请求
# GET!==GET+POST
请求一定要区分开
还有其他种类的攻击,这里不再细说

# DDos
Distributed Denial of Service:分布式拒绝服务攻击。是拒绝服务攻击的升级版。 让服务不可用。常用 攻击对外提供服务的服务器
- Web服务
- 邮件服务
- DNS服务
- 即时通讯服务
攻击者不断 请求,让合法用户 请求无法及时处理——DoS 攻击
攻击者使用多台计算机/计算机集群进行 DoS 攻击—— DDoS 攻击
早期 , DoS攻击是 很容易的事情:一台性能强劲的计算机,写个程序多线程不断 请求,服务器应接不暇,最终无法处理正常 请求,对别的正常用户来说, 网站貌似无法访问,拒绝服务就是这 个意思
现在 服务器早已不是一台服务器 , www.baidu.com的域名,背后是数不清的CDN节点,数不清的Web服务器
这种情况 想靠单台计算机 试图让 网络服务满载,无异于鸡蛋碰石头
分布式技术 可 提供高可用的服务,也能 被攻击方用来进行大规模杀伤性攻击。攻击者不再局限于单台计算机的攻击能力,转而通过成规模的网络集群发起拒绝服务攻击

# DNS劫持
Web服务发展 如火如荼, 离不开 默默无闻的域名解析系统
DNS 将域名转换成IP , 早期协议 设计 没有太多考虑其安全性,对于查询方来说:
- 我去请求的真的是一个DNS服务器吗?是不是别人冒充的?
- 查询的结果有没有被人篡改过?这个IP真是这个网站的吗?
DNS 没有机制 保证能回答这些问题,因此DNS劫持 泛滥,用户在地址栏输入域名的那一刻起,一路上的凶险防不胜防:
- 本地计算机中的木马修改hosts文件
- 本地计算机中的木马修改DNS数据包中的应答
- 网络中的节点(如路由器)修改DNS数据包中的应答
- 网络中的节点(如运营商)修改DNS数据包中的应答
后来,以阿里、腾讯等头部互联网厂推出httpDNS服务,釜底抽薪,原来DNS天差地别,通过这项技术让DNS变成 在http协议之上的一个应用服务
# 其他攻击
- JSON 劫持
轻量级的数据交换格式,而劫持就是对数据 窃取(或者应该称为打劫、拦截比较合适。恶意攻击者通过 特定的手段,将本应该返回的 JSON数据 拦截,转而 发送 给恶意攻击者 。一般 劫持的JSON数据都是包含敏感信息或者有价值的数据
- 暴力破解
一般针对密码,弱密码(Weak Password)很容易被猜到或被破解
解决方案 密码复杂度要足够大,也要足够隐蔽 限制尝试次数
- HTTP 报头追踪漏洞
HTTP/1.1 规范定义了 HTTP TRACE 方法,主要是用于客户端通过向 Web 服务器提交 TRACE 请求来进行测试或获得诊断信息。
当 Web 服务器启用 TRACE 时,提交的请求头会在服务器响应的内容(Body)中完整的返回,其中 HTTP 头很可能包括 Session Token、Cookies 或其它认证信息。攻击者可以利用此漏洞来欺骗合法用户并得到他们的私人信息
解决:禁用 HTTP TRACE
- 信息泄露
Web 服务器或应用程序没有正确处理一些特殊请求,泄露 Web 服务器的一些敏感信息,如用户名、密码、源代码、服务器信息、配置信息等
所以需注意:
应用程序报错时,不对外产生调试信息 过滤用户提交的数据与特殊字符 保证源代码、服务器配置的安全
- 目录遍历漏洞
攻击者向 服务器发请求,在 URL 中或在有特殊意义的目录中附加 ../、或者附加 ../ 的一些变形(如 .. 或 ..// 甚至其编码),导致攻击者能够访问未授权的目录,以及在 Web 服务器的根目录以外执行命令
- 命令执行漏洞
通过 URL 发起请求,在 Web 服务器端执行未授权的命令,获取系统信息、篡改系统配置、控制整个系统、使系统瘫痪
- 文件上传漏洞
如果对文件上传路径变量过滤不严, 且对用户上传的文件后缀以及文件类型限制不严,攻击者可通过 Web 访问的目录上传任意文件,包括网站后门文件(webshell),进而远程控制网站服务器
所以 需注意:
需严格限制和校验上传的文件,禁止上传恶意代码的文件 限制相关目录的执行权限,防范 webshell 攻击
- 其他漏洞
SSLStrip 攻击
OpenSSL Heartbleed 安全漏洞
CCS 注入漏洞
证书有效性验证漏洞
- 业务漏洞
跟具体的应用程序相关,比如参数篡改(连续编号 ID / 订单、1 元支付)、重放攻击(伪装支付)、权限控制(越权操作)
