 JS
JS
# ❤️ 全局属性/函数
| 属性 | 描述 |
|---|---|
| Infinity (opens new window) | 正无穷大 |
| NaN (opens new window) | 某个值是不是数字值 |
| undefined (opens new window) | 未定义 |
| 函数 | 描述 |
|---|---|
| decodeURI() (opens new window) | 解码某个编码的 URI |
| decodeURIComponent() (opens new window) | 解码一个编码的 URI 组件 |
| encodeURI() (opens new window) | 把字符串编码为 URI |
| encodeURIComponent() (opens new window) | 把字符串编码为 URI 组件 |
| escape() (opens new window) | 对字符串进行编码 |
| eval() (opens new window) | 计算 JS 字符串,把它作为脚本代码执行 |
| isFinite() (opens new window) | 检查某个值是否为有穷大的数 |
| isNaN() (opens new window) | 检查某个值是否是数字 |
| Number() (opens new window) | 把对象的值转换为数字 |
| parseFloat() (opens new window) | 解析一个字符串返回一个浮点数 |
| parseInt() (opens new window) | 解析一个字符串返回一个整数 |
| String() (opens new window) | 把对象的值转换为字符串 |
| unescape() (opens new window) | 对由 escape() 编码的字符串解码 |
# isNaN、number.isNaN
isNaN 尝试将参数转换为数值,任何不能被转换为数值的的值都返回 true,因此非数字值传入也返回 true ,会影响 NaN 的判断
Number.isNaN 先判断参数是否为数字,如果是数字继续判断是否为 NaN ,对于 NaN 的判断更为准确
function typeOfNaN(x) {
if (Number.isNaN(x)) {
return 'Number NaN';
}
if (isNaN(x)) {
return 'NaN';
}
}
console.log(typeOfNaN('100F'));
// expected output: "NaN"
console.log(typeOfNaN(NaN));
// expected output: "Number NaN"
2
3
4
5
6
7
8
9
10
11
12
13
14
# isFinite、isNaN
Infinity和-Infinity是特殊数值
NaN代表一个error
都是number类型,但不是"普通"数字
isNaN(val),将val转换为数字,再测试是否为NaN
isNaN(NaN);//true
isNaN('merry');//true
2
NaN独一无二,不等于任何东西,包括自身
NaN===NaN;//false
isFinite(val)将val转换为数字,若是常规数字而不是NaN/Infinity/-Infinity,则返回true
isFinite(11);//true
isFinite("merry");//false 因为是NaN
isFinite(Infinity);//false 因为是Infinity
2
3
在所有数字函数中,包括isFinite,空字符串或只有空格的字符串都被视为0
# parseInt、parseFloat
+'le'==parseInt('le')//false
因为NaN不等于NaN
+和Number()转换数字是严格的,若一个值不完全是数字,会失败
console.log(+"100px");//NaN
console.log(+" ");//0
2
从"100px","12pt"中将数值提取出来,parseInt和parseFloat派上用场,它们可以从字符串中读取数字,直到无法读取位置,若出现error,则返回收集到的数字
parseInt("100px");//100
parseInt("11.22px");//11
parseFloat("12.33px");//12.33
parseFloat("12.3.4");//12.3
2
3
4
5
没有数字可读取时,返回NaN
parseInt("a123");//NaN
parseInt(str,radix)
alert( parseInt('0xff', 16) ); // 255
alert( parseInt('ff', 16) ); // 255,没有 0x 仍然有效
alert( parseInt('2n9c', 36) ); // 123456
2
3
4
# escape、encodeURI、encodeURIComponent
escapeURI(已废弃),16进制转义序列。当该值小于等于 0xFF 时,用一个 2 位转义序列: %xx 表示。大于则使用 4 位序列:%uxxxx 表示
对整个 URI 转义,将非法字符转换为合法字符,一些特殊意义的字符不会转义
escape和encodeURI作用相同,对Unicode编码为0xFF之外字符有区别
- escape直接在字符Unicode编码前加上%u
- encodeURI将字符转换为UTF-8格式,再在每个字符前加上%
encodeURIComponent 对URI 的组成部分转义,一些特殊字符也会转义
encodeURIComponent和encodeURI异同?
var set1 = ";,/?:@&=+$"; // 保留字符
var set2 = "-_.!~*'()"; // 不转义字符
var set3 = "#"; // 数字标志
var set4 = "ABC abc 123"; // 字母数字字符和空格
console.log(encodeURI(set1)); // ;,/?:@&=+$
console.log(encodeURI(set2)); // -_.!~*'()
console.log(encodeURI(set3)); // #
console.log(encodeURI(set4)); // ABC%20abc%20123 (空格被编码为 %20)
console.log(encodeURIComponent(set1)); // %3B%2C%2F%3F%3A%40%26%3D%2B%24
console.log(encodeURIComponent(set2)); // -_.!~*'()
console.log(encodeURIComponent(set3)); // %23
console.log(encodeURIComponent(set4)); // ABC%20abc%20123
2
3
4
5
6
7
8
9
10
11
12
13
14

为避免服务器收到不可预知的请求,对用户输入的任何作为URI的部分都应使用encodeURIComponent转义
# ES6特性
const、let
模板字符串
箭头函数
函数参数默认值
对象、解构赋值
for...of 用于数组,for...in用于对象
Promise
展开运算符(...)
对象字面量、class(原型链的语法糖)
// ES5 // 构造函数 function Person(name, age) { this.name = name; this.age = age; } // 原型方法 Person.prototype.getName = function() { return this.name } // ES6 class Person { constructor(name, age) { // 构造函数 this.name = name; this.age = age; } getName() { // 这种写法表示将方法添加到原型中 return this.name } static a = 20; // 等同于 Person.a = 20 c = 20; // 表示在构造函数中添加属性 构造函数中等同于 this.c = 20 // 箭头函数的写法表示在构造函数中添加方法,构造函数中等同于this.getAge = function() {} getAge = () => this.age }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 🌈 内存空间
# 栈
一块连续内存区域,容量小 ,基本用完就回收,相对 存取速度更快,为先进先出结构,自动分配 固定大小的内存空间,系统自动释放
基本数据类型按值存在栈内存中,占用内存空间由 系统自动分配和释放,内存可及时回收,容易管理内存空间
栈空间就是JS的调用栈,存储执行上下文及执行上下文中基本类型的小数据
变量环境:存放var和函数声明的变量,编译时确定,不受块级作用域影响
词法缓存:存放let和const声明的变量空间,编译时不能完全确定,受块级作用域影响
V8把数字分成 :smi 和 heapNumber
smi是 -2³¹ 到 2³¹-1的整数,栈中直接存值;其余数字类型都是heapNumber,另外开辟堆空间储存,变量保存引用
# 堆
不连续内存区域,容量大,存储大数据,堆中对象不会随方法结束而销毁,没有被引用时被回收掉 ,动态分配内存,内存大小不固定,不会自动释放,无序的树状结构
# ⭐️数据类型
引用数据类型包括对象、数组和函数等
原始类型
Undefined ,Null ,Boolean,Number,String
ES6新增Symbol和BigInt
- Symbol 代表独一无二的值,用法是为对象定义唯一属性名
- BigInt 表示任意大小的整数, 指安全存储、操作大整数
引用类型
# null、undefined
- 两个基本数据类型
- undefined 未定义,null 空对象。一般变量声明了但没有定义返回 undefined,null 主要给一些可能返回对象的变量赋值,作为初始化
- undefined 在 js 中不是一个保留字,我们可以使用 undefined 作为一个变量名,这样非常危险,它会影响我们对 undefined 的判断。但我们可以获得安全的 undefined 值,比如说 void 0(此运算符优先级较高)
let undefiend = 'test' 覆盖 JS自身undefined?
JS为全局创建一个只读的undefined,但没有彻底禁止局部undefined变量的定义
- 使用 typeof ,Null 返回 “object”,历史遗留问题。当我们使用==比较两种类型 时返回 true,使用===返回 false
typeof null="Object"?
在第一版JS中,变量的值被设计保存在一个32位内存单元中。在变量的机器码的低位 1-3 位存储其 类型信息
000:对象
1:int
010:double
100:string
110:boolean
特殊情况:
- undefined -2^30(超出当时整型取值范围的一个数)
- null 空指针,所有机器码均为 0
null 被误判为Object
# 数字处理
- parseInt(5.4) 只保留整数部分,有基模式
- parseFloat() 值转换成浮点数,没有基模式
- Number() 转换成数字(可以是整数或浮点数),Number()的强制类型转换与parseInt()和parseFloat()方法的处理方式相似,只是它转换的是整个值,而不是部分值
- Math.floor(4.33) 向下取整
- Math.ceil(6.7) 向上取整
- Math.round(6.19) 四舍五入的 整数
- Math.random() [0,1),生成随机数
- Math.abs(-1) 绝对值
- String() 把给定的值转换成字符串
# toFixed(n)
数字舍入到小数点后n位(四舍五入),以字符串形式返回
为啥?
6.35.toFixed(1);//6.3
6.35的小数部分是一个无限的二进制,存储造成精度损失
alert( 6.35.toFixed(20) ); // 6.34999999999999964473
酱紫,数字就变小一点
解决办法——舍入之前,使其更接近整数
alert( (6.35 * 10).toFixed(20) ); // 63.50000000000000000000
alert( Math.round(6.35 * 10) / 10); // 6.35 -> 63.5 -> 64(rounded) -> 6.4
2
乘除法,将数字舍入到固定n位
let num=1.23456
Math.round(num*100)/100;
//1.23456->123.456->123->1.23
2
3
# parseInt()
解析一个字符串,返回整数。parseInt相比Number,没那么严格,parseInt逐个解析字符,遇到不能转换的字符就停下来
parseInt(string, radix)
string 必需。要被解析的字符串
radix 可选。表示要解析的数字的基数。该值介于 2 ~ 36 之间
如果省略该参数或其值为 ‘0‘,则数字将以 10 为基础解析,如果以 ‘”0x”‘ 或 ‘”0X”‘ 开头,将以 16 为基数
如果该参数小于 2 或者大于 36,则 parseInt()返回 NaN
# ['1', '2', '3'].map(parseInt)
- parseInt('1', 0) //radix为0,string参数不以“0x”/“0”开头,按10为基数处理。返回1
- parseInt('2', 1) //基数为1表示的数最大值小于2,无法解析,返回NaN
- parseInt('3', 2) //基数为2表示的数最大值小于3,无法解析,返回NaN
map返回数组,结果为[1, NaN, NaN]
# toPrecision()
把数字格式化为指定的长度:
var num = new Number(13.3714);
var n=num.toPrecision(2);
console.log(n)
2
3
# 🔥 Symbol
表示唯一标识符
只有两种原始类型可作为对象属性键
- 字符串
- Symbol
应用
- 属性名(避免冲突)
- 定义私有
- 唯一值
特点
- 不能使用new
- 不能使用 .
- 不能使用for-in
使用其他类型,会被转换为字符串
obj[1]===obj["1"]
obj[true]===obj["true"]
2
let id1=Symbol("id1");
let id2=Symbol("id2");
id1===id2;//false
//描述只是一个标签,不影响任何东西
2
3
4
Symbol不会被自动转换为字符串——防止“混乱”的语言保护,字符串和Symbol有着本质的不同
Symbol属性不参加for-in循环、Object.keys()
因为Symbol是“隐藏的属性部分”
但是,Object.assign()会同时复制字符串和Symbol属性
let id = Symbol("id");
let user = {
[id]: 123
};
let clone = Object.assign({}, user);
alert( clone[id] ); // 123
2
3
4
5
6
7
8
因为合并对象时,肯定希望一个不落合并所有属性啊!!
全局Symbol——可随处访问
// 从全局注册表中读取
let id = Symbol.for("id"); // 如果该 symbol 不存在,则创建它
// 再次读取(可能是在代码中的另一个位置)
let idAgain = Symbol.for("id");
// 相同的 symbol
alert( id === idAgain ); // true
2
3
4
5
6
7
8
//通过 name 获取 Symbol
Symbol.for('a') === Symbol.for('a') //true
Symbol('a') === Symbol('a') //false
2
3
“隐藏 ”属性
Symbol可创建对象的“隐藏”属性,其他地方不能访问或修改
let user = { // 属于另一个代码
name: "John"
};
let id = Symbol("id");
user[id] = 1;
alert( user[id] ); // 我们可以使用 symbol 作为键来访问数据
2
3
4
5
6
7
8
使用“id”和Symbol("id")作为对象的键有啥区别?
防止意外重写属性
尽管Symbol的description一样,但是Symbol总是不同
而且我们添加的Symbol属性不会被意外访问到
JS 使用了许多系统 symbol,这些 symbol 可以作为 Symbol.* 访问。可以使用它们改变一些内建行为。例如,使用 Symbol.iterator 进行 迭代 (opens new window) 操作,用Symbol.toPrimitive 设置 对象原始值的转换 (opens new window) 等
# 💛 Array方法
# 创建数组
- new Array()
let arr=new Array("merry","aa");
单个数字参数调用new Array,创建一个指定长度没有项的数组
- Array.from() 浅拷贝
const dp=Array(5).fill();
const dp = Array.from(Array(m+1), () => Array(n+1).fill(0));
let res = new Array(n).fill(0).map(() => new Array(n).fill(0));
2
3
类数组对象或者可迭代对象中创建新的数组实例
Array.from 可接受第二个参数,类似于数组的map方法,处理每个元素,处理后的值放入返回的数组
- Array.of()
根据一组参数创建新的数组实例,支持任意参数数量和类型,没有参数时返回 [],参数只有一个的时候,实际上是指定数组的长度
注意
数组没有Symbol.toPrimitive,也没有valueOf,它们只能执行toString转换
alert( [] + 1 ); // "1"
alert( [1] + 1 ); // "11"
alert( [1,2] + 1 ); // "1,21"
2
3
当+运算符把一些项加到字符串后时,加号后面的项也会被转换为字符串

# 改变原数组
- push
返回数组最新长度
# 数组内存不够了,但还是要继续push元素咋办?
内存都不够了,还push,直接报错 栈溢出
扩容机制??
- pop()
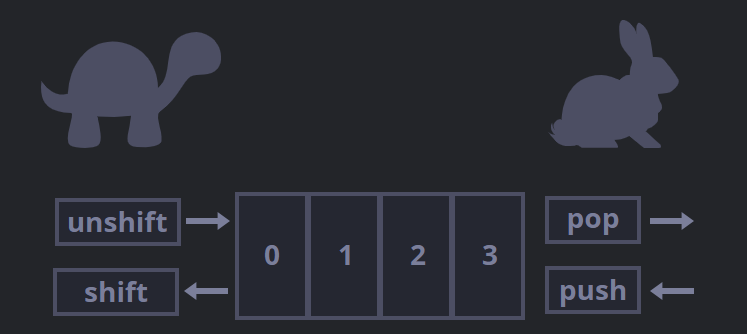
为啥作用于数组末端比首端快呢?
- shift需要做3件事:
1、移除索引为0的元素
2、把所有元素向左移动,并重新编号
3、更新length属性
- unshift()
返回新数组长度
- splice
delete obj.key通过key移除对应的值3
let arr = ["I", "go", "home"];
delete arr[1]; // remove "go"
alert( arr[1] ); // undefined
// now arr = ["I", , "home"];
alert( arr.length ); // 3
2
3
4
5
6
7
8
splice删除或替换现有元素或原地添加新元素修改数组,返回被修改数组
***会改变原数组!!***
返回值由被删除元素组成的数组,若只删除一个元素,则返回只包含一个元素的数组,若没有删除元素,则返回 []
[2, 3, 4].splice(0, 1); // 0位置删除一个,返回[2]
[2, 3, 4].splice(0, 1, 5); // 0位置删除1个,插入5,原数组是[5, 3, 4],返回[2]
arrayObject.splice(start,deleteCount,item1,.....,itemX)
start 必需。添加/删除项目位置,负数可从数组结尾处规定位置
deleteCount 必需。删除项目数量。设置为 0,则不会删除项目
item1, ..., itemX 可选。向数组添加新项目
2
3
4
5
6
shift()
sort()
默认 将元素转为字符串,比较UTF-16代码单元值序列
无法保证排序的时间/空间复杂性
a-b 是正数,根据规则,b会被移到a的前面
a-b 是负数,根据规则,a会排列到b的前面
//升序
function compareNumbers(a, b) {
return a - b;
}
2
3
4
function compareNumeric(a, b) {
if (a > b) return 1;
if (a == b) return 0;
if (a < b) return -1;
}
let arr = [ 1, 2, 15 ];
arr.sort(compareNumeric);
alert(arr); // 1, 2, 15
2
3
4
5
6
7
8
9
10
11
12
- reverse()
# 不改变原数组
- concat()
返回新数组
- slice(start,end)左闭右开,可以为负数
返回一个包含原有数组中一个或多个元素的新数组
- filter
判断所有元素,将满足条件的元素作为一个新的数组返回
- join()
- find()
- findIndex()
- indexOf()
- includes()
# 其他
- copyWithin()
将指定位置的成员复制到其他位置(会覆盖原有成员),返回当前数组
- target(必需):从该位置开始替换数据。负值表示倒数
- start(可选):从该位置开始读取数据,默认 0。负值表示从末尾开始计算
- end(可选):到该位置前停止读取数据,默认等于数组长度。负值,表示从末尾开始计算
[1, 2, 3, 4, 5].copyWithin(0, 3);
// 将从 3 号位直到数组结束的成员(4 和 5),复制到从 0 号位开始的位置,结果覆盖了原来的 1 和 2
// [4, 5, 3, 4, 5]
2
3
- fill()
可以接受第二个和第三个参数,指定填充的起始位置和结束位置
如果填充的类型为对象,则是浅拷贝
实现
function fill (n, m) {
n--
if(n) {
return [m].concat(fill(n, m))
} else {
return m
}
}
console.log(fill(3,4))
2
3
4
5
6
7
8
9
10
- reduce
不改变原始数组
每一次运行 reducer 会将先前元素的计算结果作为参数传入,最后将其结果汇总为单个返回值
var numbers = [65, 44, 12, 4];
function getSum(total, num) {
return total + num;
}
let sum = numbers.reduce(getSum);
//语法
let val=arr.reduce((pre,cur,index,arr)=>{
//...
},[initial]);
2
3
4
5
6
7
8
9
10
应用
- 累加器
- 求数组最大/小值
- 提取URL参数
- 二维数组转为一维
- 数组拍平
- 字符统计
- 反转串
- reduceRight
和reduce功能一样,遍历顺序从右到左
- some(不用遍历整个数组,就能得到结果)
判断所有元素,若存在元素满足条件,返回 true,若所有元素都不满足条件,返回 false
类似的API?
find?
findIndex?
- every
判断 所有元素返回一个布尔值,如果所有元素都满足条件,则返回 true,否则为 false
- flat(),flatMap()
数组扁平化,返回新数组,对原数据没有影响
flat()默认“拉平”一层,如果想要“拉平”多层嵌套数组,参数为整数,表示想要拉平的层数,默认为1
flatMap()对原数组的每个成员执行一个函数相当于执行Array.prototype.map(),对返回值组成的数组执行flat()。返回新数组,不改变原数组
flatMap()`方法还可以有第二个参数,绑定遍历函数里面的`this
- arr.at(i)
若i>=0,就和arr[i]完全相同
若i<0,倒数
let fruits = ["Apple", "Orange", "Plum"];
// 与 fruits[fruits.length-1] 相同
alert( fruits.at(-1) ); // Plum
2
3
4
- delete
删除对象的属性/数组元素,删除对象属性本身,不会删除属性指向的对象
若 delete 数组某位元素,数组长度不变,只是元素为 empty item
原型中声明的属性/对象自带属性无法被删除
var声明的变量和通过function声明的函数拥有dontdelete属性,不能被删除
- map
map() 返回新数组,数组中元素为原始数组元素调用函数处理后的值
map() 按照原始数组元素顺序依次处理元素
- forEach
基本数据类型——>死都改不动原数组!拷贝值
引用类型——>类似对象数组可以改变,拷贝地址
forEach原理是for循环,使用arr[index]赋值改变
总结
几乎所有调用函数的数组方法都支持可选附加参数'thisArg',除了sort
let army={
a:1,
canJoin:function(user){
if(user!=='c'){
console.log(user)
}
}
}
let users=['a','b','c']
const ans=users.filter(user => army.canJoin(user))
console.log(ans)
const ans1=users.filter(army.canJoin, army)
console.log(ans1)
2
3
4
5
6
7
8
9
10
11
12
13
不用全部遍历数组就能得出结果的api,比如some,除此之外 还有哪些?
# 🌱 Set集合
Set 允许存储任何类型的唯一值
Set 是值的集合,可以存储任意类型的值,Set 可以按照插入顺序遍历输出,插入的值会自动去重
# 特殊情况
- 0 和 -0 不会去重
- NaN 不等于 NaN,但是 NaN 和 NaN 会去重,只能存储一个
let mySet = new Set();
mySet.add(1); // Set [ 1 ]
mySet.add(5); // Set [ 1, 5 ]
mySet.add(5); // Set [ 1, 5 ]
mySet.add("some text"); // Set [ 1, 5, "some text" ]
let o = {a: 1, b: 2};
mySet.add(o);
mySet.add({a: 1, b: 2}); // o 指向的是不同的对象,所以没问题
mySet.has(1); // true
mySet.has(3); // false
mySet.has(5); // true
mySet.has(Math.sqrt(25)); // true
mySet.has("Some Text".toLowerCase()); // true
mySet.has(o); // true
mySet.size; // 5
mySet.delete(5); // true, 从set中移除5
mySet.has(5); // false, 5已经被移除
mySet.size; // 4, 刚刚移除一个值
console.log(mySet);
// logs Set(4) [ 1, "some text", {…}, {…} ] in Firefox
// logs Set(4) { 1, "some text", {…}, {…} } in Chrome
mySet.clear()//清楚所有成员,没有返回值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 遍历
- keys():返回键名的遍历器
- values():返回键值的遍历器
- entries():返回键值对的遍历器
- forEach():使用回调函数遍历每个成员
Set的遍历顺序就是插入顺序
keys方法、values方法、entries方法 都是 返回 遍历器对象
实现并集、交集、和差集:
let a = new Set([1, 2, 3]);
let b = new Set([4, 3, 2]);
// 并集
let union = new Set([...a, ...b]);
// Set {1, 2, 3, 4}
// 交集
let intersect = new Set([...a].filter(x => b.has(x)));
// set {2, 3}
// (a 相对于 b 的)差集
let difference = new Set([...a].filter(x => !b.has(x)));
// Set {1}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 集合转换为数组
Array.from(arrayLike object)
扩展运算符(...)
forEach
let ans=Array.prototype.slice.apply(set)???待考究
# Map字典
key值不能重复!
map.size // 属性返回 Map 结构的成员总数
const m = new Map().set('key1', 'val1')
Map.prototype.set(key, value) // 方法设置键名key对应的键值为value,返回整个 Map 。如果key已经有值,键值会被更新,否则就新生成该键
// set方法返回的是当前的Map对象,因此可以采用链式写法
Map.prototype.get(key) // 读取key对应的键值,如果找不到key,返回undefined
Map.prototype.has(key) // 返回一个布尔值,表示某个键是否在当前 Map 对象之中
Map.prototype.delete(key) // 删除某个键,返回true。如果删除失败,返回false
Map.prototype.clear() // 清除所有成员,没有返回值
Map.prototype.keys():// 返回键名的遍历器
Map.prototype.values():// 返回键值的遍历器
Map.prototype.entries():// 返回所有成员的遍历器
Map.prototype.forEach():// 遍历 Map 的所有成员
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 判断是否存在某个值
array.indexOf(item,from) //return 下标或-1
array.lastIndexOf(item,from)
array.includes(item,from)
判断字符串/数组是否包含另一个字符,返回 true/false,第二个参数表示搜索的起始位置,默认0,为负数表示倒数
以上3种方法和字符串操作具有相同的语法!!使用===比较!
- array.find() 返回满足条件的第一个元素的值
let res=arr.find((item,index,arr)=>{
//返回true,则返回item并停止迭代
//返回false,则返回undefined
});
2
3
4
- array.findIndex() 返回满足条件的第一个元素下标,没有找到返回-1
find和findIndex都可以接受第二个参数,绑定回调函数的
this
# 遍历语法比较
(for、forEach、map、 for...in、for...of的区别)
数组遍历各个方法的速度:传统的for循环最快,for-in最慢
for-in
>for>for-of>forEach>map>for-in
# for
速度最快,兼容旧版本浏览器
优化一下
let arr=[1,2,3,4,5];
for(let i=0,len=arr.length;i<len;i++){
}
2
3
4
临时变量存储len,避免重复获取数组长度,只有len较大时优化才明显
# for in (ES5)
- 枚举对象属性包括继承属性,除Symbol
- 不建议使用 for in 遍历数组
因为输出属性名的顺序不可预测,效率低
是第一个能迭代对象键的JS语句,循环对象键与在数组上循环不同,引擎会执行额外的工作跟踪已迭代的属性
- 如果迭代对象的变量值是 null 或 undefined, for in 不执行,建议使用 for in 循环之前,先检查
- 遍历数组索引,得到对象的key或数组,字符串下标
- 遍历数组的话,类数组有length和索引属性,也可能有其它非数字的属性和方法,for-in会全部列出来
# for of (ES6)
- for…of 语句在可迭代对象上创建一个迭代循环,调用自定义迭代钩子,为每个不同属性的值执行语句
- 得到对象的value或数组、字符串的值,还可以遍历Map和Set
- for of 循环数组时怎么拿到数组索引?
ES6之前的遍历方法都会跳过数组未赋值过的位置,即空位,但是ES6新增的for of 不会跳过
- 可使用break
- 避开了for-in所有缺陷
- 可正确响应break、continue和return
- 支持字符串遍历
Object没有iterator属性,因此它不是可迭代对象,没有for-of方法,不过我们可以自定义方法实现遍历
性能优于for-in
# every/some
返回布尔值
every判断数组每一项,some当某一项满足条件返回
# fliter
过滤数组成员,满足条件的成员组成一个新数组返回,否则返回[]
不改变原数组
# forEach()
foreach不是es6的方法,是es3的
修改原数组,遍历可迭代对象,不返回执行结果,而是undefined,return无法终止 有continue效果
中断forEach
- 使用try监视代码块,中断地方抛出异常
- 替换:every和some碰到return false时,中止循环
function log(msg, time) {
return new Promise((resolve) => {
setTimeout(() => {
console.log(msg);
resolve();
}, time);
});
};
(async () => {
[1, 2, 3, 4].forEach(async (i,index,array) => {
await log(i, 1000);
});
})();
// 1s 后依次输出1 2 3 4
2
3
4
5
6
7
8
9
10
11
12
13
14
对于异步代码,forEach不能保证按顺序执行
for...of /in可解决问题,不像forEach简单粗暴遍历执行,而是采用迭代器遍历
# map()
遍历可迭代对象
分配内存并返回新数组,不改变原数组
不能break,否则引发异常
可使用for循环/for-in/for-of中断循环
关于map和forEach的性能对比问题,我也没有找到答案,网络上众说纷纭,其实也不用太纠结它们的速度快慢
# ["1", "2", "3"].map(parseInt)
[1, NaN, NaN]
parseInt() 解析字符串,返回整数,两个参数 (val, radix),radix 表要解析数字的基数
(该值介于 2 ~ 36 之间,且字符串中的数字不能大于 radix 才能正确返回结果)
此处 map 传了 3 个参数 (element, index, array),默认第三个参数被忽略掉,因此三次传入的参数分别为 "1-0", "2-1", "3-2"
因为字符串的值不能大于基数,后面两次调用均失败,返回 NaN ,第一次基数为 0 ,按十进制解析返回 1
同理
let res=['1','2','100'].map(parseInt);//[1,NaN,4]
# 对比
for、forEach
- 都是遍历数组
- forEach永远返回undefined
- map是映射,返回新数组
map()效率更高不用太过纠结速度快慢,因为我也没找着答案- 二者均不能中断
- 可以使用简单的for循环或for-of/for-in中断循环
- 遍历可迭代对象
- 当只想遍历数据而修改时,使用forEach
- 建议用map转换数组元素
- for不创建函数
- forEach创建每次调用的函数
- 函数单独作用,产生额外开销
- 开发不考虑性能,forEach更具可读性
- 都可以接受第二个参数,绑定回调内的 this ,将回调内部的 this指向第二个参数,间接操作这个参数
- map()和filter()都会跳过空位,for 和 while 不会
# 🍅String方法
- charAt(index) 返回指定索引处的字符串,没找着返回空串
- charCodeAt(index) 返回指定索引处的字符的 Unicode值
// toLowerCase()转换成小写 toUpperCase()转换成大写
var x = "a".toLowerCase().charCodeAt(0)
//x = 97
2
3
- concat(str1, str2, ... ) 连接多个字符串,返回连接后串的副本,纯函数
- fromCharCode() 将 Unicode 值转换成实际的字符串
String.fromCharCode(97)
// 返回"a"
2
- indexOf(str) 返回 str 在父串中第一次出现的位置,若没有则返回-1
- lastIndexOf(str) 返回 str 在父串中最后一次出现的位置,若没有返回-1
- match(regex) 搜索字符串,返回正则表达式的所有匹配
- search(regex) 基于正则表达式搜索字符串,返回第一个匹配的位置
- slice(start, end) 返回字符索引在 start 和 end(不含)间的子串
- split(sep,limit) 将字符串分割为字符数组,limit 为从头开始执行分割的最大数量
- substr(start,length) 从字符索引 start 的位置开始,返回长度为 length 的子串
- substring(from, to) 返回字符索引在 from 和 to(不含)之间的子串,和slice几乎相同,但它允许from>to,不支持负参数,slice支持负参数
- toLowerCase() 将字符串转换为小写
- toUpperCase() 将字符串转换为大写
- valueOf() 返回原始字符串值
- toString() 把 Number 对象转换为字符串,返回结果
{} 的 valueOf 结果为 {} ,toString 的结果为 "[object Object]"
[] 的 valueOf 结果为 [] ,toString 的结果为 ""
2
3
- str.codePointAt(pos) 返回在pos位置的字符编码
// 不同的字母有不同的代码
alert( "z".codePointAt(0) ); // 122
alert( "Z".codePointAt(0) ); // 90
2
3
- String.fromCodePoint(code) 通过code创建字符
alert( String.fromCodePoint(90) ); // Z
//\u后跟十六进制代码,通过代码添加Unicode字符
// 在十六进制系统中 90 为 5a
alert( '\u005a' ); // Z
2
3
4
5
'a'>'Z'
因为字符通过数字代码比较,a(97)>Z(90)
// 英文是否大写
function upperCase(num) {
var reg = /^[A-Z]+$/;
return reg.test(num);
}
2
3
4
5
- repeat() 返回新的字符串 =重复了指定次数的原始字符串
# replace
不会修改原字符串!
第二个参数可传入要替换的目标串,这种用法中replace只会匹配一次
第二个参数也可以传入一个函数,若原始字符串中有n个我们查找的字符串,函数就会执行n次,且这个函数返回一个字符串,用来替换每次匹配到的字符串
# 参数
$&
匹配的字符串
var sStr='讨论一下正则表达式中的replace的用法';
sStr.replace(/正则表达式/,'《$&》');
// "讨论一下《正则表达式》中的replace的用法"
2
3
$`
匹配字符串左边的所有字符
var sStr='讨论一下正则表达式中的replace的用法';
sStr.replace(/正则表达式/,'《$`》');
// "讨论一下《讨论一下》中的replace的用法"
2
3
$'
匹配字符串右边的所有字符,既然有单引号,外面的引号必须双引号,如果不可以双引号,只能把单引号转义
var sStr='讨论一下正则表达式中的replace的用法';
sStr.replace(/正则表达式/,"《$'》");
// "讨论一下《中的replace的用法》中的replace的用法"
2
3
1,2,3,4……n
依次匹配子表达式
var sStr='讨论一下正则表达式中的replace的用法';
sStr.replace(/(正则)(.+?)(式)/,"《$1》$2<$3>");
//"讨论一下《正则》表达<式>中的replace的用法"
2
3
# 函数
var sStr='讨论一下正则表达式中的replace的用法';
sStr.replace(/(正则).+?(式)/,function() {
console.log(arguments);
});
// ["正则表达式", "正则", "式", 4, "讨论一下正则表达式中的replace的用法"]
2
3
4
5
参数:
- 匹配到的字符串
- 若正则使用了分组匹配就是多个,否则无此参数
- 匹配字符串的索引位置
- 原始字符串
或者使用命名形参:
var sStr='讨论一下正则表达式中的replace的正则表达式用法';
sStr.replace(/(正则).+?(式)/g,function($1) {
console.log($1);
return $1 + 'a';
});
2
3
4
5
# 用法
\s匹配任何空白字符(空格,制表符,换行符)
str = str.replace(/\s*/g); //去除所有空格
str = str.replace(/^\s*|\s*$/g, "");//去除首尾空格
str = str.replace(/^\s*/, "");
str = str.replace(/\s*&/, "");
2
3
4
\w 匹配任何单词字符,包括 字母 数字 下划线
name = "Doe, John";
let a=name.replace(/(\w+)\s*, \s*(\w+)/, "$2 $1");
console.log(a)
//John Doe
2
3
4
\b 匹配单词字符和非单词字符的边界位置
//首字母大写
let name = 'aaa bbb ccc';
let uw=name.replace(/\b\w+\b/g, function(word){
return word.substring(0,1).toUpperCase()+word.substring(1);}
);
2
3
4
5
# str. trim()
删除串两端空白字符并返回**,不影响原来字符串,返回新串**
只能去除字符串两端空格
# 截取字符串
# substring()
左闭右开,提取串中介于两个指定下标间的字符
substring(start,stop)
start:非负整数,提取子串的第一个字符索引,必写
stop:非负整数,比要提取子串的最后一个字符在字符串上的位置多 1,可写可不写,如果不写则返回子串会一直到字符串的结尾
该字符串的长度为stop-start
如果参数 start 与 stop 相等,返回空串,如果 start 比 stop 大,该方法在提取之前会先交换这两个参数
# substr()
抽取从 start 下标开始的指定数目的字符
substr(start,length)
- start:要截取的子串的起始下标,必须是数值。如果是负数,该参数从字符串的尾部开始算。-1 指字符串中最后一个字符,-2 指倒数第二个字符,以此类推,必需写
- length:子串中的字符数,必须是数值。如果不填,返回字符串的开始位置到结尾的字符。如果length 为0 或者负数,返回一个空串
# split()
把一个字符串分割成字符串数组
stringObject.split(separator,howmany)
separator:字符串或正则表达式,从该参数指定的地方分割字符串。必须写
howmany:指返回的数组的最大长度。如果设置了该参数,返回的子串不会多于这个参数指定的数组。如果没有设置该参数,整个字符串都会被分割,不考虑它的长度。可选
# String.prototype.padStart()
用另一个串填充当前字符串 (如果需要的话,会重复多次),以便产生的字符串达到给定的长度。从当前字符串左侧开始填充
# ✅ 正则
regular expression
# 方法
| 方法 | 描述 |
|---|---|
| exec | 执行查找匹配的RegExp方法,返回数组(未匹配到则返回 null) |
| test | 字符串中测试是否匹配,返回 true 或 false |
| match | 执行查找匹配字符串,返回数组,未匹配时返回 null |
| matchAll | 执行查找所有匹配的String方法,返回迭代器(iterator) |
| search | 测试匹配的String方法,返回匹配到的位置索引,失败返回-1 |
| replace | 执行查找匹配的String方法,使用替换字符串替换掉匹配到的子字符串 |
| split | 使用正则表达式或固定字符串分隔字符串,将分隔后的子字符串存储到数组中 |
# exec()
检索字符串中指定值,返回结果数组,若没有,则返回null

# compile()
改变RegExp,可改变检索模式也可add或delete第二个参数
# match()

# new RegExp()、字面量
使用字面量效率更高
//正则表达字面量
var re = /\\/gm;
//正则构造函数
var reg = new RegExp("\\\\", "gm");
var foo = "abc\\123"; // foo的值为"abc\123"
console.log(re.test(foo)); //true
console.log(reg.test(foo)); //true
2
3
4
5
6
7
8
9
使用构造函数时,要使用四个反斜杠才能匹配单个反斜杠。使得正则表达式模式更长,难以阅读。当使用 RegExp()构造函数时,不仅要转义引号(即"表示"),通常还需要双反斜杠(即\表示一个\)
# 校验规则
| 规则 | 描述 |
|---|---|
| \ | 转义 |
| . | 默认匹配除换行符之外的任何单个字符 |
| x(?=y) | 匹配'x'仅仅当'x'后面跟着'y'——先行断言 |
| (?<=y)x | 匹配'x'仅当'x'前面是'y'——后行断言 |
| x(?!y) | 仅当'x'后面不跟着'y'时匹配'x'——正向否定查找 |
| (?<!y)x | 仅当'x'前面不是'y'时匹配'x'——反向否定查找 |
| x|y | 匹配‘x’或者‘y’ |
| {n} | n 是正整数,匹配前面一个字符刚好出现了 n 次 |
| {n,} | n是正整数,匹配前一个字符至少出现了n次 |
| {n,m} | n 和 m 都是整数。匹配前面的字符至少n次,最多m次 |
| [xyz] | 一个字符集合。匹配方括号中的任意字符 |
| [^xyz] | 匹配任何没有包含在方括号中的字符 |
| \b | 匹配一个词的边界,例如在字母和空格之间 |
| \B | 匹配一个非单词边界 |
| \d | 匹配一个数字 |
| \D | 匹配一个非数字字符 |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \s | 匹配一个空白字符,包括空格、制表符、换页符和换行符 |
| \S | 匹配一个非空白字符 |
| \w | 匹配一个单字字符**(字母、数字或者下划线)** |
| \W | 匹配一个非单字字符 |
先行断言 从左往右看
后行断言 从右往左看
x(?=y)`匹配x`仅当x后面跟着y,不会将y包含在结果中正向先行断言
x(?!y) 仅当x后面不是y时`匹配x` ,负向先行断言
(?<=y)x `匹配x`仅当x前面是y ,正向后行断言
(?<!y)x 仅当x前面不是y时`匹配x `,反向否定查找(负向后行断言)
2
3
4
# 捕获、非捕获