- 框架或应用漏洞
WordPress 4.7 / 4.7.1:REST API 内容注入漏洞
Drupal Module RESTWS 7.x:Remote PHP Code Execution
SugarCRM 6.5.23:REST PHP Object Injection Exploit
Apache Struts:REST Plugin With Dynamic Method Invocation Remote Code Execution
Oracle GlassFish Server:REST CSRF
QQ Browser 9.6:API 权限控制问题导致泄露隐私模式
Hacking Docker:Registry API 未授权访问
# WebSocket
# 含义
在单个TCP连接上进行全双工通信的协议
使客户端和服务器间数据交换更简单,允许server主动向client推送data
# 特点
- 建立在TCP协议之上
- 良好兼容性。默认端口80和443,握手阶段采用http协议,所以握手时不容易屏蔽,能通过各种HTTP代理服务器
- 数据格式轻量,性能开销小,通信高效
- 二进制和文本均可发送
- 无同源限制
- 协议标识符是ws,网址是url
# 为啥用它?
WebSocket出现前,创建一个和server双通道通信的web应用,需要依赖HTTP协议,不停轮询,导致
server维持来自每个客户端大量的不同连接
大量轮询造成高开销,带上多余header,无用的数据传输
# WebSocket、HTTP
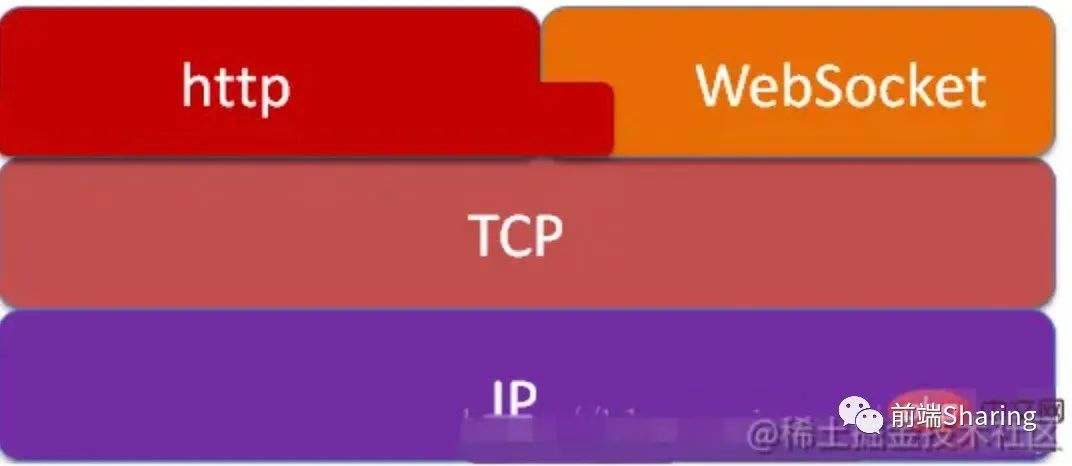
- 都基于HTTP,可靠,应用层协议
- WebSocket建立握手时,data通过HTTP传输。建立之后,真正传输不需要HTTP协议
不同
- WebSocket双向通信,HTTP单向
- HTTP/2具备server推送功能,但HTTP/2只能推送静态资源,无法推送指定信息
优点
- WebSocket一旦被创建,互相沟通所消耗的请求头很小
- server可向client推送消息
# 🌈 cookie、session
实现了HTTP的状态管理,跟踪browser用户身份的会话方式,Cookie在客户端,Session在服务端
# cookie
HTTP是无状态协议,服务器管理全部客户端状态会成为负担
Cookie——一小段文本信息。客户端请求服务器,如果服务器需要记录该用户状态,向客户端浏览器颁发一个Cookie客户端把
Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交。服务器检查该Cookie,辨认用户状态
Cookie根据从服务器端发送的响应报文内的一个叫做Set-Cookie的首部字段信息, 通知客户端保存Cookie。当下次客户端再往该服务器发送请求时, 客户端会自动在请求报文中加入Cookie值后发送出去服务器端发现客户端发送过来的
Cookie后, 检查是从哪一个客户端发来的连接请求, 对比服务器上的记录,得到之前的状态信息
- 用户能操作cookie,性能缺陷,不管域名下地址是否需要cookie,请求都会携带上完整的cookie
- 每次访问都要送cookie给server,浪费宽带
- path 可限制路径
- 存在浏览器端
- cookie很多都是4K大小,受浏览器限制
- cookie当浏览器关闭就消亡,累计计时,从创建时就开始计时
- 容易被截取篡改
# 多域名拆分
- 在移动端,如果请求的域名数过多,会降低请求速度
- 一种优化方案:
dns-prefetch(让浏览器空闲时提前解析dns域名,勿滥用)
# session
Session另一种记录客户状态的机制,存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上浏览器再次访问只需从该
Session中查找该客户的状态就可以
- session存在服务器端,可存储任何类型数据
- session理论上受内存限制
- 占用server内存,服务器内存压力大
- 依赖cookie,若禁用cookie,需要使用URL重写,不安全
- 导致代码不好维护(过度使用session)
- session声明周期是间隔的,没有访问session就被销毁
sessionId的携带方式
- cookie
- URL重写:因为cookie可以人为禁用,常采取的技术就是URL重写,将sessionID附加在URL的后面. 附加的方式有两种,一种是作为URL路径的附加,另一种是作为 query 字符串附加在URL后面
- 隐藏表单
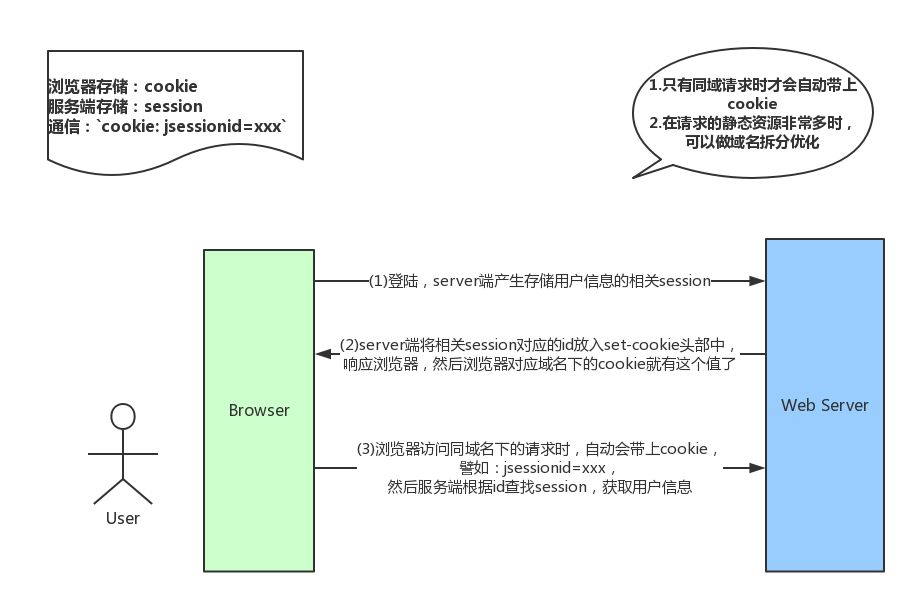
# 工作流程
- 登录时,用户提交的表单,放入HTTP请求报文
- 服务器验证信息,正确则存在数据库中,key为sessionID
- 服务器返回的响应报文的Set-Cookie首部字段包含这个SessionId,客户端收到后将Cookie存进浏览器
- 客户端之后对同一个服务器请求时会包含该Cookie,服务器收到后提取出SessionId,读取用户信息
# 关系
Cookie和Session非常相似,Cookie相当于客户端持有的通行证,Session相当于服务器上的通行名册
服务器第一次接收到请求时,开辟一块 Session 空间,同时生成一个 session id ,通过响应头的Set-Cookie:JSESSIONID=XXXXXXX ,向客户端发送要求设置 Cookie 的响应;客户端收到响应后,在本机客户端设置了一个JSESSIONID=XXXXXXX的 Cookie 信息,该 Cookie 的过期时间为浏览器会话结束
接下来客户端每次向同一个网站发送请求时,请求头都会带上该 Cookie信息(包含 sessionId ), 然后服务器通过读取请求头中的 Cookie 信息,获取名称为 SESSIONID 的值
# 区别
- 存放位置:
Cookie在客户端,Session在服务器端 - 安全性(隐私策略):
Cookie对客户端可见;Session存储在服务器端。使用Cookie需要对其加密 - 有效期:设置
Cookie很大的过期时间,Cookie保存很长时间;服务器会定期清理超时Session ID避免出现过大压力;但Session依赖于类似Session ID这样的Cookie,而Cookie对Session ID过期时间默许为-1。只要关闭浏览器,Session就失效 - 对服务器造成的压力:
Session保存在服务器端,每个用户都产生Session,并发访问多会产生十分多的Sssion,耗费内存;Cookie保存在客户端,不占用服务器资源 - 存取值的类型:Cookie只支持字符串数据,session可以存任意数据类型
- 存储大小:**cookie保存的数据不超过4K,**session可存储高于cookie,但访问量过多会导致占用过多资源
# 服务器咋知道session过期?
request.getSession(boolean),若为true,如果当前会话不可用,创建新的会话,若存在就返回当前会话。若参数是false,在request当前会话不存在时返回null
# 应用
# cookie
关闭浏览器消失
- 会话状态管理(判断是否登录过网站,购物车,游戏分数等)
- 保存上次登录信息
- 保存上次查看页面
- 个性化设置
- 浏览器行为跟踪
为什么cookie内存容量小?4KB
- 可能造成页面卡顿
- 传送给服务器压力大
# session
- 保存用户专用信息在server,sessionId唯一标志符
- 购物车
- 登录信息
- 数据放在session,同一用户不同页面使用
- 防止用户非法登录
# 🍉 Webstorage
克服cookie带来的限制,不需要持续将数据返回server
- 提供cookie之外的存储会话数据的路径
- 跨网站/应用 检测用户的行为而不需要服务端脚本和数据库
- 拥有在用户即使突然断网的情况下可以保存部分web应用的能力,不会因为网络连接问题受影响
- 和cookie一样存在跨域策略
# 分类
# localStorage
(针对同一个域名)
特点:
- 生命周期:持久化本地存储,除非手动删除数据,否则数据永远不过期
- 存储的信息在同一域中共享
- 大小***:5M***,和浏览器厂商有关
- 本质上是对字符串的读取,若存储内容过多会消耗内存空间,导致页面卡顿
- 受同源策略限制
缺点就是
1.无法像cookie设置过期时间
2.只能存字符串
设置过期时间:
自定义方法实现,存数据时把当前时间记录,获取数据时判断当前时间和之前时间差是否在指定过期时间范围内,若过期则清楚数据
localStorage存储达到上限,如何继续存数据?
- 滚动存储
- 跨域存储
localStorage的key占内存!!
# sessionStorage
和localStorage相似,唯一不同是生命周期,一旦页面关闭,sessionStorage将会删除数据
sessionstorage会被覆盖吗??
# 相同点
- 存储大小:一般是5MB
- 存储位置:都存在客户端
- 存储内容类型:只能存储字符串类型
- 获取方式:window.localStorage
- 应用:localStorage用于长期登录,适合长期保存在本地的数据。sessionStorage用于敏感账号一次性登录
- 接口封装
# 优点
- 存储空间大
- 节省网络流量
- 快速显示
- 安全性
- 对于那种只需要短暂存储关闭页面就可以丢弃的数据,sessionStorage很好用
# 方法
setItem(key,value) //保存
getItem(key) //获取
key() //获取键名
removeItem(key) //清除
clear() //清除所有数据
key(index) //获取索引的key
2
3
4
5
6
# IndexedDB
Indexed Database API(IndexedDB)