捕获——可通过序号/名称使用这些匹配结果
非捕获——标识不需要捕获的分组
# 标记
| 标志 | 描述 |
|---|---|
g | 全局搜索 |
i | 不区分大小写搜索 |
m | 多行搜索 |
s | 允许 . 匹配换行符 |
u | 使用unicode码的模式匹配 |
y | 执行“粘性(sticky)”搜索,匹配从目标字符串的当前位置开始 |
# 千分位分隔
正则+replace
function format(num) {
const reg = /(\d)(?=(\d{3})+\.)/g;
return num && num.toString().replace(reg, function (s2) {
return s2 + ',';
});
}
2
3
4
5
6
function numFormat(num){
const reg=/(\d)(?=(\d{3})+$)/g;
const res=num.toString().replace(/\d+/, function(n){ // 先提取整数部分
return n.replace(reg,function(s1){
return s1+",";
});
})
return res;
}
//就它最正宗,不报错,点名表扬!
2
3
4
5
6
7
8
9
10
x(?=y) 仅当x后面为y时,匹配x
function numberWithCommas(x) {
var parts = x.toString().split(".");
parts[0] = parts[0].replace(/\B(?=(\d{3})+(?!\d))/g, ",");
return parts.join(".");
}
numberWithCommas(33333333333.3333333333)
2
3
4
5
6
7
x(?=y) 仅当x后面是y时匹配x
(?<!y)x 仅当x前面不是y时匹配x
x(?!y) 仅当x后面不是y时匹配x
function numberWithCommas(x) {
return x.toString().replace(/\B(?<!\.\d*)(?=(\d{3})+(?!\d))/g, ",");
}
numberWithCommas(1111111111.1111111111)
2
3
4
利用 正则 + 循环
function numberWithCommas(x) {
x = x.toString();
var pattern = /(-?\d+)(\d{3})/;
while (pattern.test(x)){
x = x.replace(pattern, "$1,$2");
}
return x;
}
numberWithCommas(12312124545);//'12,312,124,545'
numberWithCommas(123121245.45);//'123,121,245.45'
2
3
4
5
6
7
8
9
10
将数字转换为字符串,循环整个数组,每三位增加分隔逗号,最后合并成字符串,分隔符从后往前添加
function format2(num) {
num = num.toString().split(".");
let arr = num[0].split("").reverse();
let res = [];
for (let i = 0, len = arr.length; i < len; i++) {
if (i % 3 === 0 && i !== 0) {
res.push(",");
}
res.push(arr[i]);
}
res.reverse();
if (num[1]) {
res = res.join("").concat("." + num[1]);
} else {
res = res.join("");
}
return res;
}
format2(12345678.987654)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
调用API
function format1(number) {
return Intl.NumberFormat().format(number)
}
//Intl 对象是 ECMAScript 国际化 API 的一个命名空间,提供了精确的字符串对比、数字格式化,和日期时间格式化
// Intl.NumberFormat.prototype.format 属性返回一个根据NumberFormat对象的语言环境和格式化选项,来格式化一个数字的getter函数
2
3
4
5
function format2(number) {
return number.toLocaleString('en')
}
//toLocaleString() 方法返回这个数字在特定语言环境下的表示字符串
2
3
4
# 应用场景
// 匹配 16 进制颜色值
var regex = /#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g;
// 匹配日期,如 yyyy-mm-dd 格式
var regex = /^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$/;
//匹配 qq 号
var regex = /^[1-9][0-9]{4,10}$/g;
// 手机号码正则
var regex = /^1[34578]\d{9}$/g;
//用户名正则
var regex = /^[a-zA-Z\$][a-zA-Z0-9_\$]{4,16}$/;
2
3
4
5
6
7
8
9
10
11
12
13
14
# 初始化对象
Object.create()、字面量、new
创建一个对象,推荐字面量方式(无论性能上还是可读性)
new Object() 创建对象要通过作用域链一层层找到 Object,但使用字面量方式就没这个问题
var Person = {}; //相当于 var Person = new Object();
var Person = {
name: 'Nike';
age: 29;
}
2
3
4
5
ES5新增Object.create——内部定义对象,接受一个原型对象并创建指向它的新对象
# 实现Object.create()
F.prototype对象赋值为 引进对象/函数o,return新对象
Object.create = function (o) {
var F = function () {};
F.prototype = o;
return new F();
};
2
3
4
5
new 是新建对象o1,让o1的 __proto__ 指向 Base.prototype 对象,使用call 强转作用环境,实现对象创建
var o1 = new Object();
o1.[[Prototype]] = Base.prototype;
Base.call(o1);
2
3
区别
var Base = function () {
this.a = 2
}
var o1 = new Base();
var o2 = Object.create(Base);
console.log(o1.a); // 2
console.log(o2.a); // undefined
2
3
4
5
6
7
Object.create 失去了原来对象属性的访问
| 比较 | new | Object.create |
|---|---|---|
| 构造函数 | 保留原构造函数属性 | 丢失原构造函数属性 |
| 原型链 | 原构造函数prototype属性 | 原构造函数/(对象)本身 |
| 作用对象 | function | function、object |
let o=new Object()
let o={}
let o=new Object
let o=Object (×)
2
3
4
5
# 💜 对象方法
可选链
let user = {}; // user 没有 address 属性
alert( user?.address?.street ); // undefined(不报错)
2
Object.is()
严格判断两个值是否相等,与严格比较运算符(===)基本一致,不同之处
+0 === -0 //true
NaN === NaN // false
Object.is(+0, -0) // false
Object.is(NaN, NaN) // true
2
3
4
5
Object.assign()
- 用于对象的合并,将源对象
source的所有可枚举属性,复制到目标对象target - 第一个参数是目标对象,后面的参数都是源对象
console.log(Object.assign([1, 2, 3], [4, 5])); //4,5,3
数组视为对象,目标数组视为属性为0、1、2的对象,所以源数组的0、1属性的值覆盖了目标对象的值
Object.getOwnPropertyDescriptors()
- 返回指定对象所有自身属性(非继承属性)的描述对象
Object.setPrototypeOf()
- 设置一个对象的原型对象
Object.getPrototypeOf()
- 读取一个对象的原型对象
Object.fromEntries()
- 将一个键值对数组转为对象
Object.fromEntries([
['foo', 'bar'],
['baz', 42]
])
// { foo: "bar", baz: 42 }
2
3
4
5
Object.defineProperty()
直接在对象上定义新的属性,修改一个已经存在的属性
Object.defineProperty(obj, props, desc):
- obj: 需要定义属性的当前对象
- props: 当前准备定义的属性名
- desc: 对定义属性的描述
isPrototypeOf() 测试对象是否存在于另一对象的原型链上
哪些属性是函数function a(){}独有,对象const b = new Object()没有的?
- constructor
- [proto]
- isPrototypeOf
- prototype(√)
判断对象是否为空?(没有任何属性可以用什么方法)
# 判断对象是否有属性
. / []+undefined
判断对象自身属性和继承属性
属性名存在 但 值为undefined时,不能返回想要的结果——in 解决
1、in
如果属性来自对象的原型,仍然返回true
let obj={name:'aa'};
'name' in obj;//true
'toString' in obj;//true
2
3
2、Reflect.has()
检查属性是否在对象中,和in一样作为函数工作
const obj={name:111};
Reflect.has(obj,'name');//true
Reflect.has(obj,'toString');//true
2
3
3、hasOwnProperty()
返回布尔值,对象是否具有指定属性作为它**自己的属性**(不是继承)
可正确区分对象本身属性和其原型的属性
const obj={a:1};
obj.hasOwnProperty('a');//true
obj.hasOwnProperty('toString');//false
2
3
缺点:如果对象用Object.create(null)创建,不能使用这个方法
const obj=Object.create(null);
obj.name='merry';
obj.hasOwnProperty('name');
//Uncaught TypeError: obj.hasOwnProperty is not a function
2
3
4
4、Object.prototype.hasOwnProperty()
可解决3的问题,直接调用内置有效函数,跳过原型链
const obj=Object.create(null);
obj.name='merry';
Object.prototype.hasOwnProperty.call(obj,'name');//true
Object.prototype.hasPwnProperty.call(obj,'toString');//false
2
3
4
Object.propertyIsEnumerable() 判断对象是否包含某个属性,且这个属性是否可枚举(通过原型继承的属性除外)
5、Object.hasOwn()
若指定对象具有指定属性作为自己的属性,Object.hasOwn()静态方法返回true,若属性被继承或不存在,返回false
const obj=Object.create(null);
obj.name='merry';
Object.hasOwn(obj,'name');//true
Object.hasOwn(obj,'toString');//false
2
3
4
6、Object.keys()
返回对象本身可枚举类型(不含 继承 和Symbol 属性)的数组
Object.freeze() 冻结对象。一个被冻结的对象不能被修改,不能添加新的属性,不能删除已有属性,不能修改已有属性的任何属性 包括 值。冻结对象后该对象的原型也不能被修改
# 🙋♂ 对象遍历
| 可枚举属性 | 不可枚举属性 | 继承属性 | Symbol | |
|---|---|---|---|---|
| for-in | √ | × | √ | × |
| Object.keys() | √ | × | × | × |
| Object.getOwnPropertyNames() | √ | √ | × | × |
| Object.getOwnPropertySymbols() | × | √ | × | √ |
| Reflect.ownKeys() | √ | √ | × | √ |
# . 和[]?
[]语法 通过变量访问属性
如果属性包含空格,就不能通过 . 访问它。属性名可以包含非字母非数字,使用[]访问它
除非必须使用变量访问属性,否则我们使用点表示法
注意,属性名表达式如果是一个对象,默认情况下会自动将对象转为字符串[object Object]
const keyA = {a: 1};
const keyB = {b: 2};
const myObject = {
[keyA]: 'valueA',
[keyB]: 'valueB'
};
myObject // Object {[object Object]: "valueB"}
2
3
4
5
6
7
8
9
# for-in
遍历自身和继承的可枚举属性(不含 Symbol )
对象属性没有顺序,for-in输出的顺序不可预测
let obj = {
name: 'Scarlett',
age: 37,
[Symbol()]: 'Johansson'
}
for (let key in obj) {
console.log(key) // name age
}
// 在原型上添加一个可枚举属性
Object.prototype.nationality = 'America'
// 在obj对象上添加一个不可枚举属性
Object.defineProperty(obj, 'occupation', {
value: 'actress',
enumerable: false
})
for (let key in obj) {
console.log(key, obj[key])
}
/* 输出结果:包含对象自身的可枚举属性和原型上的可枚举属性
name Scarlett
age 37
nationality America
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Object.keys()
返回对象key组成的数组
数组成员是对象本身的 (不含继承)所有可枚举属性(不含 Symbol )的键名
let obj = {
name: 'Scarlett',
age: 37,
[Symbol()]: 'Johansson'
}
// 在原型上添加一个可枚举属性
Object.prototype.nationality = 'America'
// 在obj对象上添加一个不可枚举属性
Object.defineProperty(obj, 'occupation', {
value: 'actress',
enumerable: false
})
// 获取对象自有的可枚举属性
Object.keys(obj).map(key => {
console.log(key); // name age
})
console.log(Object.entries(obj)); // [["name", "Scarlett"], ["age", 37]]
console.log(Object.values(obj)); // ["Scarlett", 37]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Object.getOwnPropertyNames()
对象自身所有属性(不含 Symbol,但包括不可枚举属性)的键名
let obj = {
name: 'Scarlett',
age: 37,
[Symbol()]: 'Johansson'
}
// 在原型上添加一个可枚举属性
Object.prototype.nationality = 'America'
// 在obj对象上添加一个不可枚举属性
Object.defineProperty(obj, 'occupation', {
value: 'actress',
enumerable: false
})
console.log(Object.getOwnPropertyNames(obj)) // ["name", "age", "occupation"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
let obj = {
name: 'Scarlett',
age: 37,
[Symbol()]: 'Johansson'
}
// 在原型上添加一个可枚举属性
Object.prototype.nationality = 'America'
// 在obj对象上添加一个不可枚举属性
Object.defineProperty(obj, 'occupation', {
value: 'actress',
enumerable: false
})
const getAllPropertyNames = (obj) => {
let props = Object.assign([], Object.getOwnPropertyNames(obj))
// 得到所有的可枚举属性(自有的和继承的属性)
for (let key in obj) {
// 过滤自有的不可枚举属性
if (!Object.getOwnPropertyNames(obj).includes(key)) {
props.push(key)
}
}
return props;
};
getAllPropertyNames(obj); // ["name", "age", "occupation", "nationality"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Object.getOwnPropertySymbols()
对象自身的所有 Symbol 属性键名
let obj = {
name: 'Scarlett',
age: 37,
[Symbol()]: 'Johansson'
}
// 在原型上添加一个可枚举属性
Object.prototype.nationality = 'America'
// 在obj对象上添加一个不可枚举属性
Object.defineProperty(obj, 'occupation', {
value: 'actress',
enumerable: false
})
var symbolsArr = Object.getOwnPropertySymbols(obj);
for( let sym of symbolsArr){
console.log(sym, obj[sym]); // Symbol() "Johansson"
}
// 给对象添加一个不可枚举的Symbol属性
Object.defineProperties(obj, {
[Symbol('aa')]: {
value: 'localSymbol',
enumerable: false
}
})
Object.getOwnPropertySymbols(obj).map(key => {
console.log(key, obj[key]); // Symbol() "Johansson", Symbol(aa) "localSymbol"
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# Reflect.ownKeys()
对象自身(不含继承的)所有键名,不管键名是 Symbol /字符串,也不管是否可枚举
let obj = {
name: 'Scarlett',
age: 37,
[Symbol()]: 'Johansson'
}
// 在原型上添加一个可枚举属性
Object.prototype.nationality = 'America'
// 在obj对象上添加一个不可枚举属性
Object.defineProperty(obj, 'occupation', {
value: 'actress',
enumerable: false
})
Reflect.ownKeys(obj).map(key => {
console.log(key, obj[key])
})
/* 输出结果:
name Scarlett
age 37
occupation actress
Symbol() "Johansson"
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Object.values
返回对象value组成的数组
数组成员是对象本身的 (不含继承)所有可枚举属性的键值
# Object.entries
返回对象key-value组成的数组
数组成员是对象本身的 (不含继承)所有可枚举属性的键值对数组
# Object转换
# toPrimitive
JS中,若想要将对象转换成基本类型 ,再从基本类型转换为对应的String或Number,实质 是调用valueOf和toSting——拆箱转换
toPrimitive(input,preferedType)
//参数是要转换的对象,期望转换的基本类型(字符串、数字,选填,默认为number)
2
# toString、valueOf
对于String优先调用toString,若不存在,调用valueOf方法
toString返回字符串"[object Object]"
valueOf返回对象自身(历史原因,别问我为啥,可假设它根本不存在)
# toString()
Object.prototype.toString()返回表示该对象的字符串
每个对象都有toString()方法
数字转换为二进制
- 是正数
- 可能有小数
- 小数部分最多保留8位
function translate(num){
let a=num.toString(2);
let b=a.split('.');
let c='';
if(b[1].length>8){
c=b[1].slice(0,8);
return b[0]+'.'+c;
}
return a;
}
console.log(translate(1.0))
2
3
4
5
6
7
8
9
10
11
# '1'.toString()为啥可以调用?
进行以下几步
- 创建实例
- 调用实例方法
- 销毁实例
var s=new Object('1');
s.toString();
s=null;
2
3
# 123['toString'].length+123
function的length——第一个具有默认值之前的参数个数!
剩余参数不算进length的计算中
# 对象、Map
对象和 Map 可以枚举
Object本质是哈希结构的键值对的集合,只能用字符串、数字或者Symbol等简单数据类型当作键,有限制;Map 的 key 可以是任意值
Map继承Object,对Object做拓展,Map键可以是任意数据类型
对象 在堆开辟一块内存,Map的键存的就是这块内存的地址。只要地址不一样,就是不同键,解决同名属性碰撞问题,传统的Object做不到这一点
对象键值对无序
Map 能记住键的原始插入顺序
| Map | Object | |
|---|---|---|
| 意外的键 | 默认情况不包含任何键。只包含显式插入的键 | 有原型,原型链上的键名可能和自己设置的键名冲突。可以用 Object.create(null) (opens new window) 创建没有原型的对象 |
| 键的类型 | 键可以是任意值 | 的键必须是String/Symbol |
| 键的顺序 | 键有序。迭代时,Map对象以插入顺序返回 | 目前有序,但不总是这样,而且这个顺序复杂 |
| Size | 键值个数可通过 size (opens new window) 获取 | 键值对个数只能手动计算 |
| 迭代 | 可迭代的 (opens new window) | 没有 迭代协议 (opens new window),使用 JS的 for...of (opens new window) 不能直接迭代 |
| 性能 | 频繁增删键值对的场景下表现更好 | 在频繁添加和删除键值对的场景下未优化 |
| 序列化和解析 | 没有元素的序列化和解析的 | 使用 JSON.stringify() |
# WeakSet、WeakMap
WeakMap、WeakSet 的 key 是弱引用,相应对象被回收时,key 被回收,因为不可控,所以不可枚举
WeakSet 只能存储对象的集合
WeakSet 可检测循环引用,递归调用自身的函数需要一种方式 ,跟踪哪些对象已被处理
WeakMap 的 key 只能是对象(null 除外)
WeakMap 无属性读取键值的个数
# ... 与rest?
... 扩展运算符可用于 扩展 数组对象和字符串,将可迭代对象转为用 逗号 分隔的参数序列
应用
- 展开数组、对象、字符串
- 类数组对象转为数组
- 函数传参
- 用于具有Iterator接口的对象
Rest为解决传入的参数数量不一定;不会为每个变量给一个单独的名称,参数对象包含所有参数传递给函数;arguments不是真正的数组,rest参数是真实的数组
剩余参数只包含那些没有对应形参的实参,arguments包含传给函数的所有实参
# ... 应用
ES6通过扩展元素符...,好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列
函数调用的时候,将一个数组变为参数序列
将某些数据结构转为数组
合并数组
**注意:通过扩展运算符实现的是浅拷贝,修改了引用指向的值,会同步反映到新数组
# rest特点
减少代码
//以前函数
function f(a, b) {
var args = Array.prototype.slice.call(arguments, f.length);
}
// 等效于
function f(a, b, ...args) {
}
2
3
4
5
6
7
rest参数可以被解构
# arguments
另一种对象类型,也叫类对象数组(类数组)
JS的每个函数都会有一个arguments对象实例,它引用函数的实参,有length和callee属性
callee引用函数本身(返回正被执行的Function对象),实现匿名的递归函数
var sum = function (n) {
if (1 == n) {
return 1;
} else {
return n + arguments.callee(n - 1);
}
}
alert(sum(6));输出结果:21
2
3
4
5
6
7
8
# 转换为数组
- Array.prototype.slice.call()
function sum(a, b) {
let args = Array.prototype.slice.call(arguments);
console.log(args.reduce((sum, cur) => sum + cur));//args可以调用数组原生的方法啦
}
sum(1, 2);//3
2
3
4
5
function exam(a, b, c, d, e) {
// 先看看函数的自带属性 arguments 什么是样子的
console.log(arguments);
// 使用call/apply将arguments转换为数组, 返回结果为数组,arguments自身不会改变
var arg = [].slice.call(arguments);
console.log(arg);
}
exam(2, 8, 9, 10, 3);
// result:
// { '0': 2, '1': 8, '2': 9, '3': 10, '4': 3 }
// [ 2, 8, 9, 10, 3 ]
//
// 也常常使用该方法将DOM中的nodelist转换为数组
// [].slice.call( document.getElementsByTagName('li') );
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Array.prototype.splice.call(arrayLike,0)
Array.form
对一个类似数组或可迭代对象创建一个新的,浅拷贝的数组实例
function sum(a,b){
let args=Array.from(arguments);
console.log(args.reduce((sum,cur)=>sum+cur));
}
sum(1,2);
2
3
4
5
- ES6扩展运算符
function sum(a,b){
let args=[...arguments];
console.log(args.reduce((sum,cur)=>sum+cur));
}
sum(1,2);
2
3
4
5
- concat+apply or apply
function sum(a,b){
let args=Array.prototype.concat.apply([],arguments); //apply会把第二个参数展开
console.log(args.reduce((sum,cur)=>sum+cur));
}
2
3
4
古老for循环
# 💜 数组拍平
- ES6的语法,arr.flat([depth]),depth默认不填,数值为1,参数可以是Infinity,表示全部展开
- toString+replace+split
let arr = [1, [2, [3, [4, 5]]], 6];
function flatten(arr) {
let str = JSON.stringify(arr);
str=str.replace(/(\[|\])/g,'')
str = '[' + str + ']';
return JSON.parse(str);
}
console.log(flatten(arr));
2
3
4
5
6
7
8
- replace+JSON.parse
- 递归
function flatten(arr,n){
if(n<2){
return arr;
}
let res=[];
const dfs=(arr,n)=>{
if(n<2){
res.push(arr);
return res;
}
for(let item of arr){
if(Array.isArray(item) && n){
dfs(item,n-1);
}else{
res.push(item);
}
}
}
dfs(arr,n);
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 利用reduce函数迭代
const arr3 = [
[1, 2],
[3, 4],
[5, [7, [9, 10], 8], 6],
];
console.log(flatten(arr3,2));
function flatten(_arr, depth = 1) {
if (depth === 0) {
return _arr;
}
return _arr.reduce((pre, cur) =>
pre.concat(Array.isArray(cur) && depth>1 ?
flatten(cur, depth - 1) :
cur),[])
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
function flatten(_arr, depth = 1) {
if (depth === 0) {
return _arr;
}
return _arr.reduce((pre,cur)=>{
return Array.isArray(cur) && depth>1 ?
[...pre,...flatten(cur,depth-1)]:
[...pre,cur];
},[])
}
2
3
4
5
6
7
8
9
10
- 扩展运算符
while(arr.some(Array.isArray)){
arr=[].concat(...arr);
}
2
3
- toString+split+map
const str=[1,2,3,[5,6,[7,8]]].toString();
const _arr=str.split(",");
const newArr=_arr.map(item=>+item);
console.log(newArr)
2
3
4
# 数组去重
indexof、includes、filter/forEach
function unique(arr){
let res=arr.filter(function(item,index,array){
return array.indexOf(item)===index
})
return res;
}
2
3
4
5
6
Set+Array.from()
let unique=arr=>[...new Set(arr)];
let res=Array.from(new Set(arr));
2
Map
const unique=(arr)=>{
const map=new Map();
const res=[];
for(let item of arr){
if(!map.has(item)){
map.set(item,true);
res.push(item);
}
}
}
2
3
4
5
6
7
8
9
10
reduce+indexOf
const newNums3 = nums.reduce((pre, cur, index, arr) => {
return [].concat(pre, nums.indexOf(cur) === index ? cur : []);
})
2
3
双重for循环
# 🔥判断类型
# typeof
返回字符串: string、boolean、number、Object、Function、undefined、symbol(ES6)
typeof null === '' //object
console.log(typeof {}); // object
typeof undefined === '' //undefined
typeof function() {} ===‘’ //function
typeof NaN; // "number"
2
3
4
5
NaN 指“不是一个数字”(not a number),NaN 是一个“警戒值”(sentinel value,有特殊用途的常规值),用于指出数字类型中的错误情况,即“执行数学运算没有成功,这是失败后返回的结果”
NaN 和自身不相等,是唯一一个非自反(自反,reflexive,即 x === x 不成立)的值。而 NaN != NaN为 true
var a = function b() {}
console.log(typeof b)
2
# 区分null和Object
# instanceof
原理:判断构造函数的prototype属性是否出现在对象的原型链上
优点
弥补 Object. prototype. toString. call()不能判断自定义实例化对象的缺点
缺点
instanceof 只能判断对象类型
console.log(2 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); // true
console.log({} instanceof Object); //true
2
3
4
5
实现
// 利用原型链向上查找 能找到这个类的prototype的话,就为true
function myInstanceof(left, right) {
if (left === null || typeof right !== 'function') {
return false;
}
let proto = Object.getPrototypeOf(left);// 获取对象的原型
// let proto=left.__proto__;
let prototype = right.prototype; // 获取构造函数的 prototype 对象
// 判断构造函数的 prototype 对象是否在对象的原型链上
while (true) {
if (proto === null) {
return false;
}
if (proto === prototype) {
return true;
}
proto = Object.getPrototypeOf(proto);
}
}
const Person = function () {
}
const p1 = new Person()
console.log(myInstanceof(p1, Person));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Object.prototype.toString.call()
使用Object的原型方法toString判读数据类型
优点:能判断所有基本数据类型,即使 是 null 和 undefined
缺点:不能精准判断自定义对象,对于自定义对象返回[object Object]
const handleType=Object.prototype.toString;
console.log(handleType.call(true));//'[object Boolean]'
console.log(handleType.call([]));//'[object Array]'
console.log(handleType.call(function(){}));//'[object Function]'
console.log(handleType.call({}));//'[object Object]'
console.log(handleType.call(undefined));//'[object Undefined]'
console.log(handleType.call(null));//'[object null]'
Object.prototype.toString.call(new RegExp()); // [object RegExp]
2
3
4
5
6
7
8
9
为啥obj.toString()的结果和Object.prototype.toString.call(obj)的结果不一样?
因为toString是Object的原型方法,Array,Function作为Object的实例,重写了toString方法。不同对象类型调用toString时,调用的是对应重写后的toString方法(function类型返回内容为函数体的字符串,Array类型返回元素组成的字符串...),不会去调用Object上原型toString方法(返回对象具体类型),因此需要使用Object原型上的toString方法才能得到想要对象的具体类型
# constructor
每一个对象实例都可以通过 constrcutor 对象访问它的构造函数 ,JS 中内置了一些构造函数:Object、Array、Function、Date、RegExp、String等。可以根据数据的 constrcutor 是否与其构造函数相等判断
注意:若创建一个对象改变它的原型,constructor就不能用来判断数据类型了
var arr = [];
var obj = {};
var date = new Date();
var num = 110;
var str = 'Hello';
var getName = function() {};
var sym = Symbol();
var set = new Set();
var map = new Map();
arr.constructor === Array; // true
obj.constructor === Object; // true
date.constructor === Date; // true
str.constructor === String; // true
getName.constructor === Function; // true
sym.constructor === Symbol; // true
set.constructor === Set; // true
map.constructor === Map // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
对于null和undefined无效,constructor不太稳定,prototype可被重写导致原有constructor丢失,Object被覆盖也会影响判断结果
# 判断数组类型?
- instanceof 判断对象在其原型链上是否存在构造函数的prototype属性
- Array.isArray(arr) 静态方法,Array.prototype也是一个数组
- 优点:检测 Array 实例时,Array. isArray 优于 instanceof
- 缺点:只能判别数组
- Object.prototype.toString.call() (最靠谱)输出格式[object 对象数据类型]
- arr.proto===Array.prototype
# typeof、instanceof
typeof 返回字符串,表示未经计算的操作数的类型
instanceof 检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上
原理——顺着原型链找,直到找到相同的原型对象,返回true,否则为false
区别如下:
typeof返回变量的基本类型,instanceof返回布尔值instanceof可准确判断复杂引用数据类型,但不能正确判断基础数据类型typeof可以判断基础数据类型(null除外),但引用数据类型中,除了function类型以外,其他的无法判断
上述两种方法都有弊端,并不能满足所有场景的需求
如果需要通用检测数据类型,可以采用Object.prototype.toString,统一返回格式“[object Xxx]”的字符串
# 🌰 深浅拷贝
浅拷贝只能拷贝一层对象
深拷贝能解决无限极对象嵌套问题
# 浅拷贝
新的对象对原始对象的属性精确拷贝,如拷贝的基本类型,拷贝的就是基本数据类型的值;如拷贝的引用类型,拷贝内存地址
如果其中一个对象的引用内存地址改变,另一个对象也会变化
# Object.assing()
ES6的object的方法,可用于对象合并
Object.assign(target, ...sources)
target是目标对象,sources是源对象
let target = {a: 1};
let object2 = {b: {d : 2}};
let object3 = {c: 3};
Object.assign(target, object2, object3);
console.log(target); // {a: 1, b: {d : 2}, c: 3}
object2.b.d = 666;
console.log(target); // {a: 1, b: {d: 666}, c: 3}
2
3
4
5
6
7
- 若目标和源对象有同名属性,或 多个源对象有同名属性,后面覆盖前面属性
- 若该只有一个参数,参数为对象时直接返回;不是对象先转为对象返回
- null和undefined不能转为对象,因此第一参数不能为null/undefined
- 不会拷贝对象的继承属性,不会拷贝对象的不可枚举属性,可拷贝Symbol属性
Object.assign()循环遍历原对象可枚举属性,copy的方式赋值给目标对象的属性
# 扩展运算符
let obj1 = {a:1,b:{c:1}}
let obj2 = {...obj1};
obj1.a = 2;
console.log(obj1); //{a:2,b:{c:1}}
console.log(obj2); //{a:1,b:{c:1}}
obj1.b.c = 2;
console.log(obj1); //{a:2,b:{c:2}}
console.log(obj2); //{a:1,b:{c:2}}
2
3
4
5
6
7
8
若属性都是基本类型,使用扩展运算符更方便
# 数组浅拷贝
# Array.prototype.slice()
slice的2个参数都不写,不修改原数组
let arr = [1,2,3,4];
console.log(arr.slice()); // [1,2,3,4]
console.log(arr.slice() === arr); //false
2
3
- 若该对象是个对象引用,slice会拷贝这个对象引用。2个对象都引用了同一个对象。若引用的对象改变,新旧数组中的这个元素也会改变
- 对字符串、数字和布尔值说,slice会拷贝这些值。在别的数组中修改这些值不会影响另一个数组
若向2个数组任一个添加新元素,另一个不受影响
# Array.prototype.concat()
若省略了concat所有参数,会返回调用此方法的现存数组的浅拷贝
let arr = [1,2,3,4];
console.log(arr.concat()); // [1,2,3,4]
console.log(arr.concat() === arr); //false
2
3
concat不改变this或任何作为参数提供的数组,而是返回一个浅拷贝,是原始数组的副本
- 对象引用:concat将对象引用copy到新数组,原始/新数组都引用相同对象
- 数据类型如字符串、数字和boolean:concat将字符串和数字的值copy到新数组
# 应用场景
对于一层结构的Array和Object想要拷贝一个副本时使用
# 手撕
- 对基础类型做最基本拷贝
- 对引用类型开辟新的存储,拷贝一层对象属性
// 浅拷贝的实现;
function shallowCopy(object) {
// 只拷贝对象
if (!object || typeof object !== "object") return;
// 根据 object 的类型判断是新建一个数组还是对象
let newObject = Array.isArray(object) ? [] : {};
// 遍历 object,并且判断是 object 的属性才拷贝
for (let key in object) {
if (object.hasOwnProperty(key)) {
newObject[key] = object[key];
}
}
return newObject;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
所有的浅拷贝只能拷贝一层。如果存在对象嵌套,浅拷贝无能为力。深拷贝就是为了解决这个问题而生,它能解决多层对象嵌套问题,彻底实现拷贝
# 深拷贝
简单数据类型直接拷贝值,引用数据类型,在堆内存开辟内存存放复制的对象,把原有对象类型数据拷贝过来,两个对象相互独立,属于不同内存地址,修改其中一个,另一个不改变
# JSON.stringify()
JSON.parse(JSON.stringify())
将对象序列化为JSON字符串,再反序列化,生成对象
使用最多,也最简单
let obj1 = {
a: 0,
b: {
c: 0
}
};
let obj2 = JSON.parse(JSON.stringify(obj1));
obj1.a = 1;
obj1.b.c = 1;
console.log(obj1); // {a: 1, b: {c: 1}}
console.log(obj2); // {a: 0, b: {c: 0}}
2
3
4
5
6
7
8
9
10
11
- 无法解决循环引用,对象成环(obj[key]=obj)
- 无法拷贝特殊对象 RegExp Date Set Map 等
- 忽略undefined、symbol和function(非安全类型的值)
- 无法拷贝不可枚举属性
- 无法拷贝对象原型链
- NaN、Infinity变成null
# lodash库
var _ = require('lodash');
var obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
var obj2 = _.cloneDeep(obj1);
console.log(obj1.b.f === obj2.b.f);// false
2
3
4
5
6
7
8
lodash源代码
/**
* value:需要拷贝的对象
* bitmask:位掩码,其中 1 是深拷贝,2 拷贝原型链上的属性,4 是拷贝 Symbols 属性
* customizer:定制的 clone 函数
* key:传入 value 值的 key
* object:传入 value 值的父对象
* stack:Stack 栈,用来处理循环引用
*/
function baseClone(value, bitmask, customizer, key, object, stack) {
let result
// 标志位
const isDeep = bitmask & CLONE_DEEP_FLAG // 深拷贝,true
const isFlat = bitmask & CLONE_FLAT_FLAG // 拷贝原型链,false
const isFull = bitmask & CLONE_SYMBOLS_FLAG // 拷贝 Symbol,true
// 自定义 clone 函数
if (customizer) {
result = object ? customizer(value, key, object, stack) : customizer(value)
}
if (result !== undefined) {
return result
}
// 非对象
if (!isObject(value)) {
return value
}
const isArr = Array.isArray(value)
const tag = getTag(value)
if (isArr) {
// 数组
result = initCloneArray(value)
if (!isDeep) {
return copyArray(value, result)
}
} else {
// 对象
const isFunc = typeof value == 'function'
if (isBuffer(value)) {
return cloneBuffer(value, isDeep)
}
if (tag == objectTag || tag == argsTag || (isFunc && !object)) {
result = (isFlat || isFunc) ? {} : initCloneObject(value)
if (!isDeep) {
return isFlat
? copySymbolsIn(value, copyObject(value, keysIn(value), result))
: copySymbols(value, Object.assign(result, value))
}
} else {
if (isFunc || !cloneableTags[tag]) {
return object ? value : {}
}
result = initCloneByTag(value, tag, isDeep)
}
}
// 循环引用
stack || (stack = new Stack)
const stacked = stack.get(value)
if (stacked) {
return stacked
}
stack.set(value, result)
// Map
if (tag == mapTag) {
value.forEach((subValue, key) => {
result.set(key, baseClone(subValue, bitmask, customizer, key, value, stack))
})
return result
}
// Set
if (tag == setTag) {
value.forEach((subValue) => {
result.add(baseClone(subValue, bitmask, customizer, subValue, value, stack))
})
return result
}
// TypedArray
if (isTypedArray(value)) {
return result
}
// Symbol & 原型链
const keysFunc = isFull
? (isFlat ? getAllKeysIn : getAllKeys)
: (isFlat ? keysIn : keys)
const props = isArr ? undefined : keysFunc(value)
// 遍历赋值
arrayEach(props || value, (subValue, key) => {
if (props) {
key = subValue
subValue = value[key]
}
assignValue(result, key, baseClone(subValue, bitmask, customizer, key, value, stack))
})
// 返回结果
return result
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
# 应用场景
复制深层次的object数据结构
# 手撕
# 基础递归
for-in遍历属性,基本类型则直接copy,引用类型则递归调用
function deepCopy(object) {
if (!object || typeof object !== "object") {
return;
}
let newObject = Array.isArray(object) ? [] : {};
for (let key in object) {
if (object.hasOwnProperty(key)) {
newObject[key] = typeof object[key] === "object" ?
deepCopy(object[key]) :
object[key];
}
}
return newObject;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 不能复制不可枚举属性及 Symbol 类型
- 只能对普通引用类型值做递归复制,Date、RegExp、Function 等引用类型不能正确拷贝
- 可能存在循环引用
# 优化递归
# 第一版本
Reflect.ownKeys()解决不能复制不可枚举属性及 Symbol 问题。返回由目标对象自身属性键组成的数组。返回值等同于:Object.getOwnPropertyNames(target).concat(Object.getOwnPropertySymbols(target))- 参数为 Date、RegExp 时,直接生成新实例返回
Object.getOwnPropertyDescriptors()获得对象所有属性及特性。返回给定对象所有属性的信息,包括有关getter和setter的信息。允许创建对象副本并在复制所有属性(包括getter和setter)时克隆它Object.create()创建新对象,继承传入原对象的原型链。使用现有的对象提供新创建对象的__proto__- WeakMap 类型作为 Hash 表,是弱引用类型,防止内存泄漏,用来检测循环引用,如存在循环,则引用直接返回 WeakMap 存储的值。WeakMap的特性是,保存在其中的对象不影响垃圾回收,如WeakMap保存节点在其他地方没被引用,即使它还在WeakMap中也会被垃圾回收。深拷贝过程,所有引用对象都是被引用,为解决循环引用,深拷贝过程,希望有个数据结构记录每个引用对象有没有被使用,但深拷贝结束之后这个数据能自动垃圾回收,避免内存泄漏
代码实现:
function deepClone (obj, hash = new WeakMap()) {
// 日期对象直接返回一个新的日期对象
if (obj instanceof Date){
return new Date(obj);
}
//正则对象直接返回一个新的正则对象
if (obj instanceof RegExp){
return new RegExp(obj);
}
//如果循环引用,就用 weakMap 来解决
if (hash.has(obj)){
return hash.get(obj);
}
// 获取对象所有自身属性的描述
let allDesc = Object.getOwnPropertyDescriptors(obj);
// 遍历传入参数所有键的特性
let cloneObj = Object.create(Object.getPrototypeOf(obj), allDesc)
hash.set(obj, cloneObj)
for (let key of Reflect.ownKeys(obj)) {
if(typeof obj[key] === 'object' && obj[key] !== null){
cloneObj[key] = deepClone(obj[key], hash);
} else {
cloneObj[key] = obj[key];
}
}
return cloneObj
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
测试
let obj = {
num: 1,
str: 'str',
boolean: true,
und: undefined,
nul: null,
obj: { name: '对象', id: 1 },
arr: [0, 1, 2],
func: function () { console.log('函数') },
date: new Date(1),
reg: new RegExp('/正则/ig'),
[Symbol('1')]: 1,
};
Object.defineProperty(obj, 'innumerable', {
enumerable: false, value: '不可枚举属性'
});
obj = Object.create(obj, Object.getOwnPropertyDescriptors(obj))
obj.loop = obj // 将loop设置成循环引用的属性
let cloneObj = deepClone(obj)
console.log('obj', obj)
console.log('cloneObj', cloneObj)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
缺点——Map和Set无法拷贝
# 第二版本
/**
* 深拷贝 避免循环引用
*/
const deepCopy2 = (target, hash = new WeakMap()) => {
if (target === null) {
return target;
}
if (target instanceof Date) {
return new Date(target);
}
if(target instanceof RegExp){
return new RegExp(target);
}
if(typeof target!=='object'){
return target;
}
if (hash.get(target)) {
// 避免循环引用
return target;
}
let cloneObj=new target.constructor();
hash.set(target, true);
const cloneTarget = Array.isArray(target) ? [] : {};
for (let prop in target) {
if (target.hasOwnProperty(prop)) {
cloneTarget[prop] = deepCopy2(target[prop], hash);
}
}
return cloneTarget;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 第三版本
function deepClone(source, map = new WeakMap()) { // 传入一个WeakMap对象用于记录拷贝前和拷贝后的映射关系
if (typeof source !== "object") { // 非对象类型(undefined、boolean、number、string、symbol),直接返回原值即可
return source;
}
if (source === null) { // 为null类型的时候
return source;
}
if (source instanceof Date) { // Date类型
return new Date(source);
}
if (source instanceof RegExp) { // RegExp正则类型
return new RegExp(source);
}
if (map.get(source)) { // 如果存在相互引用,则从map中取出之前拷贝的结果对象并返回以便形成相互引用关系
return map.get(source);
}
let result;
if (Array.isArray(source)) { // 数组
result = [];
map.set(source, result); // 数组也会存在相互引用
source.forEach((item) => {
result.push(deepClone(item, map)); // 必须传入第一次调用deepClone时候创建的map对象
});
return result;
} else { // 为对象的时候
result = {};
map.set(source, result); // 保存已拷贝的对象
const keys = [...Object.getOwnPropertyNames(source), ...Object.getOwnPropertySymbols(source)]; // 取出对象的key以及symbol类型的key
keys.forEach(key => {
let item = source[key];
result[key] = deepClone(item, map); // 必须传入第一次调用deepClone时候创建的map对象
});
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 操作符
+和 - 一样,会将其操作数转化为数值,返回转化后的值
- 若操作数是数值,它啥都不做
- 若操作数不能转化为数组,返回NaN
- 不可用于BigInt,BigInt不能转化为数值
按位与&
- 判断奇偶,最末位是0/1,是0就是偶数,1就是奇数,用
if ((i & 1) === 0)代替if (i % 2 === 0)来判断a是不是偶数 - 清零
1 + {} // "1[object Object]"
true + false // 1 布尔值会先转为数字,再进行运算
1 + null // 1 null会转化为0,再进行计算
1 + undefined // NaN undefined转化为数字是NaN
2
3
4
逻辑非 !
首先将操作数转化为布尔值,再对其取反
- 对象,返回false
- 空字符串,返回true
- 非空字符串,返回false
- 数值0,返回true
- 非0数值,返回false
- null,返回true
- NaN,返回true
- undefined,返回true
可用户将任何值转化为布尔值,使用2个!,相当于调用了Boolean()
!!"blue" // true
!!0; // false
!!NaN // false
!!"" // false
!!12345 // true
2
3
4
5
关系操作符
遵循规则
- 2个操作数都是数值,进行数值比较
- 2个操作数都是字符串,比较字符串对应的字符编码值
- 若一个操作数是数值,则将另一个操作数转换为数值,执行数值比较
- 若一个操作数是对象,调用对象的valueOf(),根据前面的规则比较
- 若一个操作数是布尔值,先将其转换为数值,再比较
# 💙 类型转换
6种基本类型 null undefined number stringify boolean symbol
1种引用类型 object
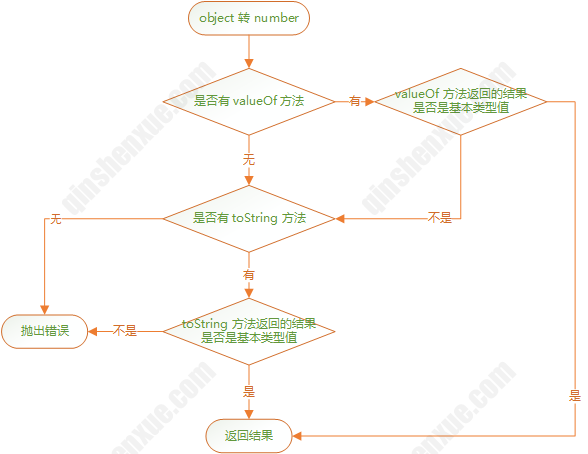
# 对象转换为基本类型
- 对象转换为字符串
优先调用toString
// 模拟 toString 返回的不是基本类型值,valueOf 返回的基本类型值
var obj = {
toString: function() {
return {}
},
valueOf:function(){
return null
}
}
String(obj) // "null"
2
3
4
5
6
7
8
9
10
11
- 对象转换为数字
先判断valueOf方法,再判断toString方法
// valueOf 和 toString 返回的都不是基本类型值
var obj = {
valueOf:function(){
return {}
},
toString:function(){
return {}
}
}
Number(obj) // Uncaught TypeError: Cannot convert object to primitive value
2
3
4
5
6
7
8
9
10
11
Object.create(null)创建的对象没有valueOf和toString方法,因此转换报错
一般,我们不会重写valueOf和toString,大部分对象valueOf返回的仍然是对象,因此对象转换为基本类型值可以直接看toString返回的值
- 转换为对象
优先调用toString,若没有重写toString 则调用valueOf,若2者均没有被重写,按toString输出
# 显式强制类型转换
- 转换为字符串
如果对象有自定义toString方法,则返回toString方法的结果,若是toString返回的结果不是基本类型值,报错TypeError
var obj = {
toString:function(){
return {}
}
}
String(obj) // Uncaught TypeError: Cannot convert object to primitive value
obj + "" // Uncaught TypeError: Cannot convert object to primitive value
obj.toString() // {}
2
3
4
5
6
7
8
9
10
11
- 转换为布尔类型
null undefined false +0 -0 NaN ""
其他情况都是true
- 转换为数字类型
Number('') // 0
Number(null) // 0
Number(undefined) // NaN
Number(true) // 1
Number(false) // 0
2
3
4
5
对象 先被转换为相应基本类型值,再转换
Number([]) // 0
// [] valueOf 返回的是 [],因此继续调用 toString 得到基本类型值 "",转换为数字为 0
2
# 隐式强制类型转换
| 被比较值 B | |||||||
|---|---|---|---|---|---|---|---|
| Undefined | Null | Number | String | Boolean | Object | ||
| 被比较值 A | Undefined | true | true | false | false | false | IsFalsy(B) |
| Null | true | true | false | false | false | IsFalsy(B) | |
| Number | false | false | A === B | A === ToNumber(B) | A=== ToNumber(B) | A== ToPrimitive(B) | |
| String | false | false | ToNumber(A) === B | A === B | ToNumber(A) === ToNumber(B) | ToPrimitive(B) == A | |
| Boolean | false | false | ToNumber(A) === B | ToNumber(A) === ToNumber(B) | A === B | ToNumber(A) == ToPrimitive(B) | |
| Object | false | false | ToPrimitive(A) == B | ToPrimitive(A) == B | ToPrimitive(A) == ToNumber(B) | A === B |
ToNumber(A) 在比较前将A 转换为数字,与 +A(单目运算符 +)效果相同。ToPrimitive(A)尝试调用 A 的A.toString() 和 A.valueOf() ,将 A 转换为原始值(Primitive)
- 转换为字符串
x+"",将x转换为字符串,+ 运算符其中一个操作数是字符串,执行字符串拼接操作
对象和字符串拼接时,**对象转为基本类型,再转为数字,**先判断valueOf,再判断toString
var obj = {
valueOf: function() {
return 1
},
toString: function() {
return 2
}
}
obj + '' // '1'
2
3
4
5
6
7
8
9
10
- 转换为布尔值
发生布尔值隐式强制类型转换的情况
- if (..)语句中的条件判断表达式
- for ( .. ; .. ; .. )语句中的条件判断表达式(第二个)
- while (..)和do..while(..)循环中的条件判断表达式
- ? :中的条件判断表达式
- 逻辑运算符 ||(逻辑或)和 &&(逻辑与)左边的操作数(作为条件判断表达式)
alert(3>5 || 'a' && 'b')
- 转换为数字类型
+ '2' // 2
'2' - 0 // 2
'2' / 1 // 2
'2' * 1 // 2
+ 'x' // NaN
'x' - 0 // NaN
'x' / 1 // NaN
'x' * 1 // NaN
1 + '2' // '12'
1 + + '2' // 3 即:1 + (+ '2')
2
3
4
5
6
7
8
9
10
11
12
13
# ==、===
== 允许在比较中强制类型转换, === 不允许
== 比较时 ,2个操作符都会进行强制类型转换,再确定是否相等
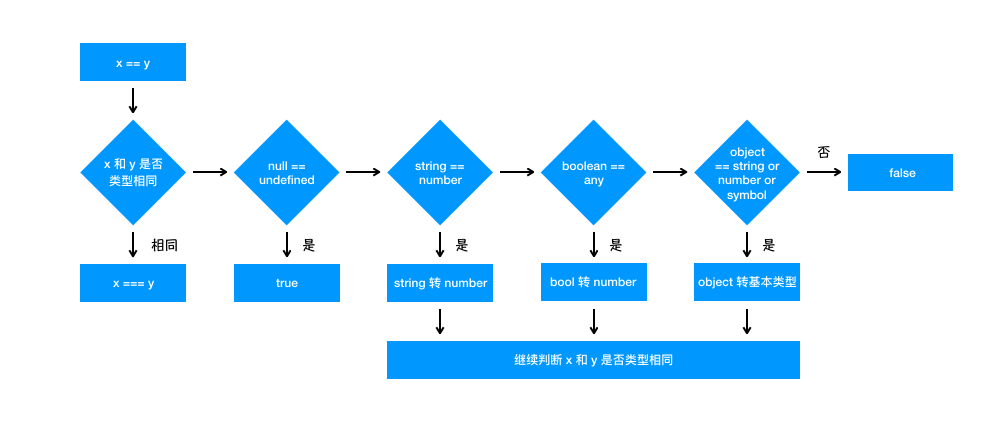
比较规则
- 判断二者类型是否相同,相同则比较大小
- 类型不同,进行类型转换
- null和undefined,返回true,其**他类型和 null 均不相等**,undefined 也是
- String和number,将字符串转换为number
- 若其中一方是boolean,将boolean转为number再判断
- 若其中一方是object,另一方是string、number或Symbol,将object转为原始类型再判断,对象转换优先级最高
注意!
若一个是NaN,相等运算符返回false,不相等运算符返回true
对于(!=),只有在强制类型转换后不相等才返回 false
对于(===),只有当2个操作数 数据类型和值都相等时,返回true,它不会转化数据类型
对于(!==),只有2个操作数在不进行类型转化的情况下是不相等的,才返回true
null+1=1
undefined+1=NaN
1 + {} = "1[object Object]"//一个操作数是对象,调用对象的 valueOf 转成原始值,如果没有该方法或调用后仍是原始值,则调用 toString 方法
2
3
null转换为number=0
undefined转换为number=NaN
其它运算只要其中一方是数字,另一方就转为数字
'a' + + 'b' // -> "aNaN"
// 因为 + 'b' -> NaN
// 你也许在一些代码中看到过 + '1' -> 1
2
3
![]=='' //true
[]=='' //true
[]==![] //true
{}=={}
2
3
4
5、特殊情况
NaN == NaN // false
-0 == +0 // true
!NaN //true
2
3
两个对象比较,判断两个对象是否是同一个引用
"0" == false // true
// false 转换为数字 0,等式变为 "0" == 0
// 类型不一致继续转换,"0" 转换为数字 0,变为 0 == 0
false == [] // true
// [] 转换基本类型值 [].toString() 为 "",变为 "" == false
// 类型不一致,继续转换,false 转换为数字为 0,变为 "" == 0
// 类型不一致,继续转换,第1条规则,"" 转换为数字,结果为 0,变为 0 == 0
0 == [] // true
// [] 转换基本类型值,[].toString(),结果为 "",等式变为 0 == ""
// 类型不一致,继续转换,"" 转换为数字,结果为 0,等式变为 0 == 0
2
3
4
5
6
7
8
9
10
11
12
13
14
参考文档https://dorey.github.io/JavaScript-Equality-Table/
# 优先级
左结合(左到右)——把左边的子表达式加上小括号 (a OP b) OP c
右结合(右到左)—— a OP (b OP c)
赋值运算符是右结合
a=b=5 相当于 a=(b=5)
只有幂运算符是右结合的,其他算术运算符都是左结合
6 / 3 / 2 与 (6 / 3) / 2 相同,除法左结合。幂运算符右结合,所以 2 ** 3 ** 2 与 2 ** (3 ** 2) 相同
判断执行顺序时,优先级在结合性之前,混合求除法和幂,求幂先于除法
2 ** 3 / 3 ** 2 的结果是 0.8888888888888888,相当于 (2 ** 3) / (3 ** 2)
逻辑非!的优先级比全等===高
点运算符(.)优先级高于new(无参数列表)
[] 、函数调用 优先级和new(带参数列表)一样高
new Foo()优先级大于 new Foo
new Foo().getName相当于 (new Foo()).getName()
new Foo.getName()相当于 new (Foo.getName)()
展开语法不是运算符,因此没有优先级
# 🌰 0.1+0.2 === 0.3?
JS数字存储采用IEEE754双精度存储,小数使用64位固定长度表示,其中1位表示符号位,11位表示指数位,剩下52尾数位
总结
- 精度损失 0.1和0.2转换为二进制出现无限循环情况,JS 最大可存储53位有效数字,超过此长度会被截取掉,造成精度损失
- 对2个64位双精度格式数据计算时,先对阶(将阶码对齐,将小数点位置对齐),小阶数在对齐时,有效数字向右移动,超过有效位数的位被截取掉
- 两个数据阶码对齐后加运算,结果可能超过53位有效数字,超过的位被截取掉
相加后因浮点数小数位限制截断的二进制数字转换为十进制时变成0.30000000000000004(15个0)
# 让其相等?
转换为整数,结果转换为对应小数
设置误差范围(将结果与右边相减,若结果小于一个极小数,则正确)
- 极小数可以是 ES6 的
Number.EPSILON,实质是一个可接受的最小误差范围, 一般为Math.pow(2, -52)
- 极小数可以是 ES6 的
function isEqual(a, b) {
return Math.abs(a - b) < Number.EPSILON;
}
console.log(isEqual(0.1 + 0.2, 0.3)); // true
2
3
4
- 转成字符串,对字符串做加法运算
parseFloat((0.1 + 0.2).toFixed(10))
//toFixed四舍五入
2
- toPrecision转换成数字,以指定精度返回该数值对象的字符串表示,四舍五入到参数指定的数字位数
function strip(num, precision = 12) {
return parseFloat(num.toPrecision(precision));
}
let x=strip(0.30000000000000004,18)
console.log(x)
//默认去掉最低位的0
2
3
4
5
6
- 将计算数字提升10的N次方
(0.1*1000+0.2*1000)/1000==0.3
//true
2
+(0.1+0.2).toFixed(2)
//一元加号强制转换为数字
2
- Math.js
# bind、call、apply
# call、apply
改变函数体内部this指向
第一个参数都是 this 的指向对象,第二个参数差别:
call 参数按顺序传递, obj.myFun.call(db,'成都', ... ,'string' )
apply参数为数组,obj.myFun.apply(db,['成都', ..., 'string' ])
用法
数组追加
var array1 = [12 , "foo" , {name :"Joe"} , -2458];
var array2 = ["Doe" , 555 , 100];
Array.prototype.push.apply(array1, array2);
/* array1 [12 , "foo" , {name "Joe"} , -2458 , "Doe" , 555 , 100] */
2
3
4
获取数组最大/小值
var a=[1,2,3,4];
let ans=Math.max.apply(null, a);
2
验证是否为数组(前提是toString()未被重写)
Object.prototype.toString.call(obj)==='[object Array]';
类数组转换为数组
let arr=Array.prototype.slice.call(arguments);
每个function实例都有call、apply属性??是的!
# bind
bind 除了返回一个新函数以外,参数和 call 一样
注意:将null undefined 作为第一参数时,被忽略
严格模式下 this为undefined
多次调用bind()无效
当 bind 返回的函数作为构造函数 时,bind 指定的this失效,但传入的参数有效
var value = 2;
var foo = {
value: 1
};
function bar(name, age) {
this.habit = 'shopping';
console.log(this.value);
console.log(name);
console.log(age);
}
bar.prototype.friend = 'kevin';
var bindFoo = bar.bind(foo, 'daisy');
var obj = new bindFoo('18');
// undefined 绑定的value失效!!
// daisy
// 18
console.log(obj.habit);
console.log(obj.friend);
// shopping
// kevin
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
实现
Function.prototype.bind2 = function (context) {
if (typeof this !== "function") {
throw new Error("Function.prototype.bind - what is trying to be bound is not callable");
}
var self = this;
//获取bind2函数从第二个到最后一个参数
var args = Array.prototype.slice.call(arguments, 1);
var fNOP = function () {};
var fBound = function () {
//bind返回的函数传入的参数
var bindArgs = Array.prototype.slice.call(arguments);
return self.apply(this instanceof fBound ? this : context, args.concat(bindArgs));
}
//直接修改fBound.prototype时,也会直接修改 绑定函数的 prototype???
//fBound.prototype=this.prototype 为了fBound构造的实例能继承绑定函数原型中的值
fNOP.prototype = this.prototype;
fBound.prototype = new fNOP();
return fBound;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
为啥fBound.prototype直接修改也会修改 绑定函数的 prototype?
Function.prototype.bind2 = function (context) {
var self = this;
var args = Array.prototype.slice.call(arguments, 1);
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments);
self.apply(this instanceof fBound ? this : context, args.concat(bindArgs));
}
fBound.prototype = this.prototype;
return fBound;
}
function bar() {}
var bindFoo = bar.bind2(null);
bindFoo.prototype.value = 1;
console.log(bar.prototype.value) // 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
相当于 用原型式继承 包了一层,实现2个实例间原型的数据共享,但又能 避免return的函数原型直接修改原型,导致绑定函数的原型也被修改
# VO、AO
Variable Object
Activation Object
2
AO和VO其实是同一个东西,处于不同 生命周期 罢了
只是VO是规范上/引擎实现的,不可在JS环境中访问,只有进入 执行上下文 中,VO被激活,所以才叫AO呐
变量对象是与执行上下文相关的数据作用域,存储 在上下文中定义的 变量和函数声明
只有处于函数调用栈 栈顶的执行上下文中的VO,才会变成AO
# ✅this
调用函数时 创建一个执行环境,this在运行时根据函数的执行环境绑定,它允许函数在内部引用上下文中的执行变量,使函数更加优雅简洁
new>显示>隐式>默认
this指向在 执行上下文被创建时确定,函数执行过程中,一旦this指向被确定就不可更改
在一个函数上下文中,this由调用者提供。如果调用者函数,被某一个对象所拥有,该函数在调用时,this指向该对象。如果函数独立调用,该函数内部的this指向undefined,在非严格模式中,this自动指向全局对象
// demo03
var a = 20;
var obj = {
a: 10,
c: this.a + 20,
fn: function () {
return this.a;
}
}
console.log(obj.c); //40
console.log(obj.fn()); //10
2
3
4
5
6
7
8
9
10
11
12
**单独的{}不形成新的作用域,**这里的this.a,并没有作用域的限制,仍然处于全局作用域之中
定义对象的大括号{}不是一个单独的执行环境,依旧处于全局环境
# 绑定规则
1、默认
2、隐式
考虑 调用位置是否上下文对象
若函数调用当前存在多个对象,this指向距离自己最近的对象
隐式丢失
作为参数传递和变量赋值,会使参数或变量直接指向函数,丢失this指向
如何解决?
使用隐式绑定:将函数绑定至对象属性,调用时通过对象属性直接调用,弱赋值到其他对象,需将正对象赋值过去,不然会丢失 初次绑定的环境
3、显式
call、bind和apply 改变this
4、new
创建一个新的对象将其绑定到foo()调用的this
5、箭头函数
从自己的作用域链的上一层继承this
# 全局上下文
全局对象
- 可通过this访问
- 是Object实例化的一个对象
- 预定了一堆函数和属性
- 作为全局变量的宿主
- 客户端,this.window==this
全局上下文中的变量对象就是全局对象!!
非严格模式和严格模式中this指向顶层对象
// 在浏览器中,全局对象为 window 对象:
console.log(this === window); // true
this.a = 37;
console.log(window.a); // 37
2
3
4
5
# 函数上下文
严格模式下 this 为undefined,非严格模式下为 window
活动对象在进入函数上下文时被创建,通过arguments初始化
执行上下文代码分2个阶段
- 进入执行上下文
- 执行
# 进入执行上下文
变量对象包括
- 函数的所有形参
- 键值对形式的变量对象被创建
- 无 实参,值设为 undefined
- 函数声明
- 名称和对应值(函数对象 function-Object)组成变量对象的属性被创建
- 若vo 已存在同名 属性,则完全替换
- 变量声明
- 名称和对应值(undefined)组成vo被创建
- 若变量名称和已声明形参/函数相同,则 变量声明 不会干扰已存在的这类属性———所以 再次声明的var变量不会覆盖掉已变量提升的函数声明!!
js在函数预处理阶段的解析顺序:
函数参数->内部声明式函数->内部var声明的变量
2
# 代码执行
顺序执行代码并 修改 VO的值
# 箭头函数
标准函数中this引用的是 方法调用 时的上下文
箭头函数的this 为定义时所在的 this,不绑定this (因为箭头函数没有Constructor),捕获其所在上下文的 this 作为自己的 this
若包裹在函数中,就是函数调用时所在的对象,全局就是window,箭头函数的this是外层代码块的this,固定不变
# 特点
- 没有自己的this
- 继承来的this不会变
- 没有arguments,获得的arguments是外层函数的arguments
- call apply 和bind无法改变this
# 啥时候不能用
- 对象方法不适用 箭头函数
- 原型方法 不适用
- 不可用于构造函数,没有new关键字
- 不用于 动态上下文的回调
const btn1 = document.getElementById('btn1')
btn1.addEventListener('click', () => {
this.innerHTML = 'clicked'
//此处 this指向 window,而不是 button
})
2
3
4
5
- Vue 生命周期和method不能用
React可以用
因为 Vue本质是对象,React组件(class)本质是ES6的class
- 不能用于generator函数,没有yield关键字
不适用箭头函数如何使其指向实例
函数定义在prototype就能获得this指向
# bind 函数
在 Function的原型链上,Function.prototype.bind 通过 bind 函数绑定后,函数将绑定在其第一个参数对象上,除非使用new时被改变,其他情况不会改变,无论在啥情况下被调用
!!多次bind调用,this指向依旧是第一次的
# setTimeout、setInterval
for(var i=0;i<5;i++){
;(function(i){
setTimeout(function(){
console.log(i)
},i*1999)
})()
}
2
3
4
5
6
7
**延时函数内部回调函数this 指向全局对象window
introduction() === introduction.call() ,前者是后者的简写!call()中的第一个传参 指定这个函数中的 this 指向!
function introduction(name) {
console.log('你好,'+ name +' 我是' + this.name);
}
var zhangsan = {
name:'张三'
}
introduction.call(zhangsan,"李四") // 你好 李四, 我是 张三 call
introduction.apply(zhangsan,["李四"]) // 你好 李四, 我是 张三 apply
intro = introduction.bind(zhangsan)
intro("李四")// 你好 李四, 我是 张三 bind
2
3
4
5
6
7
8
9
10
bind()返回一个绑定新环境的function,等着被调用
# 🌈 函数
# new Function
let func = new Function ([arg1, arg2, …argN], functionBody);
let sum = new Function('a', 'b', 'return a + b');
console.log(sum(1, 2));
2
3
4
5
- 无效的 JSON 对象字符串合法化
- 模板字符串作为模板
- 闭包和上下文
new Function body 参数变量上下文是全局的,不是私有,没有闭包
function getFunc() {
let value = 'yh';
let func = new Function('console.log(value)');
return func;
}
getFunc()(); // error: value is not defined
2
3
4
5
6
7
常规函数语法没有问题
function getFunc() {
let value = 'yh';
let func = function () {
console.log(value)
};
return func;
}
getFunc()(); // print 'yh'
2
3
4
5
6
7
8
9
new Function 语 RegExp ,使用字符串作为正则表达式的内容, 适合动态匹配/ 增加代码混淆
# 函数声明
使用function的函数声明比函数表达式优先提升
函数声明比变量声明 更优先执行顺序
无论在什么位置声明了函数,都可以在同一个执行上下文中直接使用该函数
# 函数表达式
也叫匿名函数—— 没有被显式赋值操作的函数。使用场景,多为一个参数传入另一个函数中
函数自执行,其实是匿名函数的一种应用
函数表达式使用 var/let/const声明,确认他是否可正确使用时 必须依照var/let/const的规则判断——变量声明
var声明,其实进行两步操作
// 变量声明
var a = 20;
// 实际执行顺序
var a = undefined; // 变量声明,初始值undefined,变量提升,提升顺序次于function声明
a = 20; // 变量赋值,该操作不会提升
2
3
4
5
6
同样道理,当使用变量声明的方式声明函数时——函数表达式。函数表达的提升方式与变量声明一致
fn(); // 报错
var fn = function() {
console.log('function');
}
//上述例子执行顺序为
var fn = undefined; // 变量声明提升
fn(); // 执行报错
fn = function() { // 赋值操作,将后边函数的引用赋值给fn
console.log('function');
}
2
3
4
5
6
7
8
9
10
由于声明方式的不同,导致函数声明与函数表达式存在差异,除此,这种形式在使用上并无不同
# 函数声明、函数表达式
- 函数声明式 : function functionName (){}
- 函数表达式:let name = function(){}
console.log(a) //undefined
var a = 1
console.log(getNum)//getNum(){a=3}
var getNum = function() {
a = 2
}
function getNum() {
a = 3
}
console.log(a) //1
getNum()
console.log(a) //2
2
3
4
5
6
7
8
9
10
11
12
函数声明有提升作用,执行前把函数提升到顶部,执行上下文中生成函数定义,所以第二个 getNum会被最先提升到顶部
然后var 声明 getNum 的本该提升,但 getNum 的函数已经被声明了,所以不需要再声明一个同名变量,只是将已经声明的getNum替换掉了,于是修改变量a=2
var a = 1
function a(){} //已经声明提升,跳过
console.log(a) //1
var b
function b(){}
console.log(b) //f b(){}
function b(){}
var b //已经提升过了,var声明忽略
console.log(b) //f b(){}
2
3
4
5
6
7
8
9
10
11
!!函数会优先提升. function声明优先于var声明
进入执行上下文时,先 处理函数声明,其次 处理 变量声明,如果变量名称跟已经声明的形参或函数相同,变量声明不会干扰已经存在的这类属性
箭头函数和函数声明区别???
setTimeout(foo, 100)
foo = () => {
console.log('a')
}
foo()
function foo() {
console.log('b')
}
foo()
function foo() {
console.log('c')
}
foo()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
回调函数?由谁调用?
匿名函数传入另一个函数之后,最终会在另一个函数中执行,称这个匿名函数为回调函数
# 高阶函数
一个函数可接收另一个函数作为参数或返回另一个函数
- map
- reduce
- 参数: 接收两个参数,一个为回调函数,另一个为初始值。回调函数中四个默认参数,依次为积累值、当前值、当前索引和整个数组
- filter 返回新数组
- sort
# 普通函数
若是'use strict',不能将全局对象window作为默认绑定。this=undefined
普通函数:定义时this 指向函数作用域,但定时器之后执行函数时,此时this指向 window
普通函数的this,是调用是所在的对象
# 自执行函数
[IIFE]Immediately Invoked Function Expression:声明即执行的函数表达式
# 函数按值传参
结论仍然是按值传递,当我们期望传递一个引用类型时**,真正传递的,**只是这个引用类型保存在变量对象中的引用而已
var person = {
name: 'Nicholas',
age: 20
}
function setName(obj) { // 传入一个引用
obj = {}; // 将传入的引用指向另外的值
obj.name = 'Greg'; // 修改引用的name属性
}
setName(person);
console.log(person.name); // Nicholas 未被改变
2
3
4
5
6
7
8
9
10
11
12
# 函数式编程
函数式编程的思维建议我们将这种会多次出现的功能封装起来
使用时,只需要关心这个方法能做什么,而不用关心具体是怎么实现的。这也是函数式编程思维与命令式不同的地方之一
特征
函数是第一等公民
所谓"第一等公民"(first class),指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值
只用"表达式",不用"语句"
"表达式"(expression)是一个单纯的运算过程,总是有返回值;"语句"(statement)是执行某种操作,没有返回值。函数式编程要求,只使用表达式,不使用语句。每一步都是单纯的运算,都有返回值
函数式编程期望一个函数有输入,也有输出
# 纯函数
即:只要是同样的参数传入,返回的结果一定是相等的
# 自执行函数IIEE
let obj = {
num: 5,
func: function () {
let that = this;
console.log(that)
that.num *= 2;
(function () {
console.log(this)//window
this.num *= 3;
that.num *= 4;
return function () {
console.log(this)//window,但是没有IIEE的返回值没有被接收,所以不会执行此语句块
this.num *= 5;
that.num *= 6;
}
})()
}
}
var num = 2;
obj.func();
console.log(num);
console.log(obj.num);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
IIEE的this指向?
IIEE的返回值?
# 执行上下文
当执行 JS 代码时,会产生三种执行上下文
- 全局执行上下文
- 函数执行上下文
- eval 执行上下文
执行上下文创建阶段,vo、作用域链、闭包、this被确定
对每个执行上下文,都有三个重要属性:
- (Variable object,VO) 包含变量、函数声明和函数的形参,该属性只能在全局上下文中访问
- 作用域链(Scope chain) ,JS 采用词法作用域,变量的作用域在定义时就决定了
- this
JS属于解释型语言,执行分为:解释和执行两个阶段,这两个阶段所做的事并不一样:
# 解释阶段
- 词法分析
- 语法分析
- 作用域规则确定
# 执行阶段
- 创建执行上下文
- 确定this
- 创建 词法环境
- 创建 变量环境
- 执行
- 变量赋值、代码执行
- 垃圾回收
执行上下文在函数执行前创建。随时可改变,最明显的就是this的指向在执行时确定。 作用域访问的变量是编写代码的结构确定
词法环境——持有标识符-变量映射的结构
(标识符指的是变量/函数的名字,变量是对实际对象[包含函数类型对象]或原始数据的引用)
其实就是作用域,是一套规则
变量环境也是词法环境
词法环境组件和变量环境的不同是前者被用来存储函数声明和变量(let 和 const)绑定,后者只用来存储 var 变量绑定
同一个作用域下,不同调用产生不同的执行上下文环境,产生不同的变量值
JS引擎创建了**执行上下文栈(调用栈/执行栈)**管理执行上下文
当 JS 开始要解释执行代码的时候,首先创建全局执行上下文 push进栈,用 globalContext 表示它,当整个应用程序结束的时候,ECStack 才会被清空,所以程序结束之前, ECStack 最底部永远有个 globalContext
遇到函数调用 就为函数 创建新的 函数执行上下文 push进栈
从栈顶依次执行,执行完pop出栈
let a = 'Hello World!';
function first() {
console.log('Inside first function');
second();
console.log('Again inside first function');
}
function second() {
console.log('Inside second function');
}
first();
console.log('Inside Global Execution Context');
2
3
4
5
6
7
8
9
10
11