前端数据库有WebSql和IndexDB,其中WebSql被规范废弃,他们都有大约50MB的最大容量,可以理解为localStorage的加强版。
扩展的前端存储方式,是运行在浏览器中的非关系型数据库,理论上容量无上限
特性
- 储存量理论上没有上限
- 所有操作都是异步的,相比
LocalStorage同步操作性能更高,尤其是数据量较大时 - 原生支持储存
JS的对象 - 是个正经的数据库,意味着数据库能干的事它都能干
- 同源策略限制
- 操作繁琐
# cookie?
属性:Name、Value、Domain、Path、Expires/Max-age、Size、HttpOnly、Secure、SameSite和Priority
# set-cookie

Domain 决定cookie在哪个域有效,设置对子域生效。以"."开始。domain指定的域名可做到与结尾匹配一致
Path:Cookie的有效路径。以“/”结尾
Expires/Max-age 均为Cookie的有效期,前者若不设置则默认页面关闭时删除该cookie。后者单位为秒,若设置为0则立即失效,为负数,在页面关闭时失效。默认为-1
Secure:安全属性,true(browser只会在HTTPS和SSL等安全协议中传输cookie)
# SameSite
限制第三方cookie。可阻止跨站请求攻击
- Strict:最严格,完全禁止第三方cookie
- Lax:大多不发送第三方cookie,导航到目标网站的GET请求除外
- None:可显式关闭SameSite属性,设置为none,前提是同时设置Secure属性,否则无效。默认
Priority:优先级,当cookie过多时优先级低的cookie会被清除
# 禁止JS访问cookie
设置HttpOnly
JS Document.cookie (opens new window)API 无法访问cookie
# JS设置cookie
document.cookie 属性来创建 、读取、及删除 cookie
创建 cookie :
document.cookie="username=John Doe";
添加一个过期时间(默认cookie 在浏览器关闭时删除:
document.cookie="username=John Doe; expires=Thu, 18 Dec 2043 12:00:00 GMT";
使用 path 参数告诉浏览器 cookie 的路径。默认,cookie 属于当前页面
document.cookie="username=John Doe; expires=Thu, 18 Dec 2043 12:00:00 GMT; path=/";
读取
var x= document.cookie; //以字符串方式返回所有cookie
# cookie作用域
domain本身以及domain下的所有子域名
# 跨域访问cookie
- cookie不能跨根域,但JS可以,JS可以将cookie传给另外的域再保存一次域名cookie,这样可能存在不同的cookie域包含同一个cookie值
- browser不允许跨根域读写
- 采用SSO单点登录方式
# 没cookie有啥问题
cookie:解决 如何记录客户端用户信息 的问题。保存在本地的一部分数据,在再次发送请求时被携带并传送到服务器,通知server是否请求来自统一状态浏览器,如保持用户登录
使基于无HTTP协议记录的信息状态稳定成为可能
作用:
- 会话状态
- 个性化设置
- 浏览器行为跟踪
# 单点登录?
单点登录(Single Sign On)
SSO的——在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用
淘宝跳转到天猫为啥不重新登录?
淘宝和天猫设置了单点登录SSO,在多个系统的集群,只需一次登录,其他系统感知到用户登录,不需重新登录
淘宝和天猫 间部署 专门用作登录的服务器,相当于实现一个 中转站,这个中转站存放需要共享登录状态服务应用的session,相当钥匙,用户跳转应用时 都会来中转站看看,若session存在就直接使用钥匙打开门,否则 得先确认用户身份 制造session钥匙存在中转站再开门,用户身份存储和有效时间均由中转站说了算,统一管理
# session原理
客户端登录完成之后,服务器创建对应的 session,session 创建完之后,把 session - id 发送给客户端,客户端存储到浏览器中。这样客户端每次访问服务器时,都会带着sessionid,服务器拿到 sessionid 后,在内存找到与之对应session 这样就可正常工作了
# 🔥 浏览器同源策略
一个域的JS脚本在未经允许的情况下,不能访问另一个域的内容,同源指的 协议 域名 和 端口均相等的情况,为同一个域
# 跨域在服务端真正执行?
同源策略限制,请求发送到后端,后端返回数据时被浏览器的跨域拦截
服务端就算想拦截,也没法判断是否跨域,所有 Header 都可被篡改,它用什么判断请求是否跨域?很明显服务端心有余而力不足!
请求一定是先发出去,返回的时候被浏览器拦截了,如果请求有返回值,会被浏览器隐藏掉
options 预检请求 询问 是否允许这次请求,如果是跨域请求,可以理解为:询问 服务端是否允许请求在当前域下跨域发送
当然,还有其他作用,如 询问 服务端支持哪些 HTTP 方法
预检请求不会真正在服务端执行,但也是一个请求,考虑到服务端开销,不是所有请求都会发送预检
浏览器把请求判定为 简单请求,浏览器就不会发送预检了
所以,如果发送的是简单请求,这个请求不管是否会受到跨域限制,只要发出去了,一定会在服务端执行,浏览器只是隐藏了返回值而已
对于前端开发大部分跨域问题,都是通过代理解决
代理使用场景:
生产环境不跨域,但开发环境跨域,只需在开发环境代理解决即可——开发代理
# 目的
浏览器的保护机制,保证用户安全,防止恶意网站窃取数据
防范CSRF攻击
# 解决跨域
# JSONP
客户端准备回调——>script标签 发请求——>服务端收到请求,返回函数调用——>客户端执行回调
优势在于 支持 老式浏览器,向不支持cors的网站请求
前后端配合,只支持GET。利用src发送请求,传递回调
不受跨域限制:script,link,img,href,src,因为这些操作不出现安全问题
为啥只能用get?
jsonp就是创建一个script标签插入到body中,后端执行回调,前端接收数据
因为根本没有设置请求格式的余地
http就是这样规定的
1、
// 动态的加载JS文件
function addScript(src) {
const script = document.createElement('script');
script.src = src;
script.type = "text/javascript";
document.body.appendChild(script);
}
addScript("http://xxx.xxx.com/xxx.js?callback=handleRes");
// 设置一个全局的callback函数来接收回调结果
function handleRes(res) {
console.log(res);
}
// 接口返回的数据格式
handleRes({a: 1, b: 2});
2
3
4
5
6
7
8
9
10
11
12
13
14
2、
const jsonp = ({ url, params, callbackName }) => {
const generateUrl = () => {
let dataSrc = ''
for (let key in params) {
if (params.hasOwnProperty(key)) {
dataSrc += `${key}=${params[key]}&`
}
}
dataSrc += `callback=${callbackName}`
return `${url}?${dataSrc}`
}
return new Promise((resolve, reject) => {
const scriptEle = document.createElement('script')
scriptEle.src = generateUrl()
document.body.appendChild(scriptEle)
window[callbackName] = data => {
resolve(data)
document.removeChild(scriptEle)
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
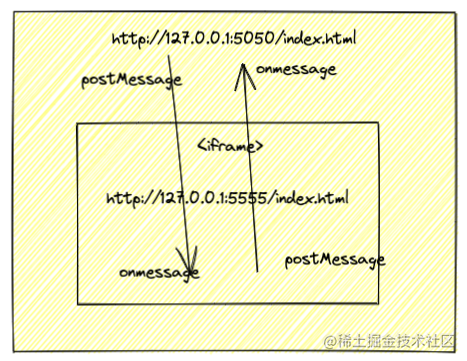
# postMessage
HTML5引入的API,实现安全跨源通信
让主页面和任意iframe/window,open打开的页面 双向通信
兼容性也好
# CORS
跨域时部分浏览器默认不携带cookie,为了携带cookie需设置xmlhttprequest的withCrendetails属性
如果不需要cookie,最好置成false,避免浏览器默认允许cookie携带
后端需要包装ACA系列header
'Access-Control-Allow-Origin' '*';
'Access-Control-Allow-Credentials' "true";
'Access-Control-Allow-Headers' 'X-Requested-With';
2
3
除此以外无需额外配置
跨域资源共享 Cross Origin Resourse-Sharing
**一般后端开启。**基于HTTP1.1的跨域解决方案
服务端设置 Access-Control-Allow-Origin 开启 CORS。 表示哪些域名可以访问资源,通配符表示所有网站都可以访问!!!!
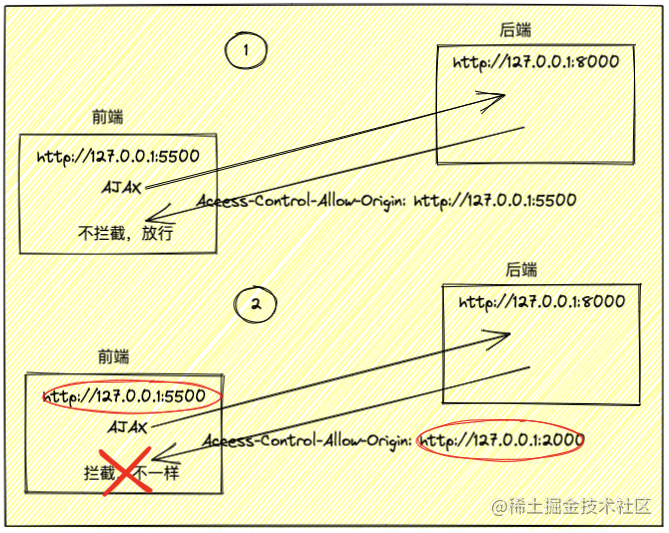
请求可附带很多信息,对服务器造成不同程度影响,有的请求只是获取,有的请求会改动数据
针对不同请求,CORS规定3种交互模式
- 简单请求
- 需要预检的请求
- 附带身份凭证的请求
# 简单请求
同时满足以下条件,是简单请求:
- 请求方法属于:
- get
- post
- head
- 请求头仅包含安全字段,常见的安全字段:
AcceptAccept-LanguageContent-LanguageContent-TypeDPRDownlinkSave-DataViewport-WidthWidth
- 请求头如果包含
Content-Type,仅限:
content-type:application/json 会触发options方法!
text/plainmultipart/form-dataapplication/x-www-form-urlencoded
为兼容表单,历史上表单一直可发出跨域请求,Ajax跨域设计是,只要表单可以发,Ajax就可以直接发
请求中任意
XMLHttpRequest均没有注册事件监听器;XMLHttpRequest可使用XMLHttpRequest.upload访问请求没有使用
ReadableStream
以上条件同时满足,为简单请求
当浏览器判定某个ajax 请求是简单请求时,发生以下的事情
- 请求头添加
Origin
GET /cors HTTP/1.1
Origin: http://api.bob.com
Host: api.alice.com
Accept-Language: en-US
Connection: keep-alive
User-Agent: Mozilla/5.0...
2
3
4
5
6
Origin告诉服务器,本次请求来自源(协议 + 域名 + 端口)。服务器根据这个值,决定是否同意请求
如果Origin指定源不在许可范围,服务器正常回应。浏览器发现,回应的头信息没有包含Access-Control-Allow-Origin,知道出错了,抛出一个错误,被XMLHttpRequest的onerror回调捕获。这种错误无法通过状态码识别,状态码可能是200
如果指定域名在许可范围,响应多出几个字段
Access-Control-Allow-Origin: http://api.bob.com
Access-Control-Allow-Credentials: true
Access-Control-Expose-Headers: FooBar
Content-Type: text/html; charset=utf-8
2
3
4
- 响应头包含
Access-Control-Allow-Origin**
必须
- *:我很开放,什么人我都允许访问
- 具体源:如
http://my.com,我就允许你访问
实际这两个值对客户端
http://my.com而言,都一样,客户端不会管其他源服务器允不允许,就关心自己是否被允许服务器也可以维护可被允许的源列表,如果Origin命中该列表,才响应具体源
为了避免后续麻烦,强烈推荐响应具体源
假设服务器做出以下响应:
HTTP/1.1 200 OK
Date: Tue, 21 Apr 2020 08:03:35 GMT
...
Access-Control-Allow-Origin: http://my.com
...