简单分析一下流程:
- 创建全局上下文压入执行栈
first被调用,创建函数执行上下文并压入栈- 执行
first过程遇到second,创建一个函数执行上下文并压入栈 second执行完毕,对应的函数执行上下文被推出执行栈,执行下一个执行上下文firstfirst执行完毕,对应的函数执行上下文也被推出栈中,然后执行全局上下文- 所有代码执行完毕,全局上下文pop出栈
# 🌰 作用域
Scope,变量(变量作用域又称为上下文)和函数存在的范围
作用域就是 变量 和函数的可访问范围,控制着变量和函数的可见性和生命周期
作用域规定了如何查找变量,即确定当前执行代码对变量的访问权限。(最大作用是 隔离变量),内层作用域可以访问外层作用域的变量,反之不行
块语句(大括号“{}”中间的语句), if/switch 条件语句或 for/while 循环语句,不像函数,它们不会创建新的作用域
# 全局作用域
{}外声明的变量
在代码任何地方都能访问到的对象拥有全局作用域
一般以下几种情形有全局作用域链:
- 最外层函数和在最外层函数外定义的变量
- 所有末定义直接赋值的变量自动声明为拥有全局作用域
- window对象的属性
# 局部作用域
和全局作用域相反,一般只在固定的代码片段内可访问,最常见的例如函数内部
分为 函数和 块级作用域
# 函数作用域
声明在函数内部的变量,在函数定义时就决定了
因为函数有内部属性[[scope]],函数创建时,保存所有父变量对象,理解为 [[scope]]就是所有父变量 对象的层级链,但![[scope]] 不代表完整的作用域链
JS不支持函数 重载! 因为 js 不用对传入的参数的类型进行严格定义。所以,即使我们写同名函数,只会导致后面函数将前面函数覆盖
# 块级作用域(ES6增)
为啥?ES5只有全局和函数,有不合理场景
- 内层变量覆盖外层变量
- 计数的i变为全局变量
块级作用域一定程度解决问题
块级作用域 通过 let和const声明,声明的变量在指定块的作用域外无法被访问
被创建:
- 函数内部
- 代码块(由一对花括号包裹)内部
特点:
- 声明变量不会提升
- 禁止重复声明
- 循环中的绑定块作用域的妙用
特点
- 不存在变量提升
- 禁止重复声明
- 循环中绑定作用域
for循环还有一个特别之处,设置循环变量的那部分是一个父作用域,而循环体内部是一个单独的子作用域
# for循环的setTimeout输出,var和let定义变量区别
它们算是闭包吗?
80% 应聘者都不及格的 JS 面试题 (opens new window)
setTimeout先将回调函数放到等待队列中等待其他主程序执行完毕,按时间顺序先进先出执行回调。本质是作用域的问题
每个setTimeout运行时都将function压入队列,var声明变量在全局环境都会被调用,执行压入下一个function时,会改变上一个已经压入队列的function中的变量i,最后打印五个5
因为 setTimeout 创建了一个可以访问其外部作用域的函数(闭包),该作用域是包含索引 i 的循环。 经过 3 秒后,执行函数并打印 i ,该值在循环结束时为 4,循环经过0,1,2,3,4循环最终停止在 4
某个标识符在当前作用域中没有找到,沿着外层作用域继续查找,直到最顶端,**词法作用域在函数定义时确定,而不是执行时,**b函数在全局作用域中定义,虽然在a函数内调用,但它只能访问到全局的作用域而不能访问到a函数的作用域
美团面试题
var name = 'name';
var A = {
name: 'A',
sayHello: function() {
let s = () => console.log(this.name);
let s=function(){
console.log(this.name)
}
return s;
}
};
let sayHello = A.sayHello();
sayHello();
var B = {
name: 'B'
};
sayHello.call(B)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 词法作用域
又叫静态作用域,变量被创建时就确定好,而不是执行阶段
# 作用域链
查找变量时,先从当前上下文的变量对象中查找,,从当前作用域开始一层层往上找,如果没找到,会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象——即全局对象。这样由多个执行上下文的变量对象构成的链表——作用域链
保证当前执行环境对符合访问权限的变量和函数的有序访问
与其相对的是动态作用域
作用域链规定如何查找变量,确定当前执行代码对变量的访问权限
if(!('a' in window)){
var a=1;
}
console.log(a)//undefined
2
3
4
因为 if语句中的var会变量提升,变成全局变量,于是window中就有a,但不会进入条件语句中,输出 undefined
# 🔑 闭包
闭包是啥?
为啥JS中所有函数都是闭包的
关于[[Environment]]属性和词法环境原理的细节
# 是啥
内部函数 可以访问其外部函数中声明变量,调用 外部函数返回 内部函数后,即使 外部函数执行结束了,但 内部函数引用外部函数的变量依然保存在内存 ,这些变量的集合——闭包
闭包 允许我们从内部函数 访问外部函数的作用域,闭包随着函数的创建同时被创建
每一个函数都会拷贝上级作用域,形成一个作用域链条
闭包:自由变量的查找,在函数定义的地方,向上级作用域查找
闭包数据是对象 存在堆空间,所以函数调用之后为闭包还能引用函数内的变量
形成 的3个条件:
- 闭包在函数被调用执行的时候被确认创建
- 闭包形成与作用域链的访问顺序有直接关系
- 只有内部函数访问了上层作用域链中变量对象,才会形成闭包
即使创建函数的上下文 已经销毁,它依然存在;同时引用了自由变量(自由变量:函数中使用,既不是 函数参数 也不是 函数局部变量的变量)
函数存在闭包,其所有内部函数都会拥有指向这个闭包的引用(所有内部函数共享一个闭包),只要任意内部函数引用外部函数声明变量,这个变量会被纳入闭包,最内部的函数持有所有外部的闭包
闭包不满足链式作用域结构??
(function(){})()理论上是一个闭包??
不是,它是立即执行函数
# 作用
- 独立作用域,避免变量污染
- 实现缓存计算结果,延长变量生命周期
- 创建私有变量
# 运用
项目中的应用??
防抖节流
防抖:事件触发高频到最后一次操作,如果规定时间内再次触发,则重新计时
function debounce(fn,delay=300){
let timer; //闭包引用外界变量
return function(){
consr args=arguments;
if(timer){
clearTimeout(timer);
}
timer=setTimeout(()=>{
fn.apply(this,args);
},delay);
};
}
2
3
4
5
6
7
8
9
10
11
12
模拟块级作用域
function OutPutNum(cnt){
(function (){
for(let i=0;i<cnt;i++){
alert(i);
}
})();
alert(i);
}
2
3
4
5
6
7
8
对象中创建私有变量
模拟私有方法
# 内存管理GC
栈中JS引擎自动清除
JS单线程机制,GC过程阻碍了主线程 执行
堆内存中的变量只有在 所有对它的引用都 结束 时被回收
自动垃圾回收机制:找出不使用的值,释放内存
函数运行结束,没有闭包或引用,局部变量被 标记 清除
全局变量:浏览器卸载页面 被清除
引用:显式引用(对象有对其属性的引用) 和 隐式引用(对象对其原型的引用)
# 垃圾回收算法
不论哪个垃圾回收算法,都有一套共同的流程:
- 标记内存空间中的活动对象(在使用中的对象)和非活动对象(可以回收的对象)
- 删除非活动对象,释放内存空间
- 整理内存空间,避免频繁回收后产生的大量内存碎片(不连续内存空间)
# 引用计数
一个对象是否有被引用(循环引用导致内存泄露)
跟踪每个变量被使用的次数
- 当声明了变量且将引用类型赋值给该变量时,值的引用次数为1
- 若同一个值又被赋给另一个值,引用数+1
- 如果该变量的值被其他的值覆盖了,则引用次数减 1
- 当这个值的引用次数变为 0 的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器在运行的时候清理掉引用次数为 0 的值占用的内存
缺点:
- 需要一个计数器,所占内存空间大,因为我们也不知道被引用数量的上限
- 解决不了循环引用导致的无法回收问题
# 标记清除
将“不再使用的对象”定义为“无法到达的对象”
工作流程:
- 垃圾收集器在运行时给内存变量加上 标记,假设内存中所有对象都是垃圾,全标记为0
- 根部出发,寻找可到达的变量,将其标记清除,改为1
- 留有标记的变量就是待删除的,即标记为0,销毁并回收它们占用的内存
- 把所有内存中对象标记修改为0,等待下一轮垃圾回收
优点:实现简单,一位二进制位就可以为其标记
缺点:
- 内存碎片化,空闲内存块不连续,可能出现分配所需内存过大的对象时找不到合适的块
- 分配速度慢,即使使用
first-fit策略,操作仍是一个O(n)的操作,最坏情况是每次都要遍历到最后,因为碎片化,大对象的分配速率会更慢
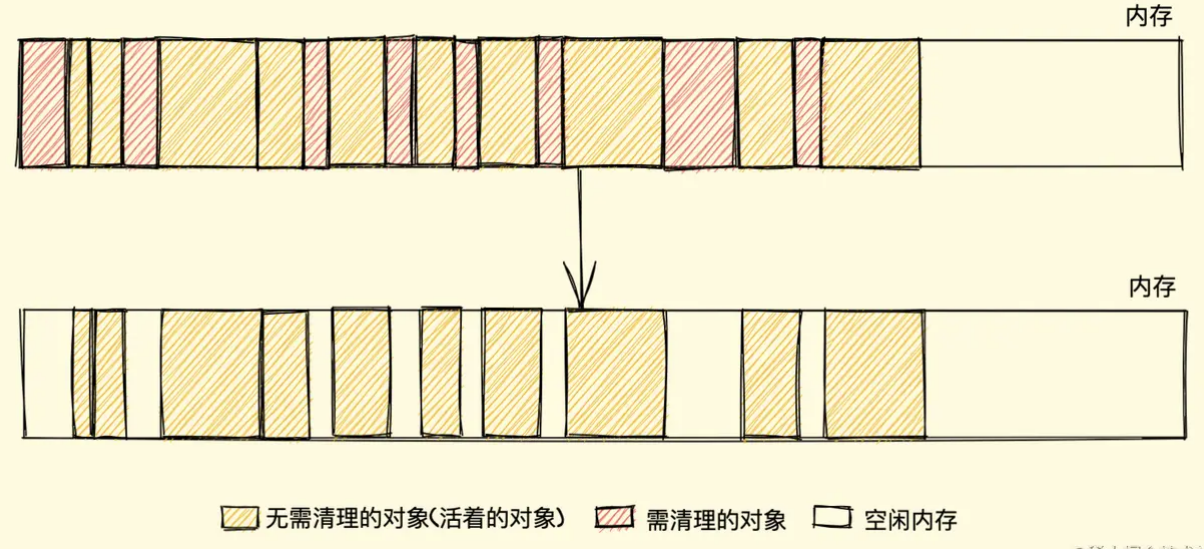
# 复制算法
为了解决上述问题,复制算法出现了
- 将整个空间平均分成 from 和 to 两部分。
- 先在 from 空间进行内存分配,当空间被占满时,标记活动对象,将其复制到 to 空间
- 复制完成后,将 from 和 to 空间互换
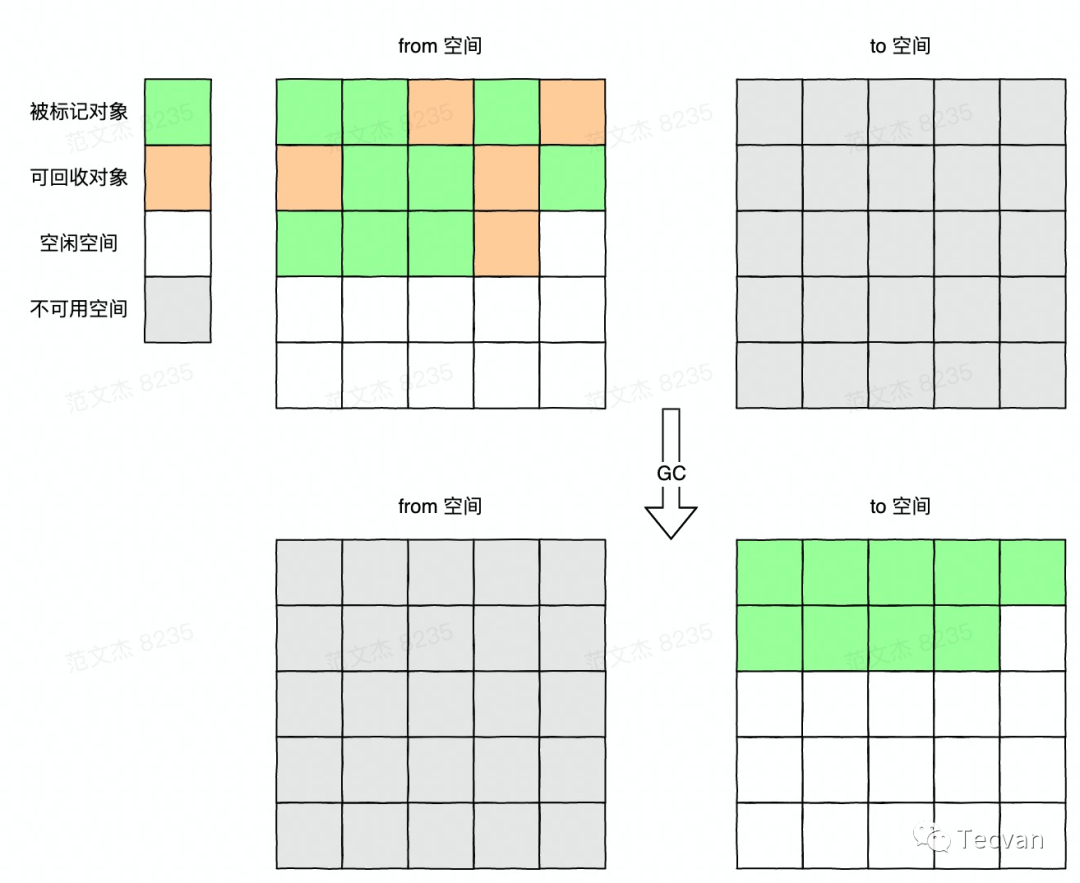
由于直接将活动对象复制到另一半空间,没有了清除阶段的开销,所以能在较短时间内完成回收操作,并且每次复制的时候,对象都会集中到一起,相当于同时做了整理操作,避免了内存碎片
复制算法 吞吐量高、没有碎片;但 复制操作需要时间成本,若堆空间很大且活动对象很多,每次清理时间会很久。其次,将空间二等分的操作,让可用的内存空间直接减少了一半
# 标记整理
也叫做 标记-压缩算法。结合了标记-清除和复制算法的优点
- 从一个 GC root 集合出发,标记所有活动对象
- 将所有活动对象移到内存的一端,集中到一起
- 直接清理掉边界以外的内存,释放连续空间
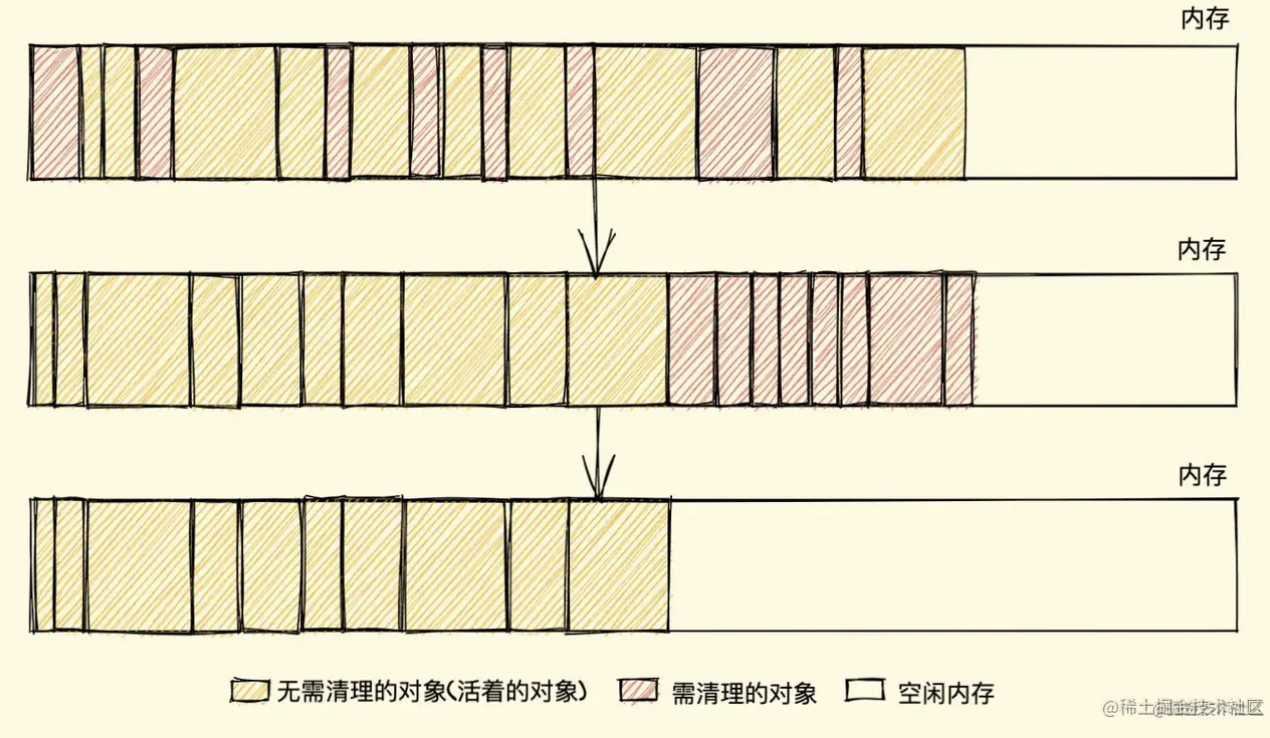
既避免了标记-清除法产生内存碎片的问题,又避免了复制算法导致可用内存空间减少的问题。其清除和整理的操作很麻烦,需要对整个堆做多次搜索,故而堆越大,耗时越多
必须暂停JS脚本执行等待——全停顿,全停顿对性能影响大,所以出现了 增量标记的策略进行老生代垃圾回收
# 💛 V8 对GC优化
代际假说
- 栈中数据回收:执行状态指针 ESP 在执行栈中移动,移过某执行上下文,被销毁
- 堆中数据回收:V8 引擎采用标记-清除算法
- V8 堆分为新生代和老生代 2个区域,分别使用副、主垃圾回收器
- 副垃圾回收器负责新生代垃圾回收,小对象(1 ~ 8M)被分配到该区域处理
- 新生代采用 scavenge 算法处理:空间分为一半空闲,一半存对象,对象区域做标记,存活对象复制到空闲区域,没有内存碎片,完成后,清理对象区域,角色反转
- 新生代区域两次垃圾回收还存活的对象晋升至老生代区域
- 主垃圾回收器负责老生区垃圾回收,大对象,存活时间长
- 新生代区域采用标记-清除算法回收垃圾
- 为了不造成卡顿,标记过程被切分为一个个子标记,交替进行
分代式垃圾回收
以上垃圾清理算法每次都要检查内存中所有对象,对一些大、老、存活时间长的对象来说,同新、小、存活时间短的对象一个频率的检查很不好,因为前者不需要频繁清理,后者相反,如何优化?
# 分代式
分代式机制把一些新、小、存活时间短的对象作为新生代,采用一小块内存频率较高的快速清理,而一些大、老、存活时间长的对象作为老生代,使其很少接受检查,新老生代的回收机制及频率是不同的,此机制的出现很大程度提高了垃圾回收机制的效率
# 新老生代
V 8 将堆内存分为新生代和老生代两区域,采用不同的垃圾回收策略
新生代的对象是存活时间较短的对象
老生代的对象为存活时间较长或常驻内存的对象
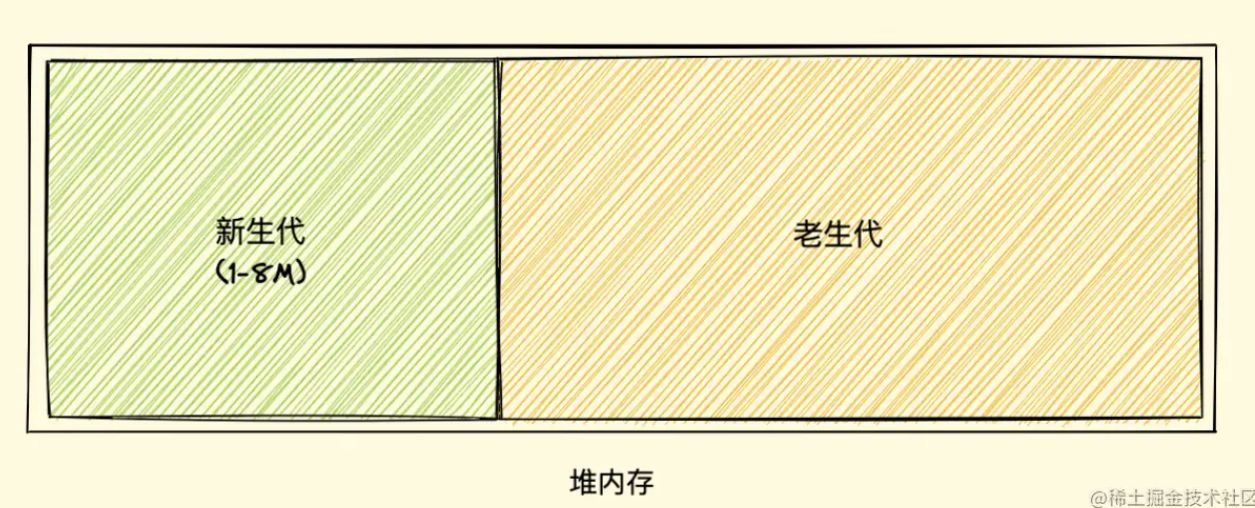
# 新生代
新生代中对象一般存活时间较短,采用 scavenge 算法,主要采用一种复制式的方法
scavenge 是典型的以时间换空间的算法,新生代大部分对象生命周期较短,时间效率上表现可观,所以 比较适合这种算法
scavenge主要采用Cheney算法
新生代空间对半分 from-space 和 to-space 两个区域
from空间为激活状态区域
to空间为 未激活 区域
2
新创建的对象存放到 from-space,空间快被写满时触发垃圾回收。***先对 from-space 中的对象标记,完成后将标记对象复制到 to-space*** ,非存活对象被回收,copy后,from和to 空间 角色反转,完成回收操作
为啥要角色反转??
因为需要使用 活跃区啊——from
scavenge主要 将存活的对象在from和to空间赋值,完成2个空间的角色互换
缺点——浪费一般内存用于复制
每次执行清理操作都需要复制对象,复制对象需要时间成本,所以新生代空间设置得比较小(1~8M)
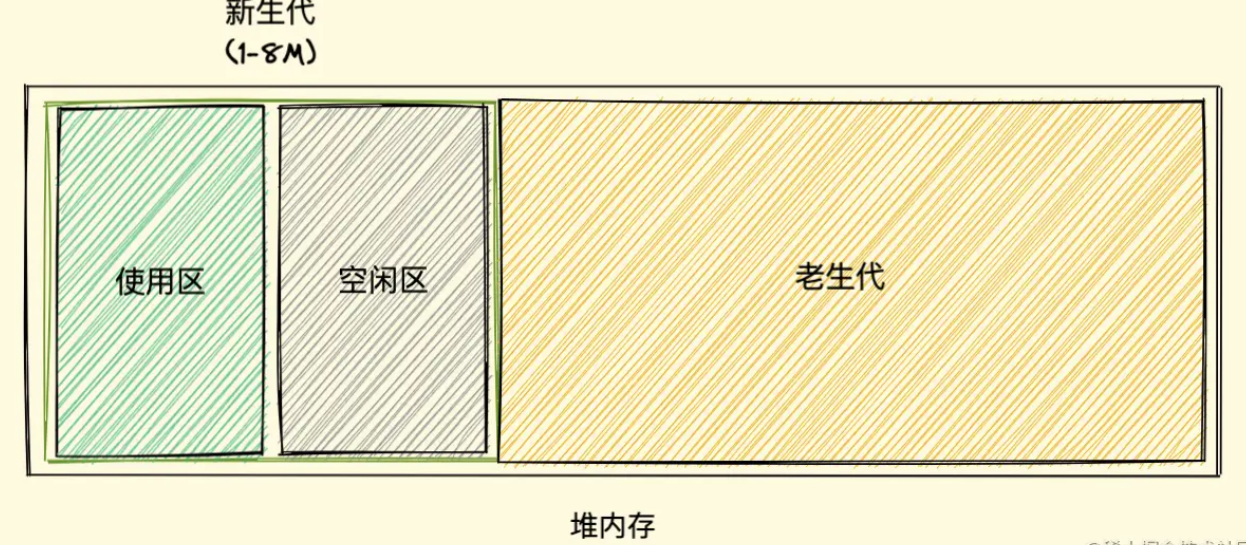
当一个对象经过多次复制后依然存活,是生命周期较长的对象,被移动到老生代,采用老生代垃圾回收策略 管理
晋升的条件
- 对象经历过一次scavenge算法
- to空间内存占比超过25%
复制一个对象到空闲区时,空闲区空间占用超过 25%,这个对象被直接晋升到老生代空间中,设置为 25% 的比例是因为完成 Scavenge 回收后,to区将翻转成from区,继续进行对象内存的分配,占比过大影响后续内存分配
# 老生代
老生代管理大量 存活对象,scavenge算法浪费内存
老生代中对象一般存活时间长且数量多,使用 标记清除(Mark-sweep) 和标记压缩(Mark-Compact) 算法
晋升条件:
- 对象是否经历过一次 Scavenge 算法
- To 空间对象占比大小超过 25 %
首先是标记阶段,从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称为活动对象,没有到达的元素为非活动对象
具体步骤
- 内部创建根列表,从根节点 出发寻找可被访问的变量,比如window可看成根节点
- 垃圾回收器从所有根节点出发,遍历可访问的子节点,标记为 活动的;不能到达的 被视为 垃圾
- 释放所有非活动内存块
1、全局对象2、本地函数局部变量和参数 3、当前嵌套调用链上其他函数的变量和参数 均可被视作 根节点
前面我们也提过,标记清除算法在清除后产生大量不连续内存碎片,过多碎片导致大对象无法分配到足够的连续内存——标记整理算法 解决这一问题
整理过程中,将活动对象往 堆内存 的一端移动,移动完成后再清理掉外边界的全部内存
以下情况先启动标记清除算法:
- 某一个空间没有分块
- 空间中被对象超过一定限制
- 空间不能保证新生代中的对象移动到老生代中
JS 单线程运行,垃圾回收算法和脚本任务在同一线程内运行,执行垃圾回收逻辑时,后续脚本任务需要等垃圾回收完成后才能执行。若堆中数据量非常大,一次完整垃圾回收的时间会非常长,将导致应用的性能和响应能力都下降
为了避免垃圾回收影响性能,V8 将标记的过程拆分成多个子标记,让垃圾回收标记和应用逻辑交替执行(以前是 全停顿,现在改为 增量标记) ,避免脚本任务等太久
增量标记 和Fiber相似,只有空闲时去遍历Fiber Tree执行对应任务
基于增量标记,V8后续引入 延迟清理和增量式整理,充分利用CPU性能
# 🔥 内存泄漏
# 识别
如果连续五次垃圾回收之后,内存占用一次比一次大,就有内存泄漏
这就要求实时查看内存的占用情况
在 Chrome 浏览器中,我们可以这样查看内存占用情况
1.打开开发者工具,选择 Performance 面板
2.在顶部勾选 Memory
3.点击左上角的 record 按钮
4.在页面上进行各种操作,模拟用户的使用情况
5.一段时间后,点击对话框的 stop 按钮,面板上就会显示这段时间的内存占用情况
2
3
4
5
# 造成内存泄露
- 意外的全局变量
- 被遗忘的定时器和回调函数
- 事件监听没有移除
- 没有清理的DOM 引用
- 闭包
- 控制台打印
# 🔥 柯里化
是高阶函数的一种特殊用法
接收函数A作为参数,返回新的函数,这个新的函数能够处理函数A的剩余参数
柯里化函数的运行过程是一个参数的收集过程,我们将每一次传入的参数收集起来,并在最里层里面处理
用 闭包 把参数保存起来,当参数的数量足够执行函数了,就开始执行
var add = function (m) {
var temp = function (n) {
return add(m + n);
}
temp.toString = function () {
return m;
}
return temp;
};
console.log(add(3)(4)(5)); // 12
console.log(add(3)(6)(9)(25)); // 43
2
3
4
5
6
7
8
9
10
11
对于add(3)(4)(5),其执行过程如下:
- 执行add(3),此时m=3,返回temp函数
- 执行temp(4),这个函数内执行add(m+n),n是此次传进来的数值4,m值还是上一步中的3,所以add(m+n)=add(3+4)=add(7),此时m=7,返回temp函数
- 执行temp(5),这个函数内执行add(m+n),n是此次传进来的数值5,m值还是上一步中的7,所以add(m+n)=add(7+5)=add(12),此时m=12,返回temp函数
- 后面没有传入参数,等于返回的temp函数不被执行而是打印,对象的toString修改对象转换字符串,因此代码中temp函数的toString函数return m值,而m值是最后一步执行函数时的值m=12,所以返回值是12
fn.length 表示fn函数的参数个数
let addCurry = curry1((a, b) => a + b);
console.log(addCurry()(11)(1));
function curry1(fn) {
let judge = (...args) => {
if (args.length === fn.length) {
return fn.call(this, ...args);
}
//获取偏函数,返回包装器,重新组装参数并传入
return (...arg) => judge(...arg, ...args)
}
return judge;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# ✅let var const
在ES5中,顶层对象的属性和全局变量等价,var声明的变量是全局也是顶层变量
var没有块级作用域,只有函数作用域。var只有在function{ }内部才有作用域的概念,其他地方没有。意味着函数以外用var定义的变量是同一个,我们所有的修改都是针对他的
let和const增加块级作用域(JS没有块级作用域)
let和const存在暂时性死区,不存在变量提升,不能在初始化前引用,调用 返回
uninitializedlet和const禁止重复声明,不能重新声明
let和
const不会成为全局对象属性,var声明的变量自动成为全局对象属性var a = 123 if (true) { a = 'abc' // ReferenceError let a; }1
2
3
4
5const实际保证的并不是变量的值,而是变量指向的内存地址var 存在变量提升(执行前,编译器对代码预编译,当前作用域的变量/函数提升到作用域顶部),
let约束变量提升。let和var都发生了变量提升,只是es6进行了约束,在我们看来,就像let禁止了变量提升使用
var,我们能对变量多次声明,后面声明的变量会覆盖前面的声明
# 作用域
在函数中声明了var,整个函数有效,比如for循环内定义var变量,实际在for循环以外也可以访问
for循环每次执行都是一个全新独立块作用域,let声明的变量传入for循环体的作用域后,不会发生改变,不受外界影响
常考面试题:
for (var i = 0; i <10; i++) {
setTimeout(function() { // 同步注册回调函数到 异步的 宏任务队列
console.log(i); // 执行此代码时,同步代码for循环已经执行完成
}, 0);
}
// 输出结果
10 共10个
// 这里面的知识点: JS的事件循环机制,setTimeout的机制等
2
3
4
5
6
7
8
// i虽然在全局作用域声明,但是在for循环体局部作用域中使用的时候,变量会被固定,不受外界干扰
for (let i = 0; i < 10; i++) {
setTimeout(function() {
console.log(i); // i 是循环体内局部作用域,不受外界影响
}, 0);
}
// 输出结果:
0 1 2 3 4 5 6 7 8 9
2
3
4
5
6
7
8
let必须先声明再使用。var先使用后声明也行,只不过直接使用没定义 是undefined。var 变量提升,整个函数作用域被创建时,实际上var定义的变量都会被创建,如果没有初始化,默认undefined
JS只有函数和全局作用域,没有块级作用域,所以{}限定不了var声明变量的访问范围
(function () {
var x = y = 1
})();
var z;
console.log(y)
console.log(z)
console.log(x)
//var x=y=1 等价于 var x=1;y=1 ,y被提升至全局作用域
2
3
4
5
6
7
8
9
# 💜 事件流?
JS和HTML的交互 通过 事件 实现,使用侦听器 预定事件,便于事件发生时执行相应代码
手指放在一组同心圆的圆心上,手指指向不是一个圆 ,而是纸上的所有圆,单击按钮时 单击事件不止发生在按钮上,同时 也单击了按钮的容器元素,甚至也单击了整个页面
事件流描述 从页面接收事件的顺序
事件发生时会在元素节点和根节点之间按照特定的顺序传播,路径所经过的节点都会收到该事件——DOM事件流
捕获:不太具体的节点应该更早接收到事件,而最具体的节点最后收到事件。目的是在事件到达预定目标之前捕获它
冒泡:事件开始由最具体的元素接收,逐级向上传播到不具体的节点,document对象首先收到click事件,事件沿着DOM树依次往下,传播到事件的具体目标
DOM标准规定事件流包括3个阶段:事件捕获、处于目标阶段和事件冒泡
- 事件捕获——为截获事件提供机会
- 处于目标阶:事件在
div上发生并处理 - 冒泡阶段:事件又传播回文档
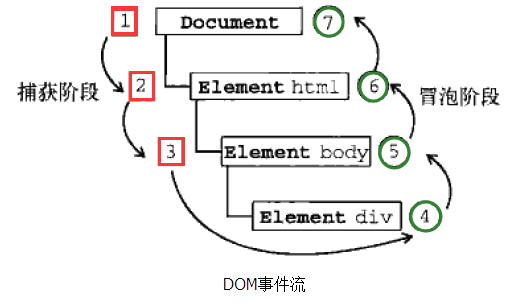
所有事件都要经过捕获阶段和处于目标阶段
**focus(获得输入焦点)和失去焦点blur事件没有冒泡,**无法委托
# 原始事件模型
<input type="button" onclick="fun()">
var btn = document.getElementById('.btn');
btn.onclick = fun;
2
3
- 绑定速度快
页面还未完全加载,事件可能无法正常运行
- 只支持冒泡,不支持捕获
- 同一个类型的事件只能绑定一次
<input type="button" id="btn" onclick="fun1()">
var btn = document.getElementById('.btn');
btn.onclick = fun2;
//出错 后绑定的事件会覆盖掉之前的事件
2
3
4
5
删除事件处理程序 将对应事件属性置为null
btn.onclick = null;
# 标准事件模型
- 事件捕获:从
document一直向下传播到目标元素, 依次检查经过节点是否绑定了事件监听函数,有则执行 - 事件处理:到达目标元素, 触发目标元素的监听函数
- 事件冒泡:从目标元素冒泡到
document, 依次检查经过节点是否绑定了事件监听函数,如果有则执行
事件绑定监听函数
addEventListener(eventType, handler, useCapture)
事件移除监听函数
removeEventListener(eventType, handler, useCapture)
eventType事件类型(不要加on)handler事件处理函数useCapture,是否在捕获阶段处理,默认false
举个例子:
var btn = document.getElementById('.btn');
btn.addEventListener('click', showMessage, false);
btn.removeEventListener('click', showMessage, false);
2
3
一个
DOM上绑定多个事件处理器,不会冲突
btn.addEventListener(‘click’, showMessage1, false);
btn.addEventListener(‘click’, showMessage2, false);
btn.addEventListener(‘click’, showMessage3, false);
2
3
第三个参数(useCapture)为true在捕获过程执行,反之在冒泡过程执行
# IE事件模型
因为IE8及更早版本只支持事件冒泡,因此通过attachEvent添加的事件都会被添加到冒泡阶段
事件处理:事件到达目标元素, 触发目标元素的监听函数
事件冒泡:事件从目标元素冒泡到
document事件绑定监听函数的方式
attachEvent(eventType, handler)1事件移除监听函数的方式
detachEvent(eventType, handler)1举个例子:
var btn = document.getElementById('.btn'); btn.attachEvent(‘onclick’, showMessage); btn.detachEvent(‘onclick’, showMessage);1
2
3
# 事件代理
# 原理
事件委托,把一个或者一组元素的事件委托到它的父层或者更外层元素上,真正绑定事件的是外层元素,不是目标元素
只指定一个事件处理程序,管理某一类型 所有事件
把一个元素响应事件(click、keydown......)的函数委托到另一个元素,冒泡阶段完成
对“事件处理程序过多”问题的解决方案就是事件委托
使用事件委托,只需在DOM树中尽量高的一层添加一个事件处理程序
举例
代 取快递
优点
- 节省内存,减少dom操作
- 不需要给子节点注销事件
- 动态绑定事件
- 提高性能
- 新添加的元素还会有之前的事件
为啥用
**事件冒泡过程中上传到父节点,**父节点通过事件对象获取到目标节点,把子节点的监听函数定义在父节点上,由父节点的监听函数统一处理子元素的事件
比如100个li,每个都有click,如果使用for遍历 添加事件,关系页面整体性能,需要不断交互 访问dom次数过多,引起重排,延长交互时间
事件委托的话,将操作放进JS,只需要和dom交互一次,提高性能,还节约内存
# 实现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul id="ul1">
<li>111</li>
<li>222</li>
<li>333</li>
<li>444</li>
</ul>
<script>
/* window.onload = function () {
var oUl = document.getElementById("ul1");
var aLi = oUl.getElementsByTagName('li');
for (var i = 0; i < aLi.length; i++) {
aLi[i].onclick = function () {
alert(123);
}
}
}*/
window.onload = function () {
var oUl = document.getElementById("ul1");
oUl.onclick = function () {
alert(123);
}
}
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
Event对象提供属性target,返回事件的目标节点——事件源
target表示当前事件操作的dom,但不是真正操作dom
通过target.id获得操作的具体dom
新增的节点怎么办,即 新来员工的快递咋整?
事件委托也能解决
(鼠标事件、键盘事件和点击事件)支持冒泡
聚焦、失焦、UI、鼠标移入移除事件不支持冒泡
- 适合事件委托的事件:click,mousedown,mouseup,keydown,keyup,keypress
- mouseover 和 mouseout 也有事件冒泡,但需要经常计算它们的位置,处理不太容易
- 不适合的,mousemove,每次都要计算它的位置,不好把控, focus,blur 等本身就没有冒泡的特性,自然就不用事件委托
# 阻止冒泡
- 阻止冒泡:非 IE stopPropagation(),IE 则event.cancelBubble = true
- 阻止默认行为:非 IE preventDefault(),IE则event.returnValue = false
# e.target、e.currentTarget
- e.target:触发事件的元素,是点击的元素
- e.currentTarget:绑定事件的元素,是途径的元素,执行捕获的顺序
event还有哪些属性?
event.bubbles 返回 布尔值,表明当前事件是否会向 DOM 树上层元素冒泡
event.defaultPrevented 返回 布尔值,表明当前事件是否调用了 event.preventDefault() (opens new window)
# addEventListener、onClick()
addEventListener为元素绑定事件,接收三个参数:
第一个参数:绑定的事件名
第二个参数:执行的函数
第三个参数:
- false:默认,代表冒泡时绑定
- true:代表捕获时绑定
onclick和addEventListener
onclick事件会被覆盖,同一个元素只能绑定一个事件
addEventListener可先后运行不会被覆盖,可监听多个事件,执行顺序从上到下依次执行
addEventListener对任何DOM元素有效
注册addEventListener不需写on,onClick需要加on
移除事件,onClick使用指针指向null,document.onClick=null,addEventListener使用独有移除方法removeListener
addEventListener为DOM2级事件绑定,onclick为DOM0级事件绑定
不适用内联onClick作为HTML属性,混淆JS和HTML,降低维护性
# 事件劫持?
# 🌰 JSON.stringify()
序列化,忽略值为undefined的字段
若某个字段为undefined,将其修改为空串
1、若目标对象存在toJSON()方法,它负责定义哪些数据被序列化
let obj={
x:1,
y:2,
toJSON:function(){
return 'a string create by toJSON'
}
}
console.log(JSON.stringify(obj));
//'a string create by toJSON'
2
3
4
5
6
7
8
9
2、Boolean、Number、String对象被装换为对应原始值
const obj={
a:new Number(11),
b:new String('aaa'),
c:new Boolean(true)
}
console.log(JSON.stringify(obj));
//{"a":11,"b":"aaa","c":true}
2
3
4
5
6
7
3、undefined、Function和Symbol不是有效的JSON值,要么被忽略(在对象中找着),要么被更改为null(在数组中找着)
const obj={
name:Symbol('aaa'),
age:undefined,
isHigh:function(){}
}
console.log(JSON.stringify(obj));
//{}
2
3
4
5
6
7
const arr=[Symbol('aaa'),undefined,function(){},'fighting'];
console.log(JSON.stringify(arr));
//[null,null,null,"fighting"]
2
3
4、所有Symbol-keyed属性被忽略
const obj={
}
obj[Symbol('a')]='aa';
obj[Symbol('b')]='bb';
console.log(obj);
console.log(JSON.stringify(obj));
//{Symbol(a): 'aa', Symbol(b): 'bb'}
//{}
2
3
4
5
6
7
8
9
5、Date的实例返回一个字符串实现toJSON()方法(和date.toISOString()——使用 ISO 标准返回 Date 对象的字符串格式相同)
JSON.stringify(new Date());
//'"2022-06-16T23:36:38.943Z"'
2
6、Infinity、NaN和null都被认为是null
const obj={
a:Infinity,
b:NaN,
c:null,
val:20
};
console.log(JSON.stringify(obj));
//{"a":null,"b":null,"c":null,"val":20}
2
3
4
5
6
7
8
7、所有其他Object实例(包括Map、Weakmap、Set和WeakSet)序列化为其可枚举的属性
let enumObj={};
//直接在一个对象上定义新的属性或修改现有属性,并返回该对象
Object.defineProperties(enumObj,{
'name':{
value:'a',
enumerable:true
},
'age':{
value:99,
enumerable:false
},
});
console.log(JSON.stringify(enumObj));
//{"name":"a"}
2
3
4
5
6
7
8
9
10
11
12
13
14
8、遇到循环抛出TypeError(循环对象值)异常
const obj={
a:'aa'
};
obj.subObj=obj;
console.log(JSON.stringify(obj));
//VM357:5 Uncaught TypeError: Converting circular structure to JSON
2
3
4
5
6
9、对BigInt值字符串化时抛出TypeError(BigInt值无法在JSON中序列化)
const obj={
a:BigInt(999999999999999999999)
};
console.log(JSON.stringify(obj));
//VM362:4 Uncaught TypeError: Do not know how to serialize a BigInt
2
3
4
5
# Promise
简单说就是一个容器,保存某个未来才会结束的事件的结果。语法上Promise 是对象,可以获取异步操作的消息。Promise 提供统一 API,各种异步操作都可以用同样方法处理,让开发者不用关注时序和底层结果。Promise的状态不受外界影响,不可逆
是异步编程的一种解决方案,更合理 强大
出现的原因
基于回调的异步风格——异步执行某项功能的函数提供一个callback在相应事件完成时调用
**回调中回调!**单一的callback处理error报告和传递返回结果
可行的异步编程方式??对1/2个嵌套调用看起来不错
but,一个接一个的异步行为……
调用嵌套增加,代码层次更深,维护难度大,尤其是 很多循环和条件语句的代码……——回调地狱/厄运金字塔
造成 代码失控!!
Promise
链式调用
- 链式写法
- 改善可读性
- 多层嵌套更友好
Promise 是对象也是构造函数,接收一个函数作为参数,该函数的2个参数分别是resolve reject
所有异步任务都返回promise实例,promise有一个then方法,指定下一步回调
成功则调用resolve,失败调用reject
由new Promise返回的Promise的内部属性
- state:pending、fulfilled、rejected
- result:undefined——value/error
Promise——承诺,一旦承诺 便不可更改
Promise.reject(2)
//.catch(err=>console.log("err1,",err))
.then(null,err=>console.log("err1,",err)) //rejected状态,执行then的第二个callback,改变状态为fulfilled
.then(res=>{console.log("then1",res)},null)//fulfilled,执行第一个回调,不会去到下一步catch
.then(res=>console.log('end'),err=>console.log("err2,",err))
2
3
4
5
6
7
8
.then
可将多个.then添加到一个Promise上,但不是一个promise链
let promise = new Promise(function(resolve, reject) {
setTimeout(() => resolve(1), 1000);
});
promise.then(function(result) {
alert(result); // 1
return result * 2;
});
promise.then(function(result) {
alert(result); // 1
return result * 2;
});
promise.then(function(result) {
alert(result); // 1
return result * 2;
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
promise的几个处理程序,彼此 独立运行!!