消息体中的数据
2
3
4
5
6
7
浏览器看到服务器允许自己访问后,高兴的像一个两百斤的孩子
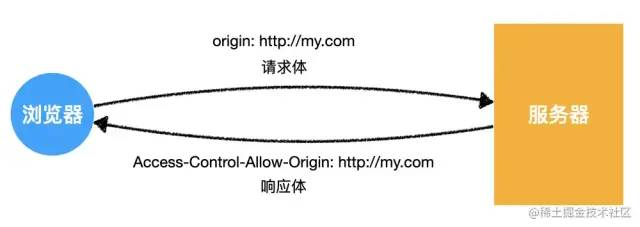
Access-Control-Allow-Credentials
可选。
是布尔值,表是否允许发送Cookie。默认Cookie不包括在CORS请求。true表示服务器明确许可,Cookie可包含在请求。
也只能设为true,如果服务器不要浏览器发送Cookie,删除该字段
Access-Control-Expose-Headers
可选。
CORS请求时,XMLHttpRequest的getResponseHeader()只能拿到6个基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma
想拿到其他字段须在Access-Control-Expose-Headers指定
Access-Control-Expose-Headers: FooBar
getResponseHeader('FooBar')可返回FooBar的值
# withCredentials
CORS请求默认不发送Cookie
如要把Cookie发到服务器,要服务器同意,指定Access-Control-Allow-Credentials
Access-Control-Allow-Credentials: true
另一方面,开发者须在AJAX请求中打开withCredentials
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
2
否则,即使服务器同意发送Cookie,浏览器也不会发送。或者,服务器要求设置Cookie,浏览器也不会处理
如果省略withCredentials,有的浏览器还是会一起发送Cookie。这时,可显式关闭withCredentials
xhr.withCredentials = false;
注意,如果要发送Cookie,Access-Control-Allow-Origin不能设为星号,必须指定明确/与请求网页一致的域名
同时,Cookie依然遵循同源政策
# 预检请求
非简单请求是对服务器有特殊要求的请求,比如请求方法是put/delete,或content-type值为 application/json
先询问服务器当前网页所在域名是否在服务器许可名单,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,才会发出正式的请求,否则报错
如果浏览器不认为是简单请求:
- 浏览器发送预检请求,询问服务器是否允许
- 服务器允许
- 浏览器发送真实请求
- 服务器完成真实的响应
比如,在页面http://my.com/index.html中有以下代码造成了跨域
// 需要预检的请求
fetch('http://crossdomain.com/api/user', {
method: 'POST', // post 请求
headers: {
// 设置请求头
a: 1,
b: 2,
'content-type': 'application/json',
},
body: JSON.stringify({ name: '袁小进', age: 18 }), // 设置请求体
});
2
3
4
5
6
7
8
9
10
11
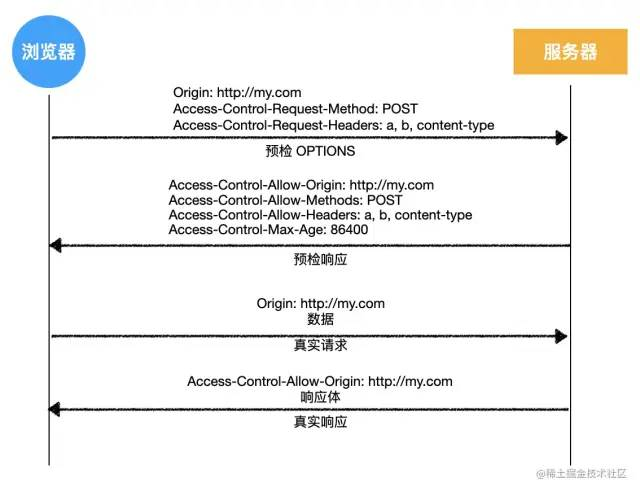
浏览器发现它不是简单请求,按照下面的流程与服务器交互
- 浏览器发送预检请求,询问服务器是否允许
OPTIONS /cors HTTP/1.1
Origin: http://api.bob.com
Access-Control-Request-Method: PUT
Access-Control-Request-Headers: X-Custom-Header
Host: api.alice.com
Accept-Language: en-US
Connection: keep-alive
User-Agent: Mozilla/5.0...
2
3
4
5
6
7
8
这并非真实请求,请求中不包含请求头,也没有消息体,这是预检请求,询问服务器,是否允许后续真实请求
预检请求没有请求体,它包含后续真实请求要做的事情
预检请求特征:
- 请求方法为
OPTIONS - 没有请求体
- 请求头包含
Origin:请求的源,和简单请求的含义一致Access-Control-Request-Method:必须,后续的真实请求使用的请求方法Access-Control-Request-Headers:逗号分隔的字符串,浏览器CORS请求额外发送的头字段,上例是X-Custom-Header
- 服务器允许
收到预检请求后,检查预检请求中信息,如果允许,则响应
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://api.bob.com
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: X-Custom-Header
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
2
3
4
5
6
7
8
9
10
11
12
预检请求,只需要在响应头添加:
Access-Control-Allow-Origin:和简单请求一样,允许的源Access-Control-Allow-Methods:允许后续真实的请求方法Access-Control-Allow-Headers:允许改动的请求头Access-Control-Max-Age:多少秒内对于同样请求源/方法/头,都不再发预检请求
- 浏览器发送真实请求
预检被服务器允许后,浏览器发送真实请求,请求数据
POST /api/user HTTP/1.1
Host: crossdomain.com
Connection: keep-alive
...
Referer: http://my.com/index.html
Origin: http://my.com
{"name": "xiaoming", "age": 18 }
2
3
4
5
6
7
8
- 服务器响应真实请求
HTTP/1.1 200 OK
Date: Tue, 21 Apr 2020 08:03:35 GMT
...
Access-Control-Allow-Origin: http://my.com
...