Promise的错误“冒泡”会一直向后传递,直到被捕获
每个Promise都会经历生命周期:
- 进行中(pending)代码执行尚未结束,也叫未处理的(unsettled)
- 已处理(settled) 代码执行结束 已处理的代码进入两种状态中的一种:
已完成(fulfilled)代码执行成功,resolve()触发
已拒绝(rejected)遇到错误,代码执行失败 ,reject()触发
// 如果触发reject(),但是没有 捕获 reject的结果,代码抛出异常并停止执行
async function async1() {
await async2();
console.log('async1');
return 'async1 success'
}
async function async2() {
return new Promise((resolve, reject) => {
console.log('async2')
reject('error')
})
// .then(res => {console.log(res)}, res => console.log((res)))
}
async1().then(res => console.log(res))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 实例方法
- then()
.then(handler)中的handler 创建返回 新的Promise,确切说 返回不完全是promise,而是 对象"thenable"——具有方法.then的对象,被当做promise
所以,then会修改Promise状态吗?
rejected——>fulfilled????
- catch()
建议使用catch(),而不是then()的第二个参数
- finally
返回 Promise 。 promise 结束时,无论结果 fulfilled / rejected,都会执行指定回调
# 构造函数方法
# all()
将多个 Promise 实例,包装成一个新的 Promise 实例
接收一个数组(可迭代对象)作为参数,数组成员都应为Promise实例
提供并行执行异步操作的能力
const p = Promise.all([p1, p2, p3]);
- 只有状态都变成fulfilled,p才会变成fulfilled,此时p1 p2 p3的返回值组成一个数组,传递给回调
- 只要有一个被rejected,p就变成rejected,此时第一个被reject的实例返回值传递给回调
若Promise参数实例自己定义catch(),它被rejected不会触发Promise.all()的catch()
因此可在单个catch中对失败promise请求做处理,使请求正常返回
const p1 = new Promise((resolve, reject) => {
resolve('hello');
})
.then(result => result)
.catch(e => e);
const p2 = new Promise((resolve, reject) => {
throw new Error('报错了');
})
.then(result => result)
.catch(e => e);
Promise.all([p1, p2])
.then(result => console.log(result))
.catch(e => console.log(e));
// ["hello", Error: 报错了]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
若p2没有自己的catch(),就调用Promise.all()的catch()
const p1 = new Promise((resolve, reject) => {
resolve('hello');
})
.then(result => result);
const p2 = new Promise((resolve, reject) => {
throw new Error('报错了');
})
.then(result => result);
Promise.all([p1, p2])
.then(result => console.log(result))
.catch(e => console.log(e));
// Error: 报错了
2
3
4
5
6
7
8
9
10
11
12
13
14
出现错误后不进行reject,继续resolve(error),交给promise.all()处理
promise数组顺序直接影响结果顺序,和promise执行完成先后无关
快速失败——如果数组至少一个被 rejected ,那返回的 promise 也被拒绝。如果数组中所有都被 rejected ,那返回的promise 被拒绝的原因是先rejected的那一个
Promise.all()是并行执行异步操作获取所有 resolve 值的最佳方法,适合需要同时获取异步操作结果进行下一步运算场合
# allSettled
数组作为参数,每个成员都是 Promise 对象,返回新的 Promise 实例
只有等到数组的所有 Promise 都状态变更(不管是fulfilled/rejected) 返回的 Promise 才状态变更,带有对象数组,每个对象表示对应promise结果
当有多个彼此不依赖的异步任务完成时,或想知道每个promise的结果时,可以使用
相比,all更适合彼此依赖或其中任何一个reject时马上结束
var promise1 = new Promise(function(resolve,reject){
setTimeout(function(){
reject('promise1')
},2000)
})
var promise2 = new Promise(function(resolve,reject){
setTimeout(function(){
resolve('promise2')
},3000)
})
var promise3 = Promise.resolve('promise3')
var promise4 = Promise.reject('promise4')
Promise.allSettled([promise1,promise2,promise3,promise4]).then(function(args){
console.log(args);
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# any
一个成功就成功,所有失败才失败!
接受一组 Promise 可迭代实例作为参数,返回一个新的 Promise
只要参数实例有一个fulfilled,包装实例变成fulfilled;如果所有参数实例都rejected,包装实例变成rejected
Promise.any()不会因为某个 Promise 变成rejected状态而结束,必须等到所有参数 Promise 变状态才结束
# race
简言之,看谁跑得快呗,注重时序
和all一样,但是 返回执行最快的Promise的结果
将多个 Promise 实例,包装成一个新的 Promise 实例 只要p1、p2、p3之中有一个实例率先改变状态,p的状态就跟着改变 率先改变的 Promise 实例返回值 传递给p的回调
const p = Promise.race([p1, p2, p3]);
const p = Promise.race([
fetch('/resource-that-may-take-a-while'),
new Promise(function (resolve, reject) {
setTimeout(() => reject(new Error('request timeout')), 5000)
})
]);
p
.then(console.log)
.catch(console.error);
2
3
4
5
6
7
8
9
10
- resolve()
- reject()
# 场景
- Ajax请求
- 文件读取
- 图片加载
- 函数封装
# 实现Promise
# 实现Promise.then()
# 栗子
JS不会允许看不到尽头的微任务一直待在队列,以下代码执行可能差强人意
Promise.resolve().then(() => {
console.log(0);
return Promise.resolve(4);
}).then((res) => {
console.log(res)
})
Promise.resolve().then(() => {
console.log(1);
}).then(() => {
console.log(2);
}).then(() => {
console.log(3);
}).then(() => {
console.log(5);
}).then(() =>{
console.log(6);
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
因为promise1处于pending状态,所以promise1.then()的回调函数还不会加入到微任务队列中
timer2是一个延时2s的计时器,1s后,timer1完成,promise1状态变化,又过了1s,timer2完成,执行回调函数
const promise1 = new Promise((resolve, reject) => {
const timer1 = setTimeout(() => {
resolve('success')
}, 1000)
})
const promise2 = promise1.then(() => {
throw new Error('error!!!')
})
console.log('promise1', promise1)
console.log('promise2', promise2)
const timer2 = setTimeout(() => {
console.log('promise1', promise1);
console.log('promise2', promise2);
}, 2000)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
resolve会马上执行,a=2,就resolve了,实际上a的循环会走完 变成1002
var a = 1;
setTimeout(function () {
console.log(a++)
}, 0)
new Promise(function executor(resolve) {
console.log(a++)
for (var i = 0; i < 1000; i++) {
resolve(a++)
}
console.log(a++)
}).then(function (a) {
console.log(a++)
})
console.log(a++)
2
3
4
5
6
7
8
9
10
11
12
13
14
# 🌰 异步解决方案
同步操作:顺序执行,同一时间只能做一件事情。会阻塞后面代码的执行
异步:当前代码的执行作为任务放进任务队列。当程序执行到异步的代码时,将该异步的代码作为任务放进任务队列,而不是推入主线程的调用栈。等主线程执行完之后,再去任务队列里执行对应的任务。不会阻塞后续代码的运行
# 异步场景?
- 定时任务:setTimeout、setInterval
- 网络请求:ajax请求、动态创建img标签的加载
- 事件监听器:addEventListener
# 回调
回调函数就是我们请求成功后需要执行的函数
实现了异步,但是带来一个非常严重的问题——回调地狱,即 我们表达异步操作的执行顺序的唯一方法是 将一个回调嵌套在另一个回调中
# 发布/订阅
Node.js EventEmitter 中的 on 和 emit
当一个对象的状态改变时,所有依赖于它的对象都得到状态改变的通知
比如公众号推送
手写 发布-订阅模式
- 创建对象
- 创建缓存列表
- on 将handler 加到缓存列表中(订阅者注册事件)
- emit 根据event值执行函数
- off根据event取消订阅
- once监听一次,调用完毕后删除
let eventEmitter = {
// 缓存列表
list: {},
on(event, fn) {
let _this = this;
// 如果对象中没有对应的 event 值,也就是说明没有订阅过,就给 event 创建个缓存列表
// 如有对象中有相应的 event 值,把 fn 添加到对应 event 的缓存列表里
(_this.list[event] || (_this.list[event] = [])).push(fn);
return _this;
},
once(event, fn) {
// 先绑定,调用后删除
let _this = this;
function on() {
_this.off(event, on);
fn.apply(_this, arguments);
}
on.fn = fn;
_this.on(event, on);
return _this;
},
off(event, fn) {
let _this = this;
let fns = _this.list[event];
// 如果缓存列表中没有相应的 fn,返回false
if (!fns) return false;
if (!fn) {
// 如果没有传 fn 的话,就会将 event 值对应缓存列表中的 fn 都清空
fns && (fns.length = 0);
} else {
// 若有 fn,遍历缓存列表,看看传入的 fn 与哪个函数相同,如果相同就直接从缓存列表中删掉即可
let cb;
for (let i = 0, cbLen = fns.length; i < cbLen; i++) {
cb = fns[i];
if (cb === fn || cb.fn === fn) {
fns.splice(i, 1);
break
}
}
}
return _this;
},
emit() {
let _this = this;
// 第一个参数是对应的 event 值,直接用数组的 shift 方法取出
let event = [].shift.call(arguments),
fns = [..._this.list[event]];
// 如果缓存列表里没有 fn 就返回 false
if (!fns || fns.length === 0) {
return false;
}
// 遍历 event 值对应的缓存列表,依次执行 fn
fns.forEach(fn => {
fn.apply(_this, arguments);
});
return _this;
}
};
function user1(content) {
console.log('用户1订阅了:', content);
}
function user2(content) {
console.log('用户2订阅了:', content);
}
function user3(content) {
console.log('用户3订阅了:', content);
}
function user4(content) {
console.log('用户4订阅了:', content);
}
// 订阅
eventEmitter.on('article1', user1);
eventEmitter.on('article1', user2);
eventEmitter.on('article1', user3);
// 取消user2方法的订阅
eventEmitter.off('article1', user2);
eventEmitter.once('article2', user4)
// 发布
eventEmitter.emit('article1', 'Javascript 发布-订阅模式');
eventEmitter.emit('article1', 'Javascript 发布-订阅模式');
eventEmitter.emit('article2', 'Javascript 观察者模式');
eventEmitter.emit('article2', 'Javascript 观察者模式');
eventEmitter.on('article1', user3).emit('article1', 'test111');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
class myEventEmitter {
constructor() {
this.eventMap = {}; // 存储事件和监听函数之间的关系
}
// type:事件名称; handler:事件处理函数
on(type, handler) {
// hanlder 必须是一个函数
if (!(handler instanceof Function)) {
throw new Error("hanler必须是函数");
}
// 判断 type 事件对应的队列是否存在
if (!this.eventMap[type]) {
// 若不存在,新建该队列
this.eventMap[type] = [];
}
// 若存在,直接往队列里推入 handler
this.eventMap[type].push(handler);
}
// type:事件名称; params:支持传参
emit(type, params) {
// 假设该事件是有订阅的(对应的事件队列存在)
if (this.eventMap[type]) {
// 将事件队列里的 handler 依次执行出队
this.eventMap[type].forEach((handler, index) => {
handler(params); // 别忘了读取 params
});
}
}
off(type, handler) {
if (this.eventMap[type]) {
this.eventMap[type].splice(this.eventMap[type].indexOf(handler) >>> 0, 1);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# Promise
# 事件循环
# Generator
# iterator
ES6推出,方便创建iterator,Generator是一个返回``iterator`对象的函数
iterator——迭代器
为各种数据结构(Array、Set、Map)提供统一的访问机制。任何数据结构只要部署了Iterator接口,就可以完成遍历操作
作用:
- 使得数据结构的成员能够按某种次序排列
- ES6 创造了一种新的遍历命令for…of循环,Iterator 接口主要供for…of
iterator的结构: 有next方法,该方法返回一个包含value和done两个属性的对象(我们假设叫result)
value是迭代的值,后者是表明迭代是否完成的标志
iterator内部有指向迭代位置的指针,每次调用next,自动移动指针并返回相应的result
原生具备iterator接口的数据结构如下:
- Array
- Map
- Set
- String
- TypedArray
- 函数里的arguments对象
- NodeList对象
这些数据结构都有一个Symbol.iterator属性,可以直接通过这个属性创建迭代器
let arr = ['a','b','c'];
let iter = arr[Symbol.iterator]();
iter.next() // { value: 'a', done: false }
iter.next() // { value: 'b', done: false }
iter.next() // { value: 'c', done: false }
iter.next() // { value: undefined, done: true }
2
3
4
5
6
7
8
for ... of首先调用被遍历集合对象的 Symbol.iterator 方法,该方法返回一个迭代器对象,迭代器对象是可以拥有.next()方法的任何对象,每次循环,调用该迭代器对象上的 .next 方法
对于不具备iterator接口的数据结构,比如Object,我们可以采用自定义的方式来创建一个遍历器
# Generator
function* createIterator() {
yield 1;
yield 2;
yield 3;
}
//generators像正常函数一样被调用,返回iterator
let iterator = createIterator();
console.log(iterator.next().value); // 1
console.log(iterator.next().value); // 2
console.log(iterator.next().value); // 3
2
3
4
5
6
7
8
9
10
11
Generator 是一个普通函数,两个特征:
- function关键字与函数名之间有一个星号
- 函数体内部使用yield语句,定义不同的内部状态
Generator函数的调用方法与普通函数一样,在函数名后面加上一对圆括号。不同的是,调用Generator函数后,该函数不执行,返回的也不是函数运行结果,而是一个指向内部状态的指针对象——遍历器对象(Iterator Object)
function* generator(){
yield 1;
}
console.dir(generator);
2
3
4
generator函数的返回值的原型链上有iterator对象该有的next,说明generator的返回值是一个iterator。除此之外还有函数该有的return方法和throw方法。
generator和普通的函数完全不同。当以function*的方式声明一个Generator生成器时,内部可以有许多状态,以yield进行断点间隔。期间我们执行调用这个生成的Generator,他返回一个遍历器对象,用这个对象上的方法,实现获得yield后面输出的结果
yield和return的区别
- 都能返回紧跟在语句后面的那个表达式的值
- yield更像是一个断点。遇到yield,函数暂停执行,下一次再从该位置继续向后执行,而return语句不具备位置记忆的功能
- 一个函数里面,只能执行一个return语句,但可以执行多次yield表达式
- 正常函数只能返回一个值,因为只能执行一次return;Generator 函数可以返回一系列的值,因为可以有任意多个yield
语法注意点:
- yield表达式只能用在 Generator 函数里面
- yield表达式如果用在另一个表达式之中,必须放在圆括号里面
- yield表达式用作函数参数或放在赋值表达式的右边,可以不加括号
- 如果 return 语句后面还有 yield 表达式,后面的 yield 完全不生效
使用Generator的其余注意事项:
- yield 不能跨函数,需要和*配套使用,别处使用无效
function* createIterator(items) {
items.forEach(function (item) {
// 语法错误
yield item + 1;
});
}
复制代码
2
3
4
5
6
7
- 箭头函数不能用做 generator
Generator到底有什么用呢?
- Generator可以在执行过程中多次返回,它看上去就像一个可以记住执行状态的函数,利用这一点,写一个generator可以实现需要用面向对象才能实现的功能
- Generator还有另一个巨大的好处——把异步回调代码变成“同步”代码
原理
采用 编译 转换思路,运用 状态机 模型,同时 利用闭包保存 函数上下文信息,最终实现新的语言特性
# async/await
JS单线程语言,异步防止用户界面被阻塞
特点
- 异步变成同步,代码更具 表现力和可读性
- 统一异步编程;提供更好的错误堆栈跟踪
ES7提出的关于异步的终极解决方案
- 一说async/await是Generator的语法糖
- 二 说async/await是Promise的语法糖
async/await是Generator的语法糖:
Generator语法糖,表明 aysnc/await实现的就是generator实现的功能。但async/await比generator要好用。因为generator执行yield设下的断点就是不断调用iterator方法,这是个手动调用的过程。针对generator的这个缺点,后面提出了co这个库函数自动执行next,相比之前的方案,这种方式有了进步,但是仍然麻烦。async配合await得到的就是断点执行后的结果。async/await比generator使用更普遍
async函数对 Generator函数的改进,主要体现
- 内置执行器:Generator函数的执行必须靠执行器,不能一次执行完成,所以之后才有了开源的 co函数库。但async和正常的函数一样执行,不用 co函数库,不用 next方法,async函数自带执行器,自动执行
- 适用性更好:co函数库有条件约束,yield命令后面只能是 Thunk函数或 Promise对象,但async函数的 await关键词后面,不受约束
- 可读性更好:async和 await,比起使用 *号和 yield,语义清晰明了
async/await是Promise的语法糖:
如果不使用async/await的话,Promise需要通过链式调用执行then之后的代码
Promise搭配async/await的使用才是正解!
async/await基于Promise。async把promise包装了一下,async函数更简洁,不需要像promise一样需要写then,不需要写匿名函数处理promise的resolve值,也不需要定义多余的data,避免嵌套代码
async是Generator函数的语法糖,async函数返回值promise对象,比generator函数返回值 iterator对象更方便,可使用 await 代替then 指定下一步操作(await==promise.then)
function f() {
return Promise.resolve('TEST');
}
// asyncF is equivalent to f!
async function asyncF() {
return 'TEST';
}
2
3
4
5
6
7
8
9
async方法执行时,遇到await会立即执行,然后把表达式后面的代码放到微任务队列,让出执行栈让同步代码先执行
const one=()=>Promise.resolve('one');
async function myFunc(){
console.log('in function');
const res=await one();
console.log(res);
}
console.log('before function');
myFunc();
console.log('after function');
//before fucntion
//in function
//after funciton
//one
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 定时器原理
var id=setTimeout(fn,delay);初始化一个只执行一次的定时器,这个定时器会在指定的时间延迟delay之后调用函数fn,该setTimeout函数返回定时器的唯一id,可以通过这个id取消定时器的执行var id=setInvertal(fn,delay);与setTimeout类似,它会以delay为周期,反复调用函数fn,直到我们通过id取消该定时器clearInterval(id),clearTimeout(id);这两个函数接受定时器的id,并停止对定时器中指定函数的调用
定时器指定的延迟时间不能得到保证
所有的JS代码都运行在单一线程中,异步事件只有在被触发时,其回调才会执行

这个图是一维的,垂直方向是时间,以毫秒为单位。蓝色的盒子代表正在执行的JS代码所占时间片段
因为单线程在同一时间只能执行一条 代码,每一个代码块(蓝色盒子)都会阻塞其他异步事件的执行
这就意味着,当一个异步事件发生时(例如鼠标点击,定时器触发,一个 XMLHttpRequest 请求完成),它进入了代码的执行队列,执行线程空闲时会依照该执行队列中顺序依次执行代码
总结:
- JS 引擎是单线程的,会迫使异步事件进入执行队列,等待执行
setTimeout和setInterval在执行异步代码时从根本上有所不同- 如果一个定时器事件被阻塞,使得它不能立即执行,它会被延迟,直到下一个可能的时间点,才被执行(可能比指定的
delay时间要长) Interval回调有可能‘背靠背’无间隔执行,interval的回调函数的执行时间比指定的delay时间还要长
JS中定时器的工作原理 (opens new window)
# 💙 原型
# 原型
每个实例对象有有私有属性(proto)指向它构造函数的原型对象。该原型对象有自己的原型对象(proto),层层向上直到对象的原型为null。null没有原型,作为原型链终点
实例是类的具象化产品
对象是一个具有多种属性的内容结构
实例都是对象,对象不一定是实例(Object.prototype是对象但不是实例),构造函数也是对象
prototype是构造函数的属性
__proto__是对象的属性
试图访问对象属性时,它不仅在该对象搜寻,还会搜寻该对象原型,以及该对象的原型的原型,层层向上搜索,直到找到名字匹配的属性或到达原型链的末尾
每个对象都有__proto__属性,指向它的prototype原型对象
每个构造函数都有prototype原型对象
prototype原型对象的constructor指向构造函数本身
有默认constructor属性,记录实例由哪个构造函数创建
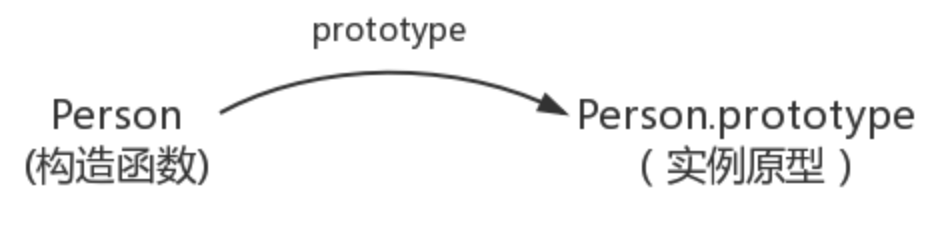
对象都具有的属性,叫_proto_,指向该对象的原型,原型有两个属性,constructor和proto

实例对象和构造函数都可以指向原型,原型有属性指向构造函数或实例吗?
proto与其说是一个属性,不如说是个getter/setter,使用obj._proto_时,可理解为返回Object.getPrototypeOf(obj)
原型都有constructor属性指向关联的构造函数

function Person() {
}
var person = new Person();
console.log(person.__proto__ == Person.prototype) // true
console.log(Person.prototype.constructor == Person) // true 原型对象的constructor指向构造函数本身
// 顺便学习一个ES5的方法,可以获得对象的原型
console.log(Object.getPrototypeOf(person) === Person.prototype) // true
console.log(Object.getPrototypeOf(person))
person.__proto__
Person.prototype//constructor
2
3
4
5
6
7
8
9
10
11
12
13
读取实例属性时,若找不到,会查找与对象关联原型中的属性,若还查不到,就去找原型的原型,一直找到最顶层为止
实例的proto指向构造函数的prototype

# 原型链
每个构造函数都有原型对象(prototype),原型上有属性(constructor)指回构造函数,实例有内部指针指向原型。原型本身也有内部指针指向另一个原型,相应的这个另一个原型也会有个属性指向另一个构造函数,在实例与原型之间形成链式关系
foo.__proto__ => Function.prototype => Function.prototype.__proto__ => Object.prototype => Object.prototype.__proto__ => null
console.log(Object.prototype.__proto__ === null) // true
意思就是Object.prototype没得原型

图中由相互关联的原型组成的练状结构就是原型链(蓝色线)
# 创建没有原型的对象
let obj=Object.create(null)
obj.name='merry'
console.log(obj)
2
3
参考文档https://zh.javascript.info/prototype-methods
# proto、prototype
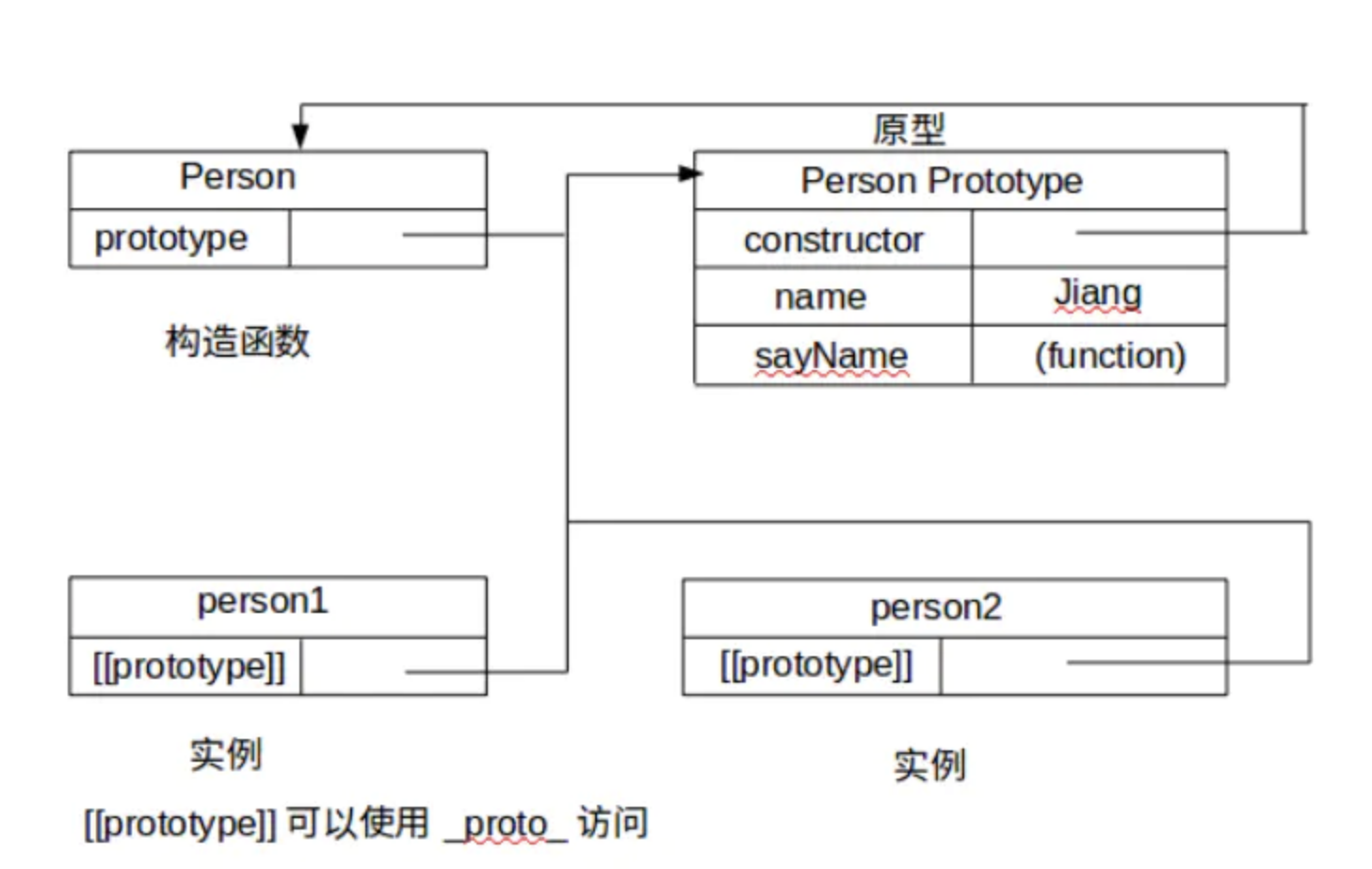
prototype是原型对象
__ proto __ 将对象和该对象的原型相连
特殊的 Function 对象,Function 的 __proto__ 指向自身的 prototype
构造函数 prototype 的 __proto__ 指向构造函数的构造函数的 prototype
构造函数是一个函数对象,通过Function构造器产生
原型对象本身是一个普通对象,普通对象的构造函数是Object
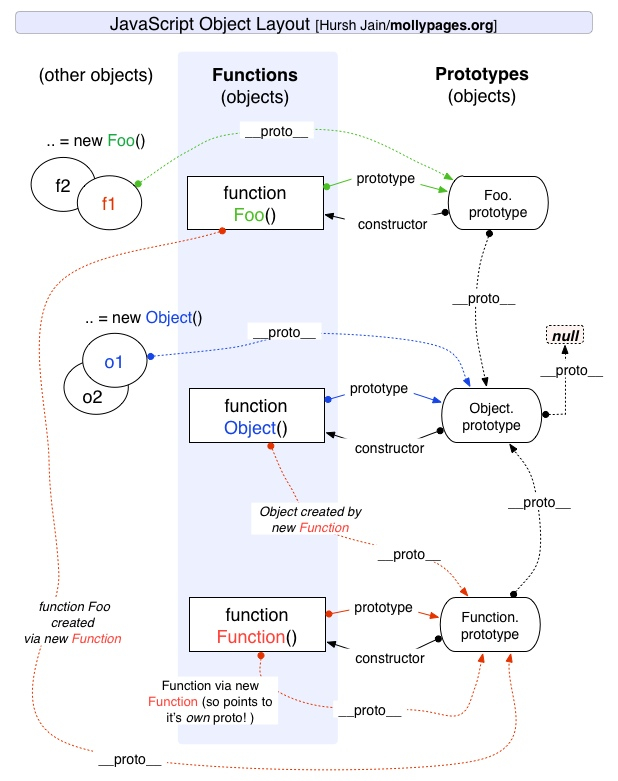
除了Object的原型对象(Object.prototype)的__proto__指向null,其他内置函数对象的原型对象(例如:Array.prototype)和自定义构造函数的 __proto__都指向Object.prototype, 因为原型对象本身是普通对象
Object.prototype.__proto__ = null;
Array.prototype.__proto__ = Object.prototype;
Foo.prototype.__proto__ = Object.prototype;
2
3
- 一切对象都继承
Object对象,Object对象直接继承根源对象null - 一切函数对象(包括
Object对象),都继承自Function对象 Object对象直接继承自Function对象Function对象的__proto__指向自己的原型对象,最终还是继承自Object对象
# 原型、原型链
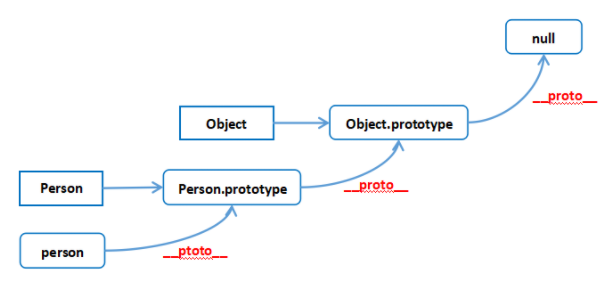
需要new关键字,成为“构造器constructor或构造函数”
通过prototype定义的属性,再被多个实例化后,引用地址是同一个
继承链 从祖父——到爷爷——到爸爸——到自己
- constructor指向构造函数,每个对象的
__proto__指向创建它的构造函数的prototype,构造函数的prototype也有__proto__,指向他的父辈或者是Object,当查找一个对象中不存在的属性时,会去它的__proto__、__proto__中的__proto__中寻找,直到找到或是null为止 instanceof判断对象的__proto__和构造函数的prototype是不是同一个地址Object.setPrototypeOf改变对象的__proto__
原型(prototype):一个对象,实现对象的属性继承,简单理解为对象的爹
prototype可通过Object.getPrototypeOf() 和 Object.setPrototypeOf() 访问器访问
当继承的函数被调用时,this (opens new window) 指向当前继承的对象,而不是继承的函数所在原型对象
不是所有对象都有原型
class A{}
class B extends A{}
const a = new A()
const b = new B()
a.__proto__
b.__proto__
B. __proto__
B. prototype.__proto__
b.__proto__.__proto__
2
3
4
5
6
7
8
9
# Object是Function实例,那Function是谁的实例
Function.__proto__=== Function.prototype;
//true
2
Function构造函数的prototype和__proto__属性指向同一个原型,说明Function对象是Function构造函数创建的一个实例?
Yes and No
Yes :
按照JS中“实例”定义,a 是 b 的实例即 a instanceof b 为 true,默认是 b.prototype 在 a 的原型链上。而 Function instanceof Function 为 true,本质上即 Object.getPrototypeOf(Function) === Function.prototype,符合定义
No :
Function 是 built-in 的对象,不存在“Function对象由Function构造函数创建”会造成鸡生蛋蛋生鸡问题。实际上 直接写一个函数时(如 function f() {} 或 x => x),不存在调用 Function 构造器,只有显式调用 Function 构造器时(如 new Function('x', 'return x') )才有
本质上,a instanceof b 只是运算,满足条件返回 true/false,我们说 a 是 b 的实例时,只是表示他们符合某种关系。JS 是强大的动态语言,你甚至可在运行时改变这种关系,如修改对象原型改变instanceof 运算的结果。ES6+ 已允许通过 Symbol.hasInstance 自定义 instanceof 运算
Function.prototype//"function"
后来意见:
先有Object.prototype, Object.prototype构造Function.prototype,Function.prototype构造Object和Function
Object.prototype是鸡,Object和Function都是蛋
# 栗子
不是没有,只是是undefined,所以不会继续往上找
function A(x) {
this.x = x
}
A.prototype.x = 1
function B(x) {
this.x = x
}
B.prototype = new A()
var a = new A(2), b = new B(3)
delete b.x
console.log(a.x)
console.log(b.x)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
此题涉及的知识点 包括变量定义提升、this指针指向、运算符优先级、原型、继承、全局变量污染、对象属性及原型属性优先级等
function Foo () {
getName = function () { console.log(1) }
/*
是函数赋值语句,没有var声明,先向当前Foo函数作用域寻找getName变量,没有,再向当前函数作用域上层寻找是否有getName变量,找到了,即console.log(4)函数,将此变量赋值为console.log(1)
*/
return this;//指向window
}
Foo.getName = function () { console.log(2) }
Foo.prototype.getName = function () { console.log(3) }
var getName = function () { console.log(4) }
function getName () { console.log(5) }
Foo.getName();//2
getName();//4
/*
所有声明变量或声明函数都会被提升到当前函数顶部
函数提升优先级高于变量提升,不会被变量声明覆盖,但会被变量赋值之后覆盖
*/
Foo().getName();//1
getName();//1
new Foo.getName();//2
/*
相当于 new (Foo.getName)(),将getName作为了构造函数执行
*/
new Foo().getName();//3
/*
相当于(new Foo()).getName(),先执行Foo函数,有返回值
this本就代表当前实例化对象,调用this的getName函数,prototype中寻找getName
*/
new new Foo().getName();//
/*
new ((new Foo()).getName)()
先初始化Foo的对象,将原型上的getName作为构造函数再次new
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
构造函数的返回值
传统中,构造函数不该有返回值,实际执行的返回值就是实例化对象
JS中构造函数可有可不有返回值
- 没有返回值就返回实例化对象
- 有返回值就检查返回值是否为引用类型,非引用类型则返回实例化对象
- 若返回值是引用类型,则返回这个引用类型
# 继承
构造函数会在每一个实例上都创建一遍!
使用原型模式定义的属性和方法由所有实例共享!
# 原型链
原型链向上查找的机制实现继承,子类prototype原本指向 子类构造函数本身,改变子类原型指向,把子类的原型指向父类实例,酱紫可在子类的实例上,既能继承父类属性和方法,也能继承父类原型属性和方法
function Animal() { // 父类
this.name = '父类name -> Animal';
this.arr = [1,2,3]
}
Animal.prototype.speak = function () { // 父类原型上的方法
return '父类原型的方法 speak --->'
};
function Dog(type) {
this.type = type
}
console.log('---->>', Dog.prototype); // 未改变指向之前的原型 指向子类函数本身: Dog{}
Dog.prototype = new Animal(); #// 子类原型指向父类实例
let dog1 = new Dog('dog1');
let dog2 = new Dog('dog2');
console.log(dog1.name); // 父类name -> Animal
dog1.arr.push('又push了一个元素');
console.log(dog1.speak()); // 父类原型的方法 speak --->
console.log(dog2.name); // 父类name -> Animal
console.log(dog2.arr); // [ 1, 2, 3, '又push了一个元素' ]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
缺点
- 引用类型的属性被所有实例共享,我们通常不希望2个子类实例相互影响
- 创建Child实例时,不能向Parent传参
# 构造函数(经典继承)
call实现继承,本质是改变this的指向,父类的this指向当前子类的上下文,这样在父类中通过this设置的属性/方法被写到子类上
function Animal() {
console.log('父类里的 this ------',this);
this.name = 'Animal'
}
Animal.prototype.speak = function () {
console.log('speak -->');
};
function Dog() {
console.log('子类里的 this --->>>',this);
Animal.call(this); // 这时父类里的this是 Dog{}
this.type = 'dog'
}
var dog = new Dog(); // new 的时候执行 Obj 构造函数, 调用父类
console.log(dog.name); // Fun
console.log(dog.speak); // undefined
function Cat() {
Animal.call(this) // 这时父类里的this是 Cat{}
}
var cat = new Cat(); // new 的时候执行 Obj2 构造函数, 调用父类
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 避免了 引用类型的属性被所有实例共享
- 可以在 Child 中向 Parent 传参
缺点
- 方法都在构造函数中 定义,每次创建实例都会创建一遍方法
- 只能继承父类构造函数上的属性和方法,不能继承父类原型上的属性和方法
# 组合继承
原型链继承+经典继承 双剑合璧
子类中执行Parent.call(this) 改变当前子类Child的父类中this,等于 将父类构造函数在子类中调用执行了一遍, 将父类构造函数本身 的属性和方法设置到了子类,让子类单独维护一套从父类构造函数继承来的属性和方法,避免其沿着原型链向上查找共同的父类 属性和方法,保持了相互独立
然后 再次通过改变子类的原型指向父类的实例,实现继承父类原型的属性和方法
function Parent() {
this.name = 'I am Parent';
this.arr = [1,2,3]
}
Parent.prototype.speak = function () {
console.log('我是父类原型上的方法 speak --> ');
};
function Child() {
Parent.call(this); // 构造函数继承的 call 方法
this.type = 'child'
}
Child.prototype = new Parent(); // 子类的原型指向父类的实例
let child1 = new Child();
let child2 = new Child();
child1.arr.push('child1 push一个元素');
console.log(child1.arr); // [ 1, 2, 3, 'child1 push一个元素' ]
console.log(child2.arr); // [ 1, 2, 3 ]
console.log(child1.speak); // [Function] 可以访问父类原型的熟悉和方法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
融合 原型链 继承和构造函数的优点,JS最常用继承模式
缺点
- 父类构造函数被执行两遍,分别是 Parent.call(this) 和Child.prototype=new Parent()
- 父类构造函数的属性在子类自身和子类原型上都存在,若delete child.arr时,只是删除了child1上的arr属性,其原型上的arr属性依然存在,原型链上依旧可以查找到
优化: 把之前 子类原型指向父类实例, 改为 子类原型指向父类原型来只继承父类原型属性和方法, 避免重复继承父类本身属性方法
同样有缺点:
Child.prototype == Parent.prototype, 父类和子类的实例无法区分
# 原型式继承
function createObj(o) {
function F(){}
F.prototype = o;
return new F();
}
2
3
4
5
ES5 Object.create的模拟实现,将传入对象 作为 创建的对象的原型
create创建中间对象,将2个对象区分开
Object.assign 实现同时继承多个对象, 如Object.assign(对象1, 对象2, ...对象N) 实现同时继承多个对象
包含引用类型的属性值都会共享相应的值——和原型链 继承一样
function Parent() {
this.name = 'I am Parent';
this.arr = [1,2,3]
}
Parent.prototype.speak = function () {
console.log('我是父类原型上的方法 speak --> ');
};
function Child() {
Parent.call(this); // 构造函数继承的 call 方法
this.type = 'child'
}
// 子类原型指向一个新创建的对象,这个对象依据父类原型创建
Child.prototype = Object.create(Parent.prototype);
Child.prototype.constructor = Child; // 让子类原型的构造函数 重新指回 子类本身构造函数
let child1 = new Parent();
let child2 = new Child();
console.log(child1 instanceof Parent); // true
console.log(child1 instanceof Child); // false 区分出其不是子类的实例,而是父类的实例
console.log(child2 instanceof Child); // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 寄生式继承
创建一个仅用于封装继承过程的函数,该函数在内部以某种形式 做增强对象,再返回对象
function createObj (o) {
var clone = Object.create(o);
clone.sayName = function () {
console.log('hi');
}
return clone;
}
2
3
4
5
6
7
缺点
和借用构造函数一样,每次创建对象都会创建一遍方法
# 寄生组合式继承
组合继承 最大缺点——调用2次 父构造方法
- 设置子实例的原型时
- 创建子类型的实例时
如何 避免 重复调用?
如果我们不使用Child.prototype=new Parent(),而是间接让 Child.prototype访问Parent.prototype呢?
// 精简版
class Child {
constructor() {
// 调用父类的构造函数
Parent.call(this);
// 利用Object.create生成一个对象,新生成对象的原型是父类的原型,并将该对象作为子类构造函数的原型,继承了父类原型上的属性和方法
Child.prototype = Object.create(Parent.prototype);
// 原型对象的constructor指向子类的构造函数
Child.prototype.constructor = Child;
}
}
// 通用版
function Parent(name) {
this.name = name;
}
Parent.prototype.getName = function() {
console.log(this.name);
};
function Child(name, age) {
// 调用父类的构造函数
Parent.call(this, name);
this.age = age;
}
function createObj(o) {
// 目的是为了继承父类原型上的属性和方法,在不需要实例化父类构造函数的情况下,避免生成父类的实例,如new Parent()
function F() {}
F.prototype = o;
// 创建一个空对象,该对象原型指向父类的原型对象
return new F();
}
// 等同于 Child.prototype = Object.create(Parent.prototype)
Child.prototype = createObj(Parent.prototype);
Child.prototype.constructor = Child;
let child = new Child("tom", 12);
child.getName(); // tom
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
优点——引用类型最理想的继承方式
只调用一次Parent 构造函数,避免了在Parent.prototype上面创建不必要的、多余的属性
同时,原型链能保持不变,能正常使用instanceof和isPrototypeOf
# class
基于寄生组合式继承,是目前最理想的继承方式
ES6的extends实现(底层 寄生组合式继承)
是原型系统上的语法糖
class Game{
constructor(name){
this.name = name;
}
}
const game = new Game('Fornite');
console.log(game.__proto__ === Game.prototype);
2
3
4
5
6
7
8
# class原理
手撕class
// Child 为子类的构造函数, Parent为父类的构造函数
function selfClass(Child, Parent) {
// Object.create 第二个参数,给生成的对象定义属性和属性描述符/访问器描述符
Child.prototype = Object.create(Parent.prototype, {
// 子类继承父类原型上的属性和方法
constructor: {
enumerable: false,
configurable: false,
writable: true,
value: Child
}
});
// 继承父类的静态属性和静态方法
Object.setPrototypeOf(Child, Parent);
}
// 测试
function Child() {
this.name = 123;
}
function Parent() {}
// 设置父类的静态方法getInfo
Parent.getInfo = function() {
console.log("info");
};
Parent.prototype.getName = function() {
console.log(this.name);
};
selfClass(Child, Parent);
Child.getInfo(); // info
let tom = new Child();
tom.getName(); // 123
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
let a=5
class A{
a=10
fn(){
console.log(this)
console.log(this.a)
}
}
const b=new A().fn
b()
2
3
4
5
6
7
8
9
10
11
# super
用作函数
super作为函数调用时 代表父类 构造函数,子类构造函数必须执行 super(),super()只能用在子类的构造函数中
作为函数调用时,this指的是子类实例
用作对象
1、super在普通方法及this
super作为对象时,在普通方法中,指向父类 原型对象(所以若父类的方法/属性 定义在实例上,无法通过super调用);静态方法中 指向父类
子类普通方法通过super调用父类方法时,方法内部this指向当前子类实例
2、super在静态方法中及this
super作为对象,用在静态方法中,super直接指向父类,而不是父类 原型对象
子类静态方法中通过super调用父类方法时,方法内部this指向当前子类,而不是子类实例
# ✅创建对象
# 工厂方法
# 构造函数
# 原型模式
# 构造函数+原型模式
# 动态原型
判断实例上是否有函数
没有的话,就在原型上定义一个函数
# 寄生构造函数
# 稳妥构造函数
安全
不用this和new
# ❤️ proxy?
ES6新增功能
在目标对象前设一层"拦截",外界对该对象的访问,必须先通过这层拦截,可过滤和更改外界访问
代理是一种很有用的抽象机制,能够通过API只公开部分信息,同时还能对数据源进行全面控制
在需要公开API,同时又要避免使用者直接操作底层数据时,可使用代理
比如,实现一个传统的栈数据类型,数组可以作为栈使用,但要保证人们只使用push pop 和length,我们可以基于数组创建一个代理对象,只对外公开这个三个对象成员
Vue3.0中使用Proxy替换原本的Object.defineProperty实现数据响应式
let p = new Proxy(target, handler)
target 表示需要添加代理的对象,handler表示自定义对象中的操作,可以用来自定义set或get函数
使用Proxy实现数据响应式:
let onWatch = (obj, setBind, getLogger) => {
let handler = {
get(target, property, receiver) {
getLogger(target, property)
return Reflect.get(target, property, receiver)
},
set(target, property, value, receiver) {
setBind(value, property)
return Reflect.set(target, property, value)
}
}
return new Proxy(obj, handler)
}
let obj = { a: 1 }
let p = onWatch(
obj,
(v, property) => {
console.log(`监听到属性${property}改变为${v}`)
},
(target, property) => {
console.log(`'${property}' = ${target[property]}`)
}
)
p.a = 2 // 监听到属性a改变
p.a // 'a' = 2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
自定义set和get函数,在原本逻辑中插入函数逻辑,实现 在对 对象任何属性进行读写时 发出通知
如果 是实现Vue中的响应式,需要在get中收集依赖,在set派发更新,Vue3.0使用Proxy代替原来API的原因在于 Proxy无需一层层递归为每个属性添加代理,一次即可完成以上操作,性能更好,Proxy可以完美监听到任何方式的数据改变,兼容性 不太好
const obj = {
name: '徐小夕',
age: '120'
}
const proxy = new Proxy(obj, {
get(target, propKey, receiver) {
console.log('get:' + propKey)
return Reflect.get(target, propKey, receiver)
},
set(target, propKey, value, receiver) {
console.log('set:' + propKey)
return Reflect.set(target, propKey, value, receiver)
}
})
console.log(proxy.name) // get:name 徐小夕
proxy.work = 'frontend' // set:work frontend
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Reflect
配合proxy使用,将对象的一些明显属于语言内部的方法放到Reflect对象上,并修改某些对象方法的返回结果
# 🔥 new
创建给定构造函数的实例,可以访问构造函数的属性方法,同时实例和构造函数通过原型链接起来
new做了如下工作:
- 创建新对象
- 将对象和构造函数通过原型链连接
- 将构造函数中的this绑定到新建的对象
- 根据构造函数返回类型判断,若是原始值则忽略,若是对象则返回
function Person(name, age){
this.name = name;
this.age = age;
}
const person1 = new Person('Tom', 20)
console.log(person1) // Person {name: "Tom", age: 20}
2
3
4
5
6

实现
function myNew2(Func, ...args) {
const obj = {};
obj.__proto__ = Func.prototype;
let res = Func.apply(obj, args);
return res instanceof Object ? res : obj;
}
2
3
4
5
6
// 第二版的代码
function objectFactory() {
var obj = new Object(),
Constructor = [].shift.call(arguments);
obj.__proto__ = Constructor.prototype;
var ret = Constructor.apply(obj, arguments);
return typeof ret === 'object' ? ret : obj;
};
2
3
4
5
6
7
8
构造函数中 不要显示返回任何值!!
因为返回 原始值不生效,返回对象会导致new失效!
为啥
构造函数不是由我们的代码直接调用,是由运行时的内存分配和对象初始化代码调用。它的返回值(编译为机器码时实际上有一个)对用户来说不透明——所以,我们不能指定它
let a=[]//let a=new Array()
function(){} //let a=new Function(){}
2
# 🍉 懒加载
过度使用的弊端
- 减慢快速滚动的速度
- 页面缓冲
- 内容变化导致延迟
何时使用
- 懒加载不妨碍网页使用的内容
# lazy
<img src="./example.jpg" loading="lazy">
- loading
- 判断元素是否在视口
- 递归获取滚动容器
- 添加滚动事件
- 元素出现在视口中 展示真正内容,取消监控事件
判断元素是否出现在视口
- offsetTop计算body到元素距离(繁琐)
- getBoundingClientRect计算
# offsetTop
clientHeight 包括元素的内容 和内边距,不包括边框
offsetTop 元素的偏移量,获取元素到有定位的父盒子顶部距离
先给图片一个占位资源:
<img src="default.jpg" data-src="http://www.xxx.com/target.jpg" />
监听 scroll 判断图片是否到达视口:
let img = document.getElementsByTagName("img");
let num = img.length;
let count = 0;//计数器,从第一张图片开始计
lazyload();//首次加载别忘了显示图片
window.addEventListener('scroll', lazyload);
function lazyload() {
let viewHeight = document.documentElement.clientHeight;//视口高度
let scrollTop = document.documentElement.scrollTop || document.body.scrollTop;//滚动条卷去的高度
for(let i = count; i <num; i++) {
// 元素现在已经出现在视口中
if(img[i].offsetTop < scrollHeight + viewHeight) {
if(img[i].getAttribute("src") !== "default.jpg") continue;
img[i].src = img[i].getAttribute("data-src");
count ++;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
最好对 scroll 事件做节流处理,以免频繁触发:
节流就是一段时间内执行一次
// throttle函数我们上节已经实现
window.addEventListener('scroll', throttle(lazyload, 200));
function throttle(fn,wait){
let pre=0;
return function(){
let now=Date now();
if(now-pre>=wait){
pre=now;
fn.apply(this,arguments);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# getBoundingClientRect
判断图片是否出现在当前视口,返回 DOMRect对象,有left, top, right, bottom, x, y, width,height属性
const target = document.querySelector('.target');
const clientRect = target.getBoundingClientRect();
console.log(clientRect);
// {
// bottom: 556.21875,
// height: 393.59375,
// left: 333,
// right: 1017,
// top: 162.625, 元素到视窗顶部的距离
// width: 684
// }
2
3
4
5
6
7
8
9
10
11
12
图片不可以看见,说明图片到窗口顶部距离>窗口显示区高度
图片可以看见,说明图片距离视窗顶部距离<窗口显示区高度
上述的 lazyload 函数改成下面这样:
function lazyload() {
for(let i = count; i <num; i++) {
// 元素现在已经出现在视口中
if(img[i].getBoundingClientRect().top < document.documentElement.clientHeight) {
if(img[i].getAttribute("src") !== "default.jpg") continue;
img[i].src = img[i].getAttribute("data-src");
count ++;
}
}
}
2
3
4
5
6
7
8
9
10
缺点:即使图片加载完成,监听到滚动事件,还是会触发函数
多2个处理
- 图片全部加载后移除事件监听
- 加载完的图片从imgList移除
let imgList = [...document.querySelectorAll('img')]
let length = imgList.length
const imgLazyLoad = (function() {
let count = 0
return function() {
let deleteIndexList = []
imgList.forEach((img, index) => {
let rect = img.getBoundingClientRect()
if (rect.top < window.innerHeight) {
img.src = img.dataset.src
deleteIndexList.push(index)
count++
if (count === length) {
document.removeEventListener('scroll', imgLazyLoad)
}
}
})
imgList = imgList.filter((img, index) => !deleteIndexList.includes(index))
}
})()
// 这里最好加上防抖处理
document.addEventListener('scroll', imgLazyLoad)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
防抖指的是 n s 后执行一次,重复触发则重新计时