添加用户成功
2
3
4
5
6
7
完成预检之后,后续的处理与简单请求相同
# 附身份凭证请求
默认,ajax 跨域请求不附带 cookie,这样某些需要权限的操作就无法进行
通过简单的配置可以实现附带 cookie
// xhr
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
// fetch api
fetch(url, {
credentials: 'include',
});
2
3
4
5
6
7
8
当一个请求需要附带 cookie 时,无论它是简单请求,还是预检请求,都会在请求头中添加cookie字段
而服务器响应时,需要明确告知客户端:服务器允许这样的凭据
告知的方式非常简单,在响应头中添加:Access-Control-Allow-Credentials: true
对于一个附带身份凭证的请求,若服务器没有明确告知,浏览器仍然视为跨域被拒绝
另外:对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin 的值为*。这就是不推荐使用*的原因
额外补充
在跨域访问时,JS 只能拿到一些最基本的响应头,如:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma,如果要访问其他头,需要服务器设置本响应头
pragma 是旧产物,已被抛弃
Access-Control-Expose-Headers头让服务器把允许浏览器访问的头放入白名单,例如:
Access-Control-Expose-Headers: authorization, a, b
这样 JS 就能够访问指定的响应头了
# 代理
适用场景:生产环境不发生跨域,但开发环境发生跨域
开发代理:只需要在开发环境使用代理解决跨域

module.exports = {
devServer: { // 配置开发服务器
proxy: { // 配置代理
"/api": { // 若请求路径以 /api 开头
target: "http://dev.taobao.com", // 将其转发到 http://dev.taobao.com
},
},
},
};
2
3
4
5
6
7
8
9
# nginx 代理
反向代理功能是nginx的三大主要功能之一(静态web服务器、反向代理、负载均衡)
反向代理:帮服务器拿到数据,选择合适的服务器
和CORS原理同,配置请求响应头Access-Control-Allow-Origin等
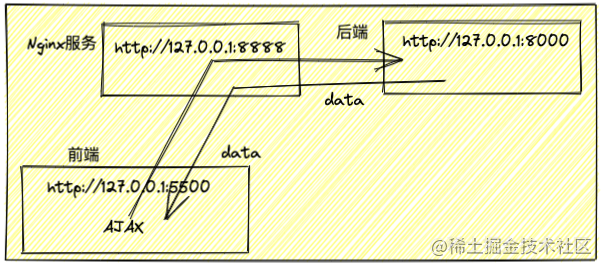
# 反向代理、负载均衡
Nginx作为反向代理服务器,把http请求转发到另一个或者一些服务器上。把本地一个url前缀映射到要跨域访问的web服务器上,实现跨域访问
Nginx检测url前缀,把http请求转发到真实的物理服务器
rewrite命令把前缀去掉。这样真实的服务器就可以正确处理请求,并且并不知道这个请求来自代理服务器 (opens new window)
正向代理就是冒充客户端,反向代理就是冒充服务端
# WebSocket
(与HTTP同级)
WebSocket请求头信息中有origin字段,表示请求源自哪个域,服务器可以根据这个字段判断是否允许本次通信
# document.domain + iframe
原理:相同主域名不同子域名下的页面
**只能用于二级域名相同的情况下,**比如 a.test.com 和 b.test.com 适用于该方式
只需要给页面添加 document.domain = 'test.com' 表示二级域名都相同就可以实现跨域
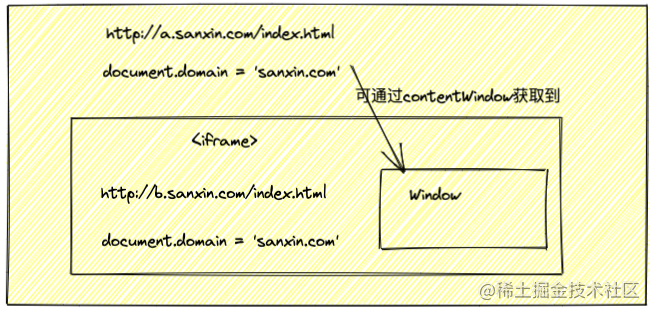
# location.hash + iframe
通过C页面实现A和B通信
# window.name(共享变量) + iframe
# Apache转发
逆向代理,让跨域变成同域
CSS文件的加载受跨域限制吗??
# proxy
proxy原理——"同源策略是浏览器需要遵循的标准,但如果是服务器向 服务器请求 就无须遵循同源策略"
实现——本地向proxy代理服务器发送请求,proxy接收本地请求,转化为目标地址相同IP和端口 向 目标地址发请求
proxy: {
'/api': {
'target': 'http://178.192.13.284:9060',//目标URL
'changeOrigin': true,
'pathRewrite': { '^/api' : '' }
},
2
3
4
5
6
# 跨域标准
跨域往标准靠近,cors,nginx和jsonp属于较老的技术了
# 反向/正向代理
代理服务器 代理了 目标服务器,和 客户端 交互
将不同域名转换为相同域名
正向代理是客户端的代理,反向代理是服务器的代理