# Intersection Observer
重叠观察者,判断两个元素是否重叠,不用事件监听,性能比getBoundingClientRect好 浏览器内置API,实现监听window的scroll事件、判断是否在视口中、节流三大功能
let img = document.getElementsByTagName("img");
const observer = new IntersectionObserver(changes => {
//changes 是被观察的元素集合
for(let i = 0, len = changes.length; i < len; i++) {
let change = changes[i];
// 通过这个属性判断是否在视口中
if(change.isIntersecting) {
const imgElement = change.target;
imgElement.src = imgElement.getAttribute("data-src");
observer.unobserve(imgElement);
}
}
})
Array.from(img).forEach(item => observer.observe(item));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 💚 防抖、节流
浏览器的 resize、scroll、keypress、mousemove 等事件在触发时,不断调用事件回调,浪费资源
防抖(debounce) 和 节流(throttle) 减少调用频率
设置事件频率为500ms,2s内,频繁触发函数
节流——每隔500ms执行一次( 隔一段时间 再执行)
防抖——不管调用多少次,在2s后只会执行一次 (一段时间之后执行)

# 防抖
控制次数
n 秒后再执行,若在 n 秒内重复触发,会重新计时
高频到最后一次操作,这事儿需要等待,如果你反复操作,我就重新计时
函数被连续触发,只执行最后一次
原理:维护一个定时器,延迟计时以最后一次触发为计时起点,到达延迟时间后触发函数执行
# 普通版
支持this 和 event 对象
function debounce(fn, wait) {
// 4、创建一个标记用来存放定时器的返回值
let timer = null;
// 返回闭包函数 ,闭包保存timer,保证其不被销毁,重复点击会清理上一次的定时器
return function () {
let that = this;
// 5、每次当用户点击/输入的时候,把前一个定时器清除
if (timer) {
clearTimeout(timer);
timer = null;
}
// 6、创建一个新的 setTimeout,保证点击按钮后的 interval 间隔
// 如果用户还点击了的话,不会执行 fn 函数
timer = setTimeout(() => {
fn.call(that, arguments);
}, wait);
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
使用
var node = document.getElementById('layout')
function getUserAction(e) {
console.log(this, e) // 分别打印:node 这个节点 和 MouseEvent
node.innerHTML = count++;
};
node.onmousemove = debounce(getUserAction, 1000)
2
3
4
5
6
# 非立即执行版
感觉 和普通版 是一个道理??
<body>
<button id="debounce">点击</button>
<script>
window.onload = function () {
var mydebounce = document.getElementById("debounce")
mydebounce.addEventListener("click", debounce(sayDebounce, 1000))
}
//防抖函数
function debounce(fn, time) {
let timer = null;
return function () {
let context = this;
if (timer) clearTimeout(timer); //清除前一个定时器
timer = setTimeout(() => { //在时间间隙内再次点击不会执行fn函数
fn.apply(context, arguments);
}, time || 500)
}
}
//要防抖的事件处理
function sayDebounce() {
console.log("处理防抖的事件写在这里,比如发送请求");
}
</script>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 立即执行版
如果timer不存在的话,设置flag标志立即调用
function debounce(fn,time) {
let timer = null
return function () {
let context = this
if(timer) clearTimeout(timer) //清除前一个定时器
let callNow = !timer
timer = setTimeout(()=>{
timer = null
},time || 500)
if (callNow) fn.apply(context,arguments)
}
}
2
3
4
5
6
7
8
9
10
11
12
# 双剑合璧版
如果需要立即执行,可加入第三个参数判断
window.onload = function () {
var mydebounce = document.getElementById("debounce")
mydebounce.addEventListener("click", debounce(sayDebounce, 1000, true))
}
//immediate 为true表 立即执行
function debounce(func, wait, immediate) {
let timer;
return function () {
let context = this;
if (timer) clearTimeout(timer);
if (immediate) {
var callNow = !timer;//第一次会立即执行,后面每次触发时执行
timer = setTimeout(() => {
timer = null;
}, wait)
if (callNow) func.apply(context, arguments)
} else {
timer = setTimeout(function () {
func.apply(context, arguments)
}, wait);
}
}
}
function sayDebounce() {
console.log("处理防抖的事件写在这里,比如发送请求");
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 加强版
触发过于频繁导致一次响应都没有,希望到了固定时间必须给用户一个响应
function debounce(fn, await) {
let last = 0;
let timer = null;
return function () {
let that = this;
let now = new Date();
if (now - last < await) {
clearTimeout(timer);
setTimeout(() => {
last = now;
fn.apply(that, arguments);
}, await);
} else {
// 时间到了,必须给响应
last = now;
fn.apply(that, arguments);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 取消debounce(终极版)
# 节流
用户反复触发一些操作,如 鼠标移动,需要一个"巡视"的间隔时间,不管用户期间触发多少次,只会在间隔点上执行给定的回调
水龙头的水一直往下流,浪费水,我们可以把龙头关小,让水一滴一滴流,每隔一段时间掉下来一滴水
n 秒内只运行一次,若在 n 秒内重复触发,只有一次生效
稀释函数的执行频率
function throttle(fn) {
// 4、通过闭包保存一个标记
let canRun = true;
return function () {
// 5、判断标志是否为 true,不为 true 则中断
if (!canRun) {
return;
}
// 6、将 canRun 设置为 false,防止执行之前再被执行
canRun = false;
// 7
setTimeout(() => {
fn.call(this, arguments);
// 8、执行完事件后,重新将这个标志设置为 true
canRun = true;
}, 1000);
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 时间戳 首节流
立即执行,每wait执行一次,停止触发后不再执行
时间戳
function throttle(fn, wait) {
//记录第一次调用时间
let preTime = 0;
return function () {
const that = this;
let nowTime = Date.now();
// 如果两次时间间隔 超过了指定时间,则执行函数
if (nowTime - preTime >= wait) {
//将现在的时间设置为上一次执行时间
preTime = nowTime;
return fn.apply(that, arguments);
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 定时器 尾节流
不会立即执行,每wait执行一次,停止触发后,再执行一次
定时器
function throttle(fn, wait = 500) {
let timer = null;
return function () {
if (!timer) {
timer = setTimeout(() => {
fn.apply(this, arguments);
//执行完毕后重置定时器
timer = null;
}, wait);
}
};
};
2
3
4
5
6
7
8
9
10
11
12
# 双剑合璧版
立刻执行,停止触发后还能再执行一次
时间戳+定时器
function throttle(fn, await) {
// 初始化定时器
let timer = null;
// 上一次调用时间
let prev = null;
return function () {
// 现在触发事件时间
let now = Date.now();
// 触发间隔是否大于await
let remaining = await - (now - prev);
clearTimeout(timer);
// 如果间隔时间满足await
if (remaining <= 0) {
fn.apply(this, arguments);
prev = Date.now();
} else {
// 否则,过了剩余时间执行最后一次fn
timer = setTimeout(() => {
fn.apply(this, arguments)
}, await);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 应用场景
防抖在连续的事件只触发一次:
- 鼠标滑动
- 登录注册等表达提交操作用户单击过快触发多次请求
- 编辑器内容实时保存
- iinput.change实时输入校验(输入实时查询,不可能摁一个字就查一次,肯定是输一串,统一查询一次)
- window.resize(窗口缩放完成后,才会重新计算部分 DOM 尺寸)
节流在间隔一段时间执行一次回调的场景:
- 搜索框,搜索联想功能
- 滑动定时/滑动高度,埋点请求
- 运维系统查看日志,n秒刷新
- 进度条位置计算
- 监听 mousemove、 鼠标滚动等事件,常用于:拖拽动画、下拉加载、滚动加载、加载更多或滚到底部监听
节流常用在比防抖刷新更频繁的场景,大部分需要涉及动画操作
# 🍉 模块化
指定规范约束我们按照规范写代码
规范包括模板可暴露的属性 和 可导入自己所需的属性
# 特点
- 解决命名污染,全局污染,变量冲突等
- 内聚私有,变量不能被外部访问
- 更好的分离,按需加载
- 引入其他模块可能存在循环引用
- 代码抽象,封装,复用
- 避免通过script标签从上至下加载资源
- 大型项目资源难以维护
# CommonJS
服务端解决方案。加载速度快(因为模块·文件一般存在本地硬盘)
Node中 **每个文件是一个模块,**有自己的作用域。在一个文件里面定义的变量、函数 都是私有的,对其他文件不可见
运行时加载,只能在运行时才能确定一些东西
同步加载,加载完成后,才能执行后续操作。 文件都在本地,同步导入即使卡住主线程影响也不大
导出时是值拷贝,想更新值,必须重新导入
模块在首次执行后会缓存,再次加载只返回缓存结果,若想再次执行,可清除缓存
模块加载的顺序就是代码出现的顺序
# 基本语法
核心变量——exports,module.exports,require
- 暴露模块:
module.exports = value或exports.xxx = value - 引入模块:
require(xxx),xxx为模块 名/文件路径
CommonJS规范规定,每个模块内部,module变量代表当前模块,它是一个对象,它的exports属性是对外的接口。加载某个模块,其实是加载该模块的module.exports属性
// 加载模块
var example = require('./example.js');
var config = require('config.js');
var http = require('http');
// 对外暴露模块
module.exports.example = function () {
...
}
module.exports = function(x){
console.log(x)
}
exports.xxx=value;
2
3
4
5
6
7
8
9
10
11
12
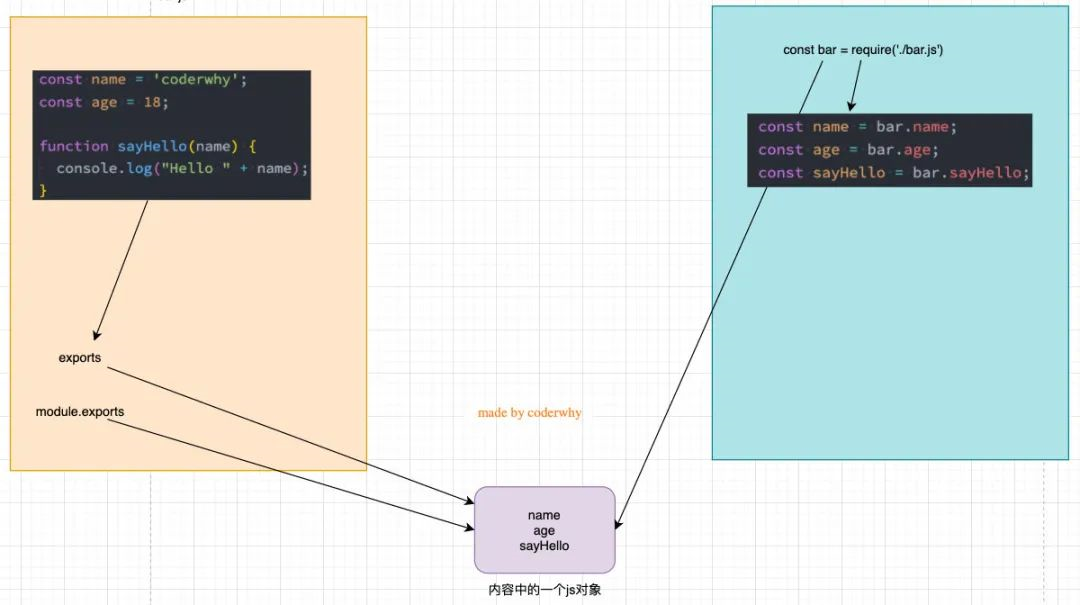
require 读入并执行一个JS文件,返回该模块的exports对象。如果没有发现指定模块,报错
nodejs主要用于服务器编程,模块文件一般存在本地硬盘,所以加载比较快,不用考虑异步加载——使用CommonJS规范
浏览器环境,要从服务器端加载模块,用CommonJS需要等模块下载完并运行后才能使用,将阻塞后面代码执行,这时必须采用非同步模式,浏览器端一般采用AMD规范,解决异步加载
- exports 记录当前模块导出的变量
- module 记录当前模块的详细信息
- require 进行模块的导入
# exports、module.exports
两者指向同一块内存
- 绑定同一属性时,2者相等
- 不能直接赋值给exports,即不能直接使用exports={}
- 只要最后直接给module.exports赋值了,之前绑定的属性都会被覆盖掉
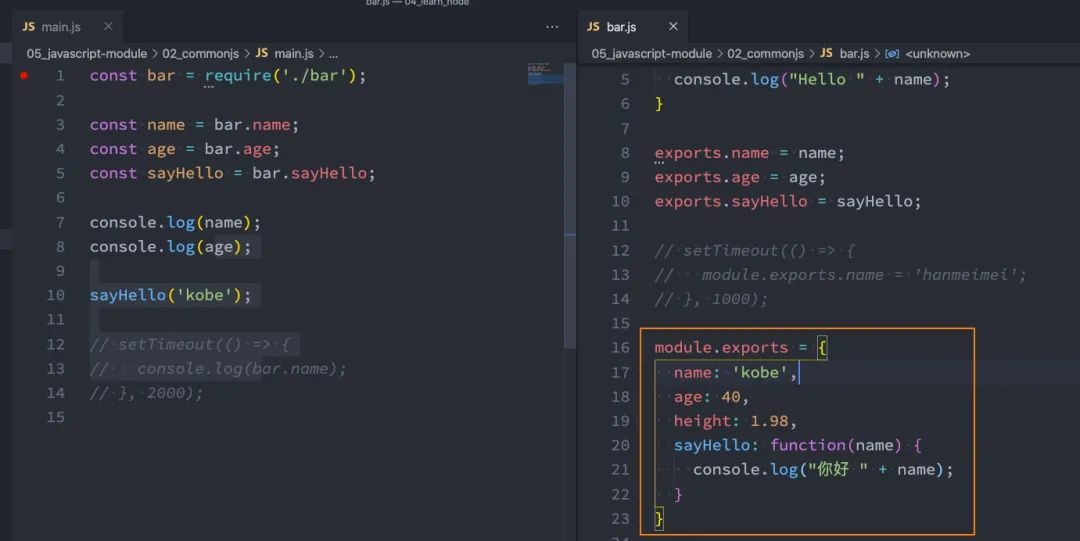
和exports对象没有任何关系了,exports 你自己随便玩吧
module.exports 现在导出一个自己的对象,不带你玩了
新的对象 取代了 exports 的导出,即 require 导入的对象 是新的对象
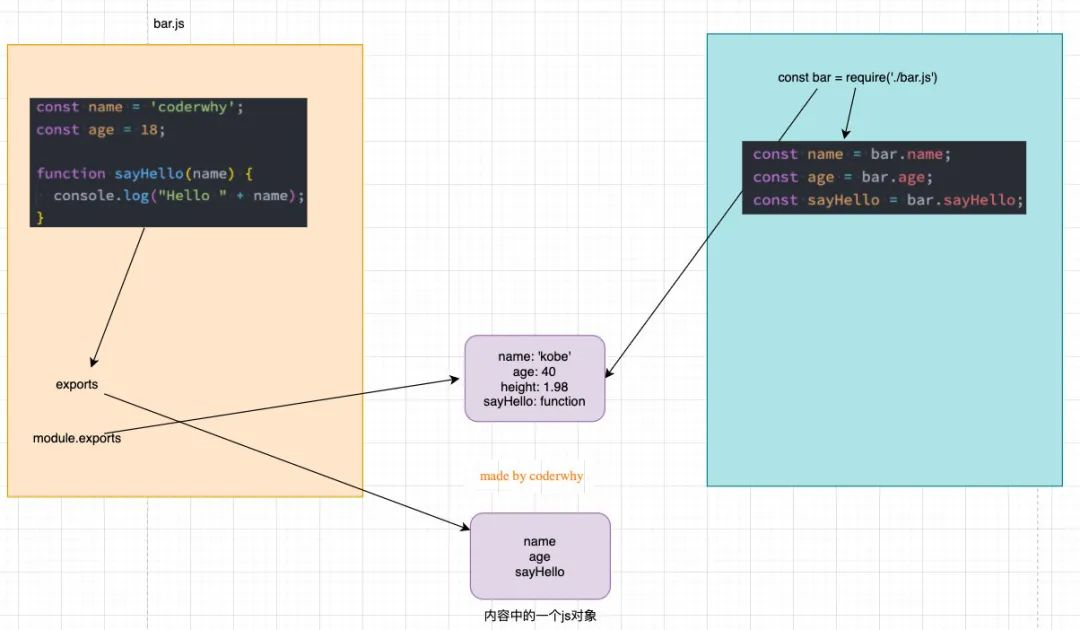
# 循环引入
//index.js
var a = require('./a')
console.log('入口模块引用a模块:',a)
// a.js
exports.a = '原始值-a模块内变量'
var b = require('./b')
console.log('a模块引用b模块:',b)
exports.a = '修改值-a模块内变量'
// b.js
exports.b ='原始值-b模块内变量'
var a = require('./a')
console.log('b模块引用a模块',a)
exports.b = '修改值-b模块内变量'
2
3
4
5
6
7
8
9
10
11
12
13
14
15

CommonJS做了处理——模块缓存
每一个模块都会先加入缓存再执行,每次遇到require都先检查缓存,这样不会出现死循环;借助缓存,就能找到输出的值
# 多次引入
//index.js
var a = require('./a')
var b= require('./b')
// a.js
module.exports.a = '原始值-a模块内变量'
console.log('a模块执行')
var c = require('./c')
// b.js
module.exports.b = '原始值-b模块内变量'
console.log('b模块执行')
var c = require('./c')
// c.js
module.exports.c = '原始值-c模块内变量'
console.log('c模块执行')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17

c模块只执行一次,第二次读取时,发现有缓存,直接读取缓存
# 路径解析
为什么简单写一个'React'就能找到包的位置
路径分类
- 内置核心模块,node已将其编译为二进制代码,直接书写标识符fs、http就可
- 本地文件模块,自己书写的文件模块,需要使用'./' "../"开头,require将其转化为真实路径
- 第三方模块,npm下载的包,用到paths变量,依次查找当前路径下的node_modules->父级目录的node_modules->根目录为止
# AMD
Asynchronous Module Definition(异步模块定义)
编译成 require/exports 来执行
浏览器一般使用AMD规范,异步加载
RequireJS是一个工具库。用于客户端的模块管理。可以让客户端的代码分成一个个模块,实现异步或动态加载,提高代码的性能和可维护性。遵守AMD规范
Require.js的基本思想是,通过define方法,将代码定义为模块;通过require方法,实现代码的模块加载
基本语法
定义暴露模块:
//定义没有依赖的模块
define(function(){
return 模块
})
//定义有依赖的模块
define(['module1', 'module2'], function(m1, m2){
return 模块
})
2
3
4
5
6
7
8
引入使用模块:
require(['module1', 'module2'], function(m1, m2){
使用m1/m2
})
2
3
- 采用异步加载的方式来加载模块,模块的加载不影响后面语句执行,所有依赖这个模块的语句都定义在一个回调函数里,等到加载完成后再执行回调;也可以根据需要动态加载模块
- AMD模块定义的方法清晰,不会污染全局环境,可清楚地显示依赖关系
# CMD
Common Module Definition(通用模块定义)
CMD规范用于浏览器端,异步加载,使用模块时才会加载执行
整合了CommonJS和AMD规范的特点
Sea.js中,所有JS模块都遵循CMD模块定义规范
基本语法
定义暴露模块:
//定义没有依赖的模块
define(function(require, exports, module){
exports.xxx = value
module.exports = value
})
//定义有依赖的模块
define(function(require, exports, module){
//引入依赖模块(同步)
var module2 = require('./module2')
//引入依赖模块(异步)
require.async('./module3', function (m3) {
})
//暴露模块
exports.xxx = value
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
引入使用模块:
define(function (require) {
var m1 = require('./module1')
var m4 = require('./module4')
m1.show()
m4.show()
})
2
3
4
5
6
# ES6
import 和 export 的形式导入导出模块。这种方案和上面三种方案都不同
尽量静态化,保证在编译时就能确定模块的依赖关系和输入输出的变量
异步导入,用于浏览器,需要下载文件,同步导入对渲染有很大影响
实时绑定,导入导出的值都指向同一个内存地址,导入值跟随导出值变化
编译成 require/exports 来执行
- 使用
export命令定义了模块的对外接口以后,其他 JS 文件可以通过import命令加载这个模块
一个模块是一个独立的文件,该文件内部的所有变量,外部无法获取。如果希望外部读取模块内部的某个变量,必须使用export关键字输出该变量
编译阶段,import会提升到整个模块的头部,首先执行
如果不需要知道变量名或函数就完成加载,用export default命令,为模块指定默认输出
export default指定模块的默认输出。一个模块只能有一个默认输出,export default命令只能使用一次。所以,import命令后面才不用加大括号,因为只可能唯一对应export default命令
# 基本语法
export
1.如果不想对外暴露内部变量真实名称,可使用as关键字设置别名,同一个属性可设置多个别名
外部引入时,可通过name2这个变量访问king值
const name='king';
export {name as name2};
2
2.同一文件中,同一变量名只能export一次,否则抛出异常
const name='king';
const _name='king';
export {name as _name};
export {_name};//抛出异常,_name作为对外输出的变量,只能export一次
2
3
4
import
import {标识符列表} from '模块'
{}不是对象,里面知识存放导入的标识符
2
1.import和export的变量名相同
2.相同变量名的值只能import一次
3.import命令具有提升的效果
//export.js
export const name='king';
//import.js
console.log(name);//king
import {name} from './export.js'
2
3
4
5
6
本质:import在编译期间运行,执行console语句之前就已经执行了import语句。因此能够打印出 name的值,即,King
4.多次import时,只会加载一次
以下代码,我们import了两次export.js文件,最终只输出一次“start”,可推断出import导入的模块是单例模式
//export.js
console.log('start');
export const name='king';
export const age=19;
//import.js
import {name} from './export.js
import {age} from './export.js''
2
3
4
5
6
7
8
5.允许在需要的时候动态加载模块,而不是一开始就加载所有模块,提高性能
这个新功能允许我们将import()作为函数调用,将其作为参数传递给模块的路径。 它返回 promise,用一个模块对象实现,可以访问该对象的导出
import('/modules/myModule.mjs')
.then((module) => {
// Do something with the module.
});
2
3
4
# 循环引入
模块地图和模块记录
模块记录类似模块的身份证,记录关键信息——模块导出值的内存地址,加载状态,其他模块导入时,做一个"连接"——根据模块记录,把导入的变量指向同一块内存,实现动态绑定
模块地图,标记进入过的模块为"获取中",所以循环引用时不会再次进入,地图中每个节点是一个模块记录,上面有导出变量的内存地址
// index.mjs
import * as a from './a.mjs'
console.log('入口模块引用a模块:',a)
// a.mjs
let a = "原始值-a模块内变量"
export { a }
import * as b from "./b.mjs"
console.log("a模块引用b模块:", b)
a = "修改值-a模块内变量"
// b.mjs
let b = "原始值-b模块内变量"
export { b }
import * as a from "./a.mjs"
console.log("b模块引用a模块:", a)
b = "修改值-b模块内变量"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17

# 对比总结
CommonJS输出值的浅拷贝(加载一个对象,及module.exports属性,该对象只有在脚本运行时生成),同步的,运行时加载
ES6 编译时加载,且是异步的,输出值的引用
- CommonJS规范用于服务端编程,同步加载,不适合浏览器,同步意味阻塞,而浏览器资源异步加载,因此诞生AMD 和 CMD
- AMD规范在浏览器环境中异步加载,可以并行加载。开发成本高,代码阅读困难,模块定义语义不顺畅
- CMD和AMD相似,依赖就近,延迟执行,易在nodejs运行。但是,依赖SPM打包,模块加载逻辑偏重
- ES6实现模块功能且实现简单,完全可以取代CommonJS和AMD规范,成为浏览器和服务器通用模块解决方案的宠儿
# 为什么模块循环依赖不会死循环?CommonJS和ES Module的处理不同?
CommonJS和ES Module都对循环引入做了处理,不会进入死循环,但方式不同:
- CommonJS借助模块缓存,遇到require函数会先检查是否有缓存,已经有的则不会进入执行,在模块缓存中还记录着导出的变量的拷贝值
- ES Module借助模块地图,已经进入过的模块标注为获取中,遇到import语句会去检查这个地图,已经标注为获取中的则不会进入,地图中的每一个节点是一个模块记录,上面有导出变量的内存地址,导入时会做一个连接——指向同一块内存
CommonJS的export和module.export指向同一块内存,由于最后导出的是module.export,不能直接给export赋值,会导致指向丢失
查找模块时,核心模块和文件模块的查找都比较简单,对于react/vue这种第三方模块,会从当前目录下的node_module文件下开始,递归往上找,找到该包后,根据package.json的main字段找到入口文件
# 💛 DOM
# 操作
(1)创建新节点
const fragment = document.createDocumentFragment();
const divEl = document.createElement("div");
const textEl = document.createTextNode("content");
2
3
(2)添加、移除、替换、插入
appendChild(node)
removeChild(node)
replaceChild(new,old)
insertBefore(new,old)
2
3
4
(3)查找
document.getElementById('id属性值');返回拥有指定id的对象的引用
document.getElementsByClassName('class属性值');返回拥有指定class的对象集合
document.getElementsByTagName('标签名');返回拥有指定标签名的对象集合
document.getElementsByName('name属性值'); 返回拥有指定名称的对象结合
document/element.querySelector('CSS选择器'); 仅返回第一个匹配的元素
document/element.querySelectorAll('CSS选择器'); 返回所有匹配的元素
document.documentElement; 获取页面中的HTML标签
document.body; 获取页面中的BODY标签
document.all['']; 获取页面中的所有元素节点的对象集合型
document.querySelector('.element')
document.querySelector('#element')
document.querySelector('div')
document.querySelector('[name="username"]')
document.querySelector('div + p > span')
const notLive = document.querySelectorAll("p");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
HTMLCollection 是动态集合, DOM 树变化时, HTMLCollection 随之改变。 NodeList 是静态集合, NodeList 不受 DOM 树变化影响
(4)属性操作
getAttribute(key);
setAttribute(key,value);
hasAttribute(key);
removeAttribute(key);
const dataAttribute = document.createAttribute('custom');
consle.log(dataAttribute);
2
3
4
5
6
# DOM事件
onerror()
onconfirm()应该是在表单提交前触发,确认
# location
包含有关当前URL的信息
是window的一部分,通过window.location访问
属性
| 属性 | 描述 |
|---|---|
| hash (opens new window) | 从井号 (#) 开始的 URL(锚) |
| host (opens new window) | 主机名和当前 URL 的端口号 |
| hostname (opens new window) | 当前 URL 的主机名 |
| href (opens new window) | 完整的 URL |
| pathname (opens new window) | 当前 URL 的路径部分 |
| port (opens new window) | 当前 URL 的端口号 |
| protocol (opens new window) | 当前 URL 的协议 |
| search (opens new window) | 从问号 (?) 开始的 URL(查询部分) |
| origin | URL 来源的 Unicode 序列化,包括协议 |
方法
| 属性 | 描述 |
|---|---|
| assign() (opens new window) | 加载新的文档 |
| reload() (opens new window) | 重新加载当前文档 |
| replace() (opens new window) | 用新的文档替换当前文档 |
document、window
window代表浏览器窗口,是JS在浏览器中的全局对象
document代表文档对象,window的一个属性
Element、Node
Node是基类,Element、Text都继承于它
Element、Text分别叫做ELEMENT_NODE,TEXT_NODE
html上的元素,即element,是类型为ELEMENT_NODE的Node
Node表示DOM树的结构,html中节间可以插入文本,这个插入的空隙就是TEXT_NODE
可使用childNodes得到NodeList,如何获取ElementList?
getElementByXXX返回ElementList,它的真名是 ElementCollection
就像NodeList是Node的集合一样,ElementCollection也是Element的集合
他们都不是真正的数组
# HTMLCollection、NodeList
# HTMLCollection
类数组对象, 包含元素(元素顺序为文档流中的接口)的通用集合,提供从该集合中选择元素的属性和方法
live——即时更新
因此,最好创建副本后再迭代 以 add 、delete 或是 move节点
getElementByTagName()返回HTMLCollection对象
HTMLCollection有namedITem方法,其他和NodeList保持一致
HTMLCollection只包含元素节点(ElementNode)
属性和方法
item(index)—— 返回HTMLCollection指定索引元素,不存在则返回nulllength—— 返回HTMLCollection元素的数量
# NodeList
节点的集合
不是数组,是类数组对象
可以使用forEach迭代,使用Array.from()转换为数组
一些情况下,NodeList动态变化,如果文档节点树变化,NodeList会随之而变,Node.childNodes是实时的
其他情况,NodeLIst是静态集合,document.querySelectorAll返回静态NodeList
可使用for循环 或 for-of 遍历,不要使用 for-in 遍历NodeList,因为NodeList对象的length和item属性会被遍历出来,可能导致错误,且for-in无法保证属性顺序
NodeList可包含任何节点类型
通过以下方法,可 获取 NodeList
①**一些旧版本浏览器 getElementsClassName() 返回 NodeList ,而不是 HTMLCollection **
②**所有浏览器的Node.childNodes 返回 NodeList **
③大部分浏览器 document.querySelectorAll() 返回NodeList
NodeList 属性和方法
item()—— 返回元素索引length()—— 返回NodeList节点数量NodeList.forEach()—— 遍历NodeList所有成员。接收回调函数作为参数,遍历一回就要执行这个回调,与数组forEach完全一致NodeList.keys()/values()/entries()—— 都返回ES6遍历器对象,通过for…of…循环遍历,获取每一个成员
# 总结
| HTMLCollection | NodeList | |
|---|---|---|
| 集合 | 元素集合 | 节点集合 |
| 静态和动态 | 动态集合。DOM 树变化,随之变化,其节点的增删敏感 | 静态集合,不受 DOM 树元素变化影响;相当于是 DOM 树、节点数量和类型的快照,对节点增删时,NodeList 感觉不到。但是对节点内部内容修改,可以感觉到,修改 innerHTML |
| 节点 | 不包含属性节点和文本节点 | 只有 NodeList 对象有包含属性节点和文本节点 |
| 元素获取方式 | 元素可以通过 name,id / index 索引获取 | 只能通过 index 索引获取 |
| 伪数组 | HTMLCollection 和 NodeList 都是类数组。所以使用数组方法,pop(),push()/join() | 与 HTMLCollection 一样 |
# 获取DOM大小
getBoundingClientRect()
获取 元素 大小及 相对于视窗的位置,返回 包含left, top, right, bottom, x, y, width, 和 height 参数对象,除 width 和 height 以外 属性 相对于视图窗口的左上角 计算
# 💛 Ajax、Fetch、Axios

# Ajax
Ajax(Asynchronous JavaScript and XML,异步JS与XML技术),实现网页异步更新,不重新加载网页对网页部分进行更新
不是一种新技术,而是2005年被提出的新术语
XMLHttpRequest的API实现
//创建 XMLHttpRequest 对象
const ajax = new XMLHttpRequest();
//规定请求类型、URL 以及是否异步处理请求,open() 方法与服务端建立连接
ajax.open('GET',url,true);
//为对象添加一些信息和监听函数
ajax.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
//发送请求
ajax.send(null);
//监听服务端的通信状态
ajax.onreadystatechange = function () {
if (ajax.readyState == 4 && (ajax.status == 200 || ajax.status == 304)) {
}
};
2
3
4
5
6
7
8
9
10
11
12
13
XMLHttpRequest对象有5个状态,状态变化触发onreadystatechange事件,可设置监听函数处理请求结果
当对象的 readystate 变为 4时,代表服务器返回的数据接收完毕, 可对 请求状态进行判断
# Promise封装Ajax请求
function getJSON(url){
let promise=new Promise((resolve,reject)=>{
let xhr=new XMLHttpRequest();
xhr.open('GET',url,true);
xhr.onreadystatechange=()=>{
if(this.readystate!==4) return;
if(this.status===200){
resolve(this.response);
}else{
reject(new Error(this.statusText));
}
};
xhr.onerror=()=>{
reject(new Error(this.statusText));
};
xhr.responseType='json';
xhr.setRequestHeader('Accept','application/json');
xhr.send(null);
});
return promise;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
特点:
- 局部刷新页面
- 基于原生XHR开发,而XHR本身架构不清晰
- 对基于异步的事件不友好
# Ajax底层实现?
# Fetch
获取资源的接口,**替换笨重繁琐XMLHttpRequest。**有Request 、Response 、Headers 概念,与后端语言请求资源更接近
会创建微任务,因为返回 Promise
- 使用 Promise,支持async/await
- 模块化设计,Response Request 和 Header对象
- 不携带cookie,需要手动配置
fetch是底层API,真实存在
# fetch能监听网络请求超时吗
XMLHttpRequest可设置请求超时时间,Fetch不能监听网络请求超时
# Axios
Axios ——基于 promise 的HTTP网络请求库,用于浏览器和Nodejs
体积小,提供简单易用的库,接口易于扩展
本质是对原生XMLHttpRequest的封装,只不过它是Promise的实现版本
特点:
- 从浏览器中创建 XMLHttpRequests
- 支持浏览器和nodejs环境
- 支持 Promise API
- 转换请求数据和响应数据
- 取消请求
- 客户端支持防御 XSRF
axios({
url:'xxx', // 设置请求的地址
method:"GET", // 设置请求方法
params:{ // get请求使用params进行参数凭借,如果是post请求用data
type: '',
page: 1
}
}).then(res => {
// res为后端返回的数据
console.log(res);
})
2
3
4
5
6
7
8
9
10
11
# 设置接口请求前缀
利用node环境变量判断,区分开发、测试、生产环境
if (process.env.NODE_ENV === 'development') {
axios.defaults.baseURL = 'http://dev.xxx.com'
} else if (process.env.NODE_ENV === 'production') {
axios.defaults.baseURL = 'http://prod.xxx.com'
}
2
3
4
5
本地调试时,在config.js中配置proxy实现代理转发
# 设置请求头和超时时间
const service = axios.create({
...
timeout: 30000, // 请求 30s 超时
headers: {
get: {
'Content-Type': 'application/x-www-form-urlencoded;charset=utf-8'
// 在开发中,一般还需要单点登录或者其他功能的通用请求头,可以一并配置进来
},
post: {
'Content-Type': 'application/json;charset=utf-8'
// 在开发中,一般还需要单点登录或者其他功能的通用请求头,可以一并配置进来
}
},
})
2
3
4
5
6
7
8
9
10
11
12
13
14
# 封装请求方法
// get 请求
export function httpGet({
url,
params = {}
}) {
return new Promise((resolve, reject) => {
axios.get(url, {
params
}).then((res) => {
resolve(res.data)
}).catch(err => {
reject(err)
})
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
请求拦截器
在每个请求里加上token,统一处理维护方便
响应拦截器
在接收到响应后先做一层判断,比如状态码判断登录状态、授权
# axios和fetch
就个人体验, Axios优于Fetch
Fetch的优势仅在于浏览器原生支持
不像Axios需引入包,需要即时测试接口直接在Chrome浏览器中使用Fetch请求,尤其是编写爬虫/脚本
Axios是对XMLHttpRequest的封装,Fetch是新的获取资源的接口方式,不是对XMLHttpRequest的封装
最大的不同点在于Fetch浏览器原生支持,Axios需要引入Axios库
Axios兼容IE,Fetch在IE和一些老版浏览器没有支持,但有库可让老版浏览器支持Fetch,很多网站为了减少成本而选择不再兼容IE浏览器
在旧的浏览器上可能还需要使用promise兼容库
Axios可设置 超时,直接设置timeout属性,fetch不行
Axios 自动对数据转化,Fetch 需要 手动转化
Axios 提供拦截器,统一对请求或响应处理,可为请求附加token、增加时间戳防止请求缓存、拦截响应,状态码不符合预期直接将响应消息通过弹框的形式展示在界面,密码错误、服务器内部错误、表单验证不通过
Fetch没有拦截器功能,重写全局Fetch方法就可办到
# CDN
Content Delivery Network,内容分发网络
我们访问一个页面的时候,会请求很多资源,包括各种图片、声音、影片、文字等信息。这和我们要购买多种货物一样
网站可以预先把内容分发至全国各地的加速节点。用户可以就近获取内容,避免网络拥堵、地域、运营商等因素带来的访问延迟问题
"内容分发网络"像前面提到的"全国仓配网络",解决因分布、带宽、服务器性能带来的访问延迟问题,适用于站点加速、点播、直播等场景
用户可就近取得所需内容,解决 Internet网络拥挤的状况
CDN本质 是一大堆遍布在全球各个 角落 的缓存服务器。通过与DNS的配合,找到最靠近用户的一台CDN缓存服务器,将数据快速 分发 给用户
减少对整体骨干网的流量负担,提高用户体验
DNS解析之后,浏览器向服务器请求内容后发生
长途骨干网的传输最耗时,需经过网站服务器所在的机房、骨干网、用户所在城局域网、用户所在接入网等,物理传输距离遥远
1亿人同时请求12306上一张一模一样的图片,对国家的互联网基础设施是一个灾难
CDN 提前把数据存在离用户最近的数据节点,避免长途跋涉经过长途骨干网,最终 减少骨干网负担、提高访问速度