正向代理一般客户端架设;反向代理一般服务器架设
正向代理服务器不知道真正的客户端是谁,反向代理 客户端不知道真正的服务器是谁
正向代理为了解决访问限制问题;反向代理提供复杂均衡、安全防护等;二者 均能挺高访问速度
所以 梯子 这个行为其实是 正向代理,突破访问权限的,由客户端来架设的,方向代理是为了所有人都能访问服务端
正向代理作用
突破访问限制(中介 角色)
提高访问速度
隐藏客户端真实IP
2
3
# ✔️ 鉴权
# Cookie
服务端响应客户端请求时,返回一个cookie,后续客户端的请求携带这个cookie
特点
- 存储在客户端,可随意纂改
- 影响性能,最大为4kb
- 一个浏览器对于一个网站只能存不超过20个Cookie,而浏览器一般只允许存放300个Cookie
- 移动端对Cookie支持不友好
- 一般情况下存储的是纯文本
设置正确的domain和path,减少数据传输,节省带宽
# Cookie-session
cookie需要的存的东西越来越多,但是cookie大小有限制
所以后端返回sessionId,客户端将sessionid存在cookie中
缓存数据库:所有机器根据sessionId去缓存系统获取用户信息和认证
局限性
- 依赖Cookie,但Cookie可被禁用
- 系统不停请求缓存服务器查找信息,内存开销增加
- 存在单点登录失败的可能性
若负责session的机器挂了,整个登录就挂了,但项目中,负责session的机器也是有多台机器的集群进行负载均衡增加可靠性
# SSO
(单点登录)三种类型
Single Sign On 在多个应用系统中,只需要登录一次,就可以访问其他相互信任的应用系统
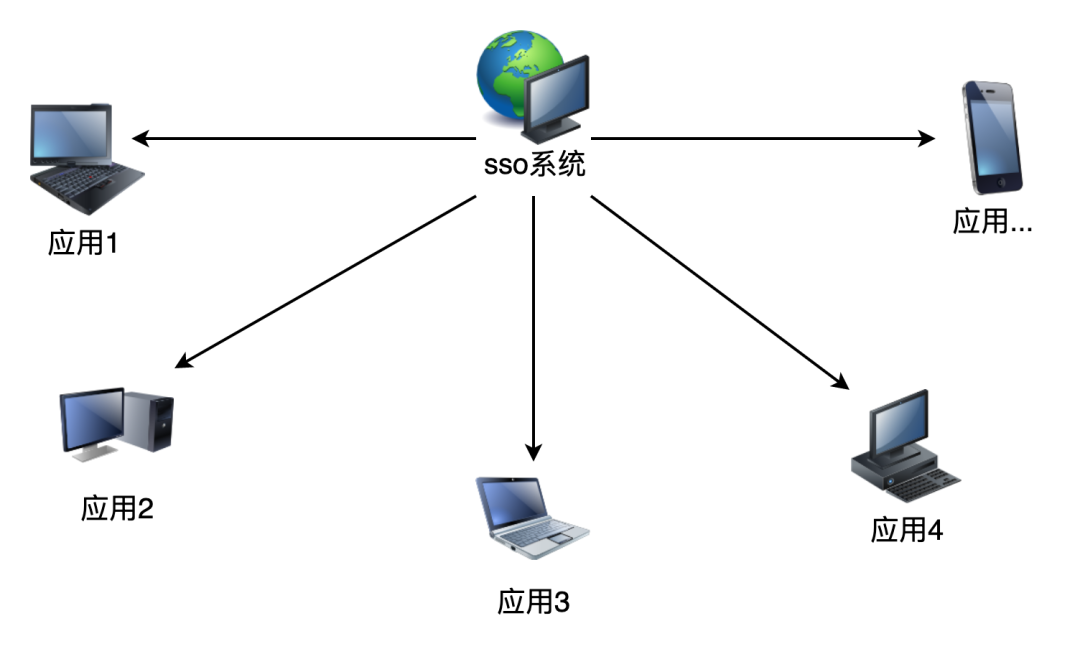
单点登录
- 同一站点下
- 相同的顶级域名
- 不同的顶级域名
相同域名和相同顶级域名下可共享cookie
但是不同域呢?
CAS(中央认证服务)原理
流程和Cookie-session模式相同

“跳到SSO系统准备登录时发现SSO已经登录了”咋做到的?
Oauth2授权机制,系统b向SSO系统跳转时,让它从系统a跳转,携带系统a的会话信息跳到SSO,再重定向回到系统b
阮一峰-OAuth 2.0 的四种方式 (opens new window)
# Json Web Token
最简单的
token组成:uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,由token的前几位+哈希算法压缩成一定长的十六进制字符串,防止恶意三方拼接token请求)
JWT由header(头部)、payload(负载)、signature(签名)这三个部分组成,中间用.来分隔开:Header.Payload.Signature
jwt: "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyaWQiOiJhIiwiaWF0IjoxNTUxOTUxOTk4fQ.2jf3kl_uKWRkwjOP6uQRJFqMlwSABcgqqcJofFH5XCo"
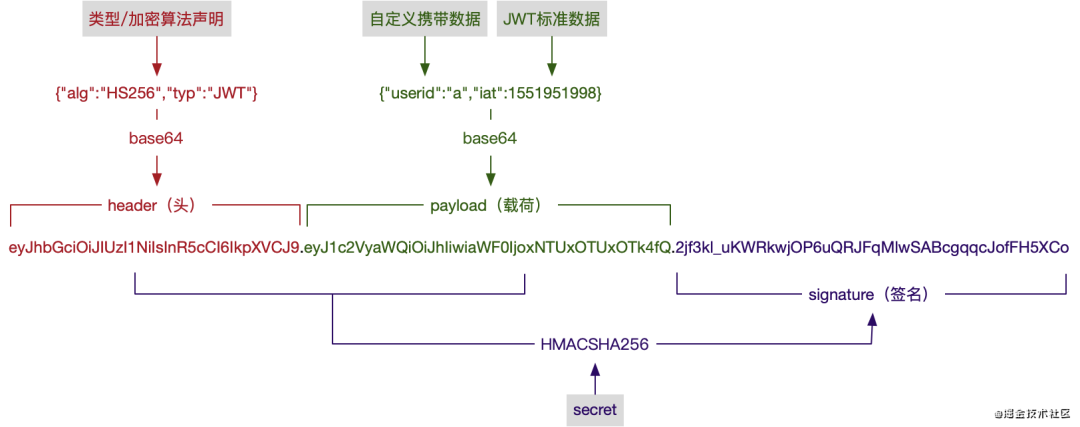
- JWT工作原理

弊端
- JWT的退出是假的登录失效,只要之前的token没过期依然可以用
- 安全性依赖密钥
- 加密生成的数据长
优点
- 无状态,可扩展
- 支持移动设备
- 跨程序调用
- 安全
session 和 token 的对比就是「用不用cookie」和「后端存不存」的对比
说出以上方法时,顺便说自己项目中用的哪些鉴权方法
用了cookie token jwt
# OAuth 2.0
authorization
目前最流行的授权机制,授权第三方应用,获取用户数据
场景再现 有没有一种方法,能够让快递员自由进入校区,但是不知道小区居民的密码,同时他们唯一权限就是送货
数据的所有者告诉系统,同意授权第三方应用进入系统,获取数据,系统产生一个token代替密码,供第三方使用
OAuth2.0有四种颁发令牌的方式
- 授权码(authorization-code)
- 隐藏式(implicit)
- 密码式(password):
- 客户端凭证(client credentials)
第三方需要先备案,拿到2个身份识别码:客户端ID和客户端密钥
# 前后端实时通信
# Ajax轮询
设置周期T,每T s向服务端请求一次数据,达到实时显示,本质是HTTP的request/response模式
每次都是客户端主动请求,浪费贷款
# Websocket
只需一次握手 即可通信
# Service Worker
# 浏览器不同tab页通信
应用场景 网页即时通讯
# cookie
# localStorage
# web worker
service worker是web worker的一种类型