请求图片数据,先去CDN缓存服务器获取,若获取到数据直接返回,否则才 经过 长途骨干网,最终达到 网站服务器 获取数据
CDN其实还缩短了请求数据的距离
用户分布全国各地,一般会在 离用户在 较近的地方设置 CDN 缓存服务器,酱紫各个 地区的用户能直接请求对应的CDN服务器,不需要来回跑 大半个 中国!
# 过程
- 发起请求,本地 DNS 解析,将域名解析权交给域名 CNAME 指向的 CDN 专用 DNS 服务器
- CDN 的 DNS 服务器将 CDN 的全局负载均衡设备 IP 地址返回浏览器
- 浏览器向 CDN 全局负载均衡设备发起 URL 请求
- CDN 全局负载均衡设备根据用户 IP ,以及URL,选择一台用户所属区域的区域负载均衡设备,向其发请求
- 区域负载均衡设备为用户选最合适的 CDN 缓存服务器(考虑的依据包括:服务器负载情况,距离用户的距离等),返回给全局负载均衡设备
- 全局负载均衡设备将选中的 CDN 缓存服务器 IP 返回给用户
- 根据用户IP,判断最近边缘节点
- 根据用户请求URL中内容,判断有用户所需内容的边缘节点
- 查询边缘节点负载情况,判断有服务能力的边缘节点
- 全局负载均衡设备将服务器IP返回给用户
- 用户向 CDN 缓存服务器发起请求,缓存服务器响应用户请求,最终将内容返回
# 组成
(CDN)由多个节点组成。一般,CDN网络主要由中心节点、边缘节点两部分构成
中心节点
中心节点包括CDN网管中心和全局负载均衡DNS重定向解析系统,负责整个CDN网络的分发及管理
边缘节点
CDN边缘节点主要指异地分发节点,有负载均衡设备、高速缓存服务器两部分
负载均衡设备负责每个节点中各个Cache的负载均衡,保证节点 工作效率;同时负责收集节点与周围环境的信息,保持与全局负载均衡DNS的通信,实现整个系统的负载均衡
高速缓存服务器(Cache)负责存储客户网站信息,像一个靠近用户的网站服务器一样响应本地用户的请求
通过全局负载均衡DNS的控制,用户的请求被透明 指向离他最近的节点,节点中Cache服务器像网站的原始服务器一样,响应终端用户的请求
中心节点像仓配网络中负责货物调配的总仓,边缘节点就是负责存储货物的各个城市的本地仓库
# 前端路由
# location.replace/ href
href会写入 浏览器 window.history 对象中
replace不会,replace将当前URL替换,而非跳转,不会保存记录
location.href="http://www.baidu.com"
location.replace("http://www.baidu.com")
2
# 前端路由
- 路由是根据不同的 url 地址展示不同的内容或页面
- 前端路由就是把不同路由对应不同的内容或页面的任务交给前端来做,之前是通过服务端根据 url 的不同返回不同的页面实现的。
前端路由实现原理很简略,实质上就是检测 URL 的变动,截获 URL 地址,通过解析、匹配路由规定实现 UI 更新
# SPA路由跳转实现
不是真正的页面跳转,另一个角度来说,其实就是组件的挂载和卸载罢了。通过监听知道某一个组件的状态并对其进行渲染
单页面应用中的路由分为两种: hash模式和history模式
# hash模式
监听浏览器地址hash值变化,执行事件
hash会在浏览器URL后增加 # 号
一个完整的的 URL 包含:协定、域名、端口、虚拟目录、文件名、参数、锚
比如 https://www.google.com/#abc (opens new window)中的hash值为abc 特点:hash的变化不会刷新页面,也不会发送给服务器
但hash的变化会被浏览器记录下来,用来指导浏览器中的前进和后退
使用window.location.hash变化触发窗口的onhashchange事件,监听hash变化
触发路由时视图容器更新——多数前端框架哈希路由的实现原理
# 触发hashchange
- URL变化(包括浏览器的前进、后退)修改window.location.hash的值
- 浏览器发送http://www.baidu.com/ 至服务器,请求完毕后设置散列值为#/home,触发onhashchange
- 只修改hash部分,不发请求,但触发onhashchange
- a标签可设置页面hash,浏览器自动设置hash属性,触发onhashchange
window.location.hash='abc';
let {hash}=window.location
window.addEventListener('hashchange',function(){
//监听hash变化
})
2
3
4
5
# 特点
不需要后端配合
兼容性好
路径在#后面,不好看
# history模式
H5新特性,允许我直接修改前端路由,更新URL但不重新发请求,history可自定义地址
window.history属性指向 History 对象,它表示当前窗口的浏览历史,保存了当前窗口访问过的所有页面网址
由于安全原因,浏览器不允许脚本读取这些地址,但是允许在地址之间导航
// 后退到前一个网址
history.back()
// 等同于
history.go(-1)
2
3
4
5
浏览器工具栏的“前进”和“后退”按钮,其实就是对 History 对象进行操作
History 对象主要有两个属性。
History.length:当前窗口访问过的网址数量(包括当前网页)History.state:History 堆栈最上层的状态值(详见下文)
// 当前窗口访问过多少个网页
window.history.length // 1
// History 对象的当前状态
// 通常是 undefined,即未设置
window.history.state // undefined
2
3
4
5
6
# history.back()、history.forward()、history.go()
用于在历史之中移动
History.back():移动到上一个网址,等于点击浏览器后退键。对于第一个访问的网址,该方法无效History.forward():移动到下一个网址,等于点击浏览器前进键。对于最后一个访问的网址,该方法无效果History.go():跳转到指定记录页,go(1)相当于forward(),go(-1)相当于back()。如果参数超过实际存在的网址范围,该方法无效;如果不指定参数,默认0,相当于刷新当前页面
# history.pushState()
在历史中添加一条记录,不会导致页面刷新
window.history.pushState(state, title, url)
state:对象,触发popstate事件将该对象传递到新页面。不需要可以填nulltitle:新页面的标题。但是,现在所有浏览器都忽视这个参数,所以这里可以填空字符串url:新的网址,必须与当前页面处在同一个域。浏览器的地址栏将显示这个网址
假定当前网址是example.com/1.html,使用pushState()方法在浏览记录(History 对象)中添加一个新记录
var stateObj = { foo: 'bar' };
history.pushState(stateObj, 'page 2', '2.html');
2
添加新记录后,浏览器地址栏立刻显示example.com/2.html,但并不会跳转到2.html,甚至也不会检查2.html是否存在,它只是成为浏览历史中的最新记录。这时,在地址栏输入一个新的地址(比如访问google.com),然后点击了倒退按钮,页面的 URL 将显示2.html;再点击一次倒退按钮,URL 将显示1.html
pushState()不会触发页面刷新,只是导致 History 对象发生变化,地址栏会有反应
使用该方法之后,可以用History.state读出状态对象
var stateObj = { foo: 'bar' };
history.pushState(stateObj, 'page 2', '2.html');
history.state // {foo: "bar"}
2
3
如果pushState的 URL 参数设置了一个新的锚点值(即hash),不会触发hashchange事件。反过来,如果 URL 的锚点值变了,会在 History 对象创建一条浏览记录
如果pushState()方法设置了一个跨域网址,报错
// 报错
// 当前网址为 http://example.com
history.pushState(null, '', 'https://twitter.com/hello');
2
3
pushState想要插入一个跨域的网址,导致报错。防止恶意代码让用户以为他们是在另一个网站上,因为这个方法不会导致页面跳转
# history.replaceState()
修改 History 当前记录,其他与pushState()一模一样
假定当前网页是example.com/example.html
history.pushState({page: 1}, 'title 1', '?page=1')
// URL 显示为 http://example.com/example.html?page=1
history.pushState({page: 2}, 'title 2', '?page=2');
// URL 显示为 http://example.com/example.html?page=2
history.replaceState({page: 3}, 'title 3', '?page=3');
// URL 显示为 http://example.com/example.html?page=3
history.back()
// URL 显示为 http://example.com/example.html?page=1
history.back()
// URL 显示为 http://example.com/example.html
history.go(2)
// URL 显示为 http://example.com/example.html?page=3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# popstate事件
当同一个文档的浏览历史变化触发popstate
注意
调用
pushState()/replaceState(),不会触发该事件只有点击浏览器倒退/前进,或调用
History.back()、History.forward()、History.go()才会触发只针对同一个文档,如果浏览历史切换,导致加载不同文档,不会触发
popstate指定回调函数
window.onpopstate = function (event) {
console.log('location: ' + document.location);
console.log('state: ' + JSON.stringify(event.state));
};
// 或者
window.addEventListener('popstate', function(event) {
console.log('location: ' + document.location);
console.log('state: ' + JSON.stringify(event.state));
});
2
3
4
5
6
7
8
9
10
回调函数参数event事件对象,state指向当前状态对象,这个state也可以通过history对象读取
var currentState = history.state;
页面第一次加载不会触发popstate事件
# 特点
路径正规
兼容性不比hash,需服务端支持
对于一个应用而言,url 的改变(不包括 hash 值得改变)只能由下面三种情况引起:
- 点击浏览器的前进或后退按钮 => 可以监听popstate事件
- 点击 a 标签
- 在 JS 代码中触发 history.pushState()、history.replaceState()
history router的实现思路是:监听页面中和路由有关的a标签点击事件,阻止默认的跳转行为,然后调用history.pushState()方法,让浏览器记住路由,手动更新相应视图。为了监听用户手点击浏览器的前进后退按钮,还需要监听popstate事件,动态的修改相应视图
# ✅ 页面生命周期
包含三个重要事件:
DOMContentLoaded—— 已完全加载 HTML,并构建了 DOM 树,像<img>和样式表之类的外部资源可能尚未加载完成load—— 浏览器不仅加载完成了 HTML,还加载完了所有外部资源:图片,样式等beforeunload/unload—— 用户正在离开页面时
每个事件都有用:
DOMContentLoaded事件 —— DOM 已经就绪,因此处理程序可以查找 DOM 节点,并初始化接口load事件 —— 外部资源已加载完成,样式已被应用,图片大小也已知beforeunload事件 —— 用户正在离开:我们可以检查用户是否保存了更改,并询问他是否真的要离开unload事件 —— 用户几乎已经离开,但是我们仍然可以启动一些操作,例如发送统计数据
# DOMContentLoaded
遇到script标签,会在DOM构建之前运行它,因为脚本可能修改DOM,所以DOMContentLoaded必须等待脚本执行结束
外部样式表不影响DOM,因为DOMContenLoaded不会等待他们
但是,如果在样式后面有一个脚本,该脚本必须等待样式表加载完成:
<link type="text/css" rel="stylesheet" href="style.css">
<script>
// 在样式表加载完成之前,脚本都不会执行
alert(getComputedStyle(document.body).marginTop);
</script>
2
3
4
5
原因是,脚本可能想要获取元素的坐标或其他与样式相关的属性,如上例所示。必须等待样式加载完成
当 DOMContentLoaded 等待脚本时,它也在等待脚本前面的样式
# 不会阻塞 DOMContentLoaded 的脚本
- 具有
async特性的脚本不会阻塞DOMContentLoaded - 使用
document.createElement('script')动态生成并添加到网页的脚本也不会阻塞DOMContentLoaded
# onload
当整个页面,包括样式、图片和其他资源被加载完成时,触发 window 对象上的 load 事件
# onunload
当访问者离开页面时,window 对象上的 unload 事件就会被触发。我们可以做一些不涉及延迟的操作,例如关闭相关的弹出窗口
和onpagehide事件相互替换的是
onunload
用户离开网页执行onpagehide,但onunload无法缓存页面
# onbeforeunload
如果访问者触发了离开页面的导航(navigation)或试图关闭窗口,beforeunload 处理程序将进行更多确认
如果我们要取消事件,浏览器会询问用户是否确定
# readyState
如果我们在文档加载完成之后设置 DOMContentLoaded 事件处理程序,会发生什么?
它永远不会运行
在某些情况下,我们不确定文档是否已经准备就绪。我们希望我们的函数在 DOM 加载完成时执行,无论现在还是以后
document.readyState 属性可以为我们提供当前加载状态的信息
它有 3 个可能值:
loading—— 文档正在被加载interactive—— 文档被全部读取complete—— 文档被全部读取,所有资源(例如图片等)都已加载完成
所以,我们可以检查 document.readyState 并设置一个处理程序,或在代码准备就绪时立即执行它
# 🌰CSS、JS位置问题
渲染引擎判断脚本时,HTML解析器暂停DOM解析,JS引擎介入,因为JS脚本可能修改当前已生成DOM
如果JS脚本通过文件加载,需先下载JS代码,JS文件下载会阻塞DOM解析,下载耗时,受到 网络、文件大小 因素影响
如果脚本内嵌,则 直接执行,阻塞DOM构建
如果JS脚本修改 DOM内容,执行脚本后,div被修改,HTML解析器恢复解析过程
如果JS代码出现修改CSS的语句,操纵 CSSDOM,执行JS前,先解析JS语句之上所有CSS样式,如果引用外部CSS文件,执行JS前,需等待外部CSS文件下载完成,解析生成CSSOM后,才执行 JS 脚本
解析JS前,不知道JS是否操纵CSSOM,所以渲染引擎遇到JS脚本时,不管该脚本是否操纵了CSSOM,都会执行CSS文件下载,解析,再执行JS脚本,构建DOM,生成布局树
所以JS脚本依赖样式表
JS文件下载会阻塞DOM解析
样式文件会阻塞JS执行
JS阻塞了啥
JS文件放在head中,构建DOM树遇到JS文件加载会阻塞,直到JS加载执行完页面都是空白!
script标签最好放在body,浏览器为了用户体验 渲染引擎尝试尽快显示,不会等到所有DOM解析完成 才布局渲染树,JS阻塞发生时,将已经构建的DOM元素渲染,减少白屏——这就是为啥将script标签放body标签底部的原因,不影响前面页面渲染
有了async和defer,script标签位置不再那么重要
CSS阻塞了啥
解析HTML遇到link/style标签 会计算样式,构建CSSOM
CSS不会阻塞DOM树构建,但会阻塞页面显示,因为 构建CSSOM过程中,不渲染任何内容,即便DOM解析完毕,只要CSSOM没构建好,不显示
如果link标签前有DOM元素,加载CSS阻塞时,浏览器会将前面已经构建好的DOM元素渲染到屏幕上,减少白屏时间
但是,会出现 页面闪烁!**因此将CSS标签放在head中,如果放在body标签前面,因为CSS不阻塞DOM构建,**DOM树构建完成 render树渲染,渲染树构建完成,浏览器不得不re-render,造成资源浪费,在head中,边构建边渲染,效率更高
放在head尽早加载,减少请求阻塞时间
script放head和body
head中,代表的function只加载不执行
body中,加载并执行
# 🍉 defer、async
DOMContentLoaded触发时间:HTML文档被加载解析完成
# sync 同步
# async 异步
- HTML未被解析完,async脚本已经加载完,HTML停止解析去执行脚本
- HTML解析完,async脚本才加载完,再执行脚本
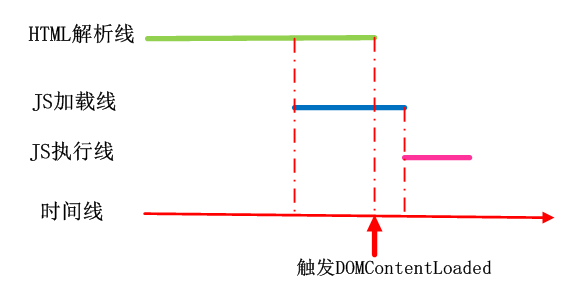
# defer 延迟
不影响HTML解析,HTML解析完才执行,阻止 DOMContentLoaded,直到脚本被加载且解析完成
- HTML未解析完,defer脚本加载完毕,defer等HTML解析完再执行
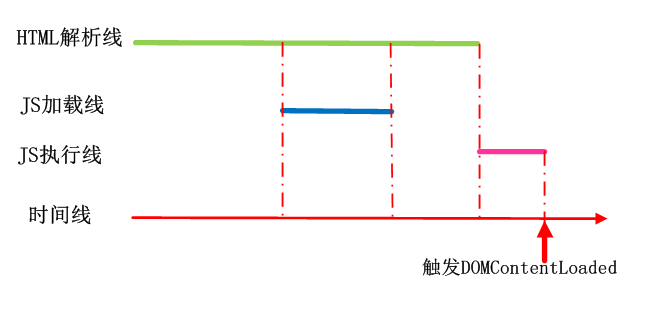
- HTML解析完,defer脚本还没加载完毕,defer脚本继续加载,加载完直接执行
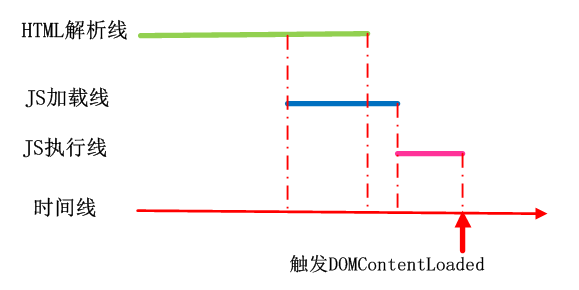
# 总结
script标签属性
脚本下载执行和文档解析同步,会阻塞文档解析,若控制不好,会造成页面卡顿
可以在script声明defer和async (仅适用外部脚本)
defer:HTML解析完成后按照脚本出现次序 顺序执行,构建DOM树和JS文件的加载 并行 执行,JS文件执行在DOM树构建完成之后
async:H5新增,下载完成立即执行,阻塞页面解析,**谁先下载好谁执行 **
async脚本和DOMContentLoaded不会彼此等待

推荐与主业务无关的JS脚本使用async,例如 监控、广告 脚本,它们都是独立的文件,没有外部依赖,无需访问DOM,使用async有效避免 非核心功能的加载影响页面解析速度
# 💚 排序
# 数组、链表
数据的物理存储结构:连续存储(数组)离散存储(链表)
区别:
对数组,查找方便,连续存储,增删改效率低;事先申请好连续的内存空间小,太大浪费内存,太小越界
对链表,动态申请内存空间,不需要提前申请好内存的大小,只需在用的时候申请就可以,根据需要动态申请或者删除内存空间,对数据增加和删除以及插入比数组灵活
应用场景:
数组:数据量固定,频繁查询,较少增删的场景
链表:数据量不固定,频繁增删,较少查询的场景
- 单向链表:线型数据结构,指针指向下一个节点,终点指向null
- 双向链表:可以往前或者往后添加节点,指针指向前一个节点和后一个节点
# 链表在JS的应用
原型链
hooks state存储
fiber架构的fiber数据结构本身是链表结构
# 选择排序
买苹果每次都选择最大的
找到数组最小的元素,将其和数组第一个元素交换位置
在剩下的元素中找到最小的元素,将其与数组第二个元素交换位置
如此往复,直到整个数组排序
function selectSort(arr) {
let len = arr.length;
let minIndex;
for (let i = 0; i < len - 1; i++) {
minIndex = i;
for (let j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
[arr[i], arr[minIndex]] = [arr[minIndex], arr[i]];
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 无论什么数据进去都是 O(n²) 的时间复杂度
- 空间复杂度O(1)
- 非稳定排序
- 原地排序
# 冒泡
第一个元素和第二个元素比较,如果第一个比第二个大,则交换
继续比较第二个和第三个元素,若第二个比第三个大,则交换……
对每一个相邻元素做同样工作,从第一对开始到最后一对结尾,一趟比较下来后,排在最后的元素是最大元素
function bubbleSort(arr) {
if (arr.length < 2) {
return arr;
}
const len = arr.length;
for (let i = 0; i < len - 1; i++) {
for (let j = 0; j < len - i - 1; j++) {
if (arr[j + 1] < arr[j]) {
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 时间复杂度O(n²)
- 空间复杂度O(1)
- 稳定排序
- 原地排序
# 优化
如果从第一队到最后一对,相邻元素间没有交换,意味着右边的元素总是≥左边元素,此时数组有序,无需再对剩下元素重复比较
function bubbleSortPerformance(arr) {
if (arr.length < 2) {
return arr;
}
const len = arr.length;
for (let i = 0; i < len - 1; i++) {
let flag = true;
for (let j = 0; j < len - i - 1; j++) {
if (arr[j + 1] < arr[j]) {
flag = false;
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
if (flag) {
break;
}
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
如何优化?
优化后时间复杂度?
与快排相比?
快排思路?
相比冒泡,快排每次交换是跳跃式。每次排序设置基准点,将≤基准点的数放到基准点左边,将大≥基准点的数放到基准点右边。这样每次交换不会像冒泡每次只在相邻数间交换,交换距离大的多。因此总比较和交换次数少,速度提高。最坏的情况仍可能是相邻两数交换
# ❤️ 插入排序
适合处理数据量少或部分有序的数据(移动少)
- 从第二个元素开始抽取
- 把它和左边第一个元素比较,若左边第一个元素比它大,则继续与左边第二个元素比较,直到遇到比它小的元素,然后插入到这个元素的右边
- 继续选取第 3 4 ...n个元素,重复步骤2,选择适当位置插入
function insertSort(arr) {
let preIndex = 0;
let curVal = 0;
for (let i = 1; i < arr.length; i++) {
preIndex = i - 1;
curVal = arr[i];
while (preIndex >= 0 && arr[preIndex] > curVal) {
//腾出位置插入
arr[preIndex + 1] = arr[preIndex];
preIndex--;
}
//插入元素
arr[preIndex + 1] = curVal;
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 时间复杂度O(n),最坏时间复杂度为O(n²)
- 空间复杂度O(1)
- 稳定排序
- 原地排序
# ❤️ 希尔排序
let arr=[16,9,49,7,1,45,23,13]
gap=4
一趟排序后 数组为
2
3
对大规模且无序数据有效率
对 数组 进行 多次 间隔的 插入排序
加速简单改进了插入排序,交换不相邻元素对数组局部排序
先让数组中任意间隔为h的元素有序,刚开始h可以为n/2,接着使h=n/4,h一直缩小,当h=1时,即,此时数组中任意间隔为1的元素有序
function shellSort2(arr) {
const len = arr.length;
let gap = Math.floor(len);
while (gap) {
for (let i = gap; i < len; i++) {
const tmp = arr[i];
let j;
for (j = i - gap; j >= 0 && tmp < arr[j]; j -= gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = tmp;
}
gap = Math.floor(gap / 2);
}
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
对各个分组插入时并不是先对一个组排序完成后再对另一个组排序,而是轮流对每个组排序
- 时间复杂度O(nlogn)
- 空间复杂度O(1)
- 非稳定排序
- 原地排序
# 💙 归并(讲过)
分治法
大的数组一分为二,分别对2个数组排序,然后将其合并一个有序数组
递归,分割数组,直到数组大小为1,然后
把2个数组大小为1的合并为一个大小为2的,再把大小为2的合并为大小为4的,直到全部小数组都合并
let arr = [2, 11, 10, 6, 12, 3, 4, 8, 9, 5, 1, 15, 13, 7, 14];
function mergeSort(arr) {
// 自上而下递归法
let len = arr.length;
if (len < 2) {
return arr;
}
let mid = Math.floor(len / 2);
let left = arr.slice(0, mid);
let right = arr.slice(mid);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
let res = [];
while (left.length && right.length) {
if (left[0] <= right[0]) {
res.push(left.shift());
} else {
res.push(right.shift());
}
}
while (left.length) {
res.push(left.shift());
}
while (right.length) {
res.push(right.shift());
}
return res;
}
console.log(mergeSort(arr));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
- 时间复杂度O(nlogn),切logn次,合并一个大的有序数组为O(n)
- 空间复杂度O(n)
- 稳定排序
- 非原地排序
# 💙 快排
分治法
选取一个元素作为中轴元素,把所有小于中轴的元素放在左边,所有≥中轴的元素放在右边,此时,中轴所处位置有序
从中轴开始将大树组切割为2个小数组,递归让中轴左边数组和右边数组执行同样操作,直到数组大小为1
function quickSort1(arr) {
if (arr.length <= 1) {
return arr;
}
let pivotIndex = Math.floor(arr.length / 2);
//返回删除的元素
let tmp=arr.splice(pivotIndex, 1);
let pivot = tmp[0];
let left = [];
let right = [];
for (let i = 0; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return quickSort1(left).concat([pivot], quickSort1(right));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 时间复杂度O(nlogn)
- 空间复杂度O(logn)
- 非稳定排序
- 原地排序
不像归并,还需要辅助数组
不像归并,需要把2部分有序子数组汇总到临时数组,还要copy回原数组
# 堆排序
堆顶元素是最值,将堆顶元素和最后一个元素交换,交换后破坏堆的特性,再把剩下元素再次构成一个大顶堆,把堆顶元素和最后第二个元素交换
往复……


删除包括3个步骤
- 交换堆顶与堆最后一个元素
- 堆大小-1
- 调整堆
# 计数排序
适用于最大值和最小值差值不大的排序
数组元素作为数组下表,临时数组统计该元素出现次数,最后汇总
function cntSort(arr) {
const maxVal = Math.max.apply(null, arr);
//元素出现的次数
const count = Array(maxVal + 1).fill(0);
arr.forEach(item => {
count[item]++;
})
let ans = [];
for (let i = 0; i < count.length; i++) {
while (count[i]--) {
ans.push(i);
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 时间复杂度O()
- 空间复杂度O(ans.length)
- 稳定排序
- 非原地排序
# 优化
偏移量,min=1000,max=1005,临时数组大小为(max-min+1)即可
# 桶排序
计数排序不适用时,可以使用桶排序
把最大值和最小值间的数瓜分,例如分成10个区间,对应10个桶,把元素放到对应区间的桶,在对每个桶中数进行排序,合并汇总
# 基数排序
先以个位数大小对数据排序,接着以十位数大小排序,接着是百位……
以某位数排序时,用 桶 排序
将相同数值元素放进同一个桶,再把桶里的数按照0-9的顺序取出来,一趟下来,按照某位数的排序就完成了
不建议以最高位排序,致命问题——对各部分 单独排序,每一部分类似于原问题的子问题,采用递归处理,每个小部分 排序中,需要10个桶将它们排序 ,导致空间花费大
# 总结
# others
# UTF-8、UTF-16、Unicode
ASCII 可以表示的编码有限,想表示其他语言的编码,需要使用 Unicode,Unicode可以说是 ASCII的超集
Unicode是字符集,为每种语言的每个字符设定 **统一且唯一 的二进制编码 **
Unicode的编码方式有很多,常见的是 UTF-8、UTF-16
UTF-8判断每个字节中的开头标志信息,如果某个字节在传送过程出错,会导致后面的字节解析出错;UTF-16不会判断开头标志,即使错只会错一个字符,容错能力较强
字符内容 英文占大多数,UTF-8比UTF-16更节省空间;如果中文占多数,UTF-16占优势
# JS二进制
谈谈JS二进制:File、Blob、FileReader、ArrayBuffer、Base64 (opens new window)
JS提供API处理文件或原始文件数据
File、Blob、FileReader、ArrayBuffer、base64
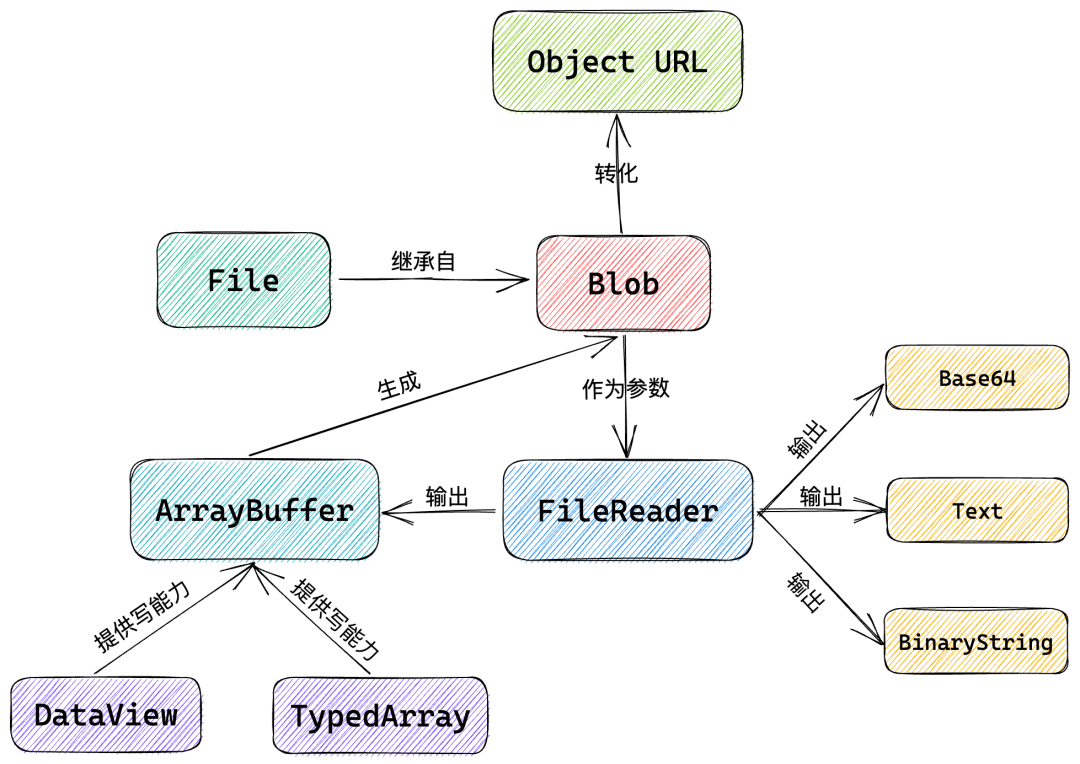
Blob及binary large object,二进制大对象,表示原始类似文件的数据
blob对象是包含只读原始数组的类文件对象,就是一个不可修改的二进制文件
# base64
把不可见字符转换为可见字符
1、字符三三分组,不够0补齐
为啥是三三分组?
因为ASCII码每个字符时8位二进制,3*8=24,正好可以被第三步拆分为4个6位二进制
2、把字符转换为二进制ASCII编码,再转换为二进制
3、二进制,六位分隔开
4、6位二进制能代表0-63
补位产生的0,使用=表示
abcd->YWJjZA==
图片base64、URL
前端传给后端的是base64编码的字符串,后端将解码的图片存起来
后端返回图片数据流,前端解析?
将图片转换blob,通过 blob 创建 URL
# 位运算
| 运算符 | 描述 | 运算规则 |
|---|---|---|
& | 与 | 两个位都为1时,结果才为1 |
| | 或 | 两个位都为0时,结果才为0 |
^ | 异或 | 两个位相同为0,相异为1 |
~ | 取反 | 0变1,1变0 |
<< | 左移 | 各二进制位全部左移若干位,高位丢弃,低位补0 |
>> | 右移 | 各二进制位全部右移若干位,正数左补0,负数左补1,右边丢弃 |
&
判断奇偶,最末位是0就是偶数,为1就是奇数
if ((i & 1) == 0)
//等价
if (i % 2 == 0 )
2
3
原码 补码 反码
符号位和数值位,符号位 0 表示 正,1 表示 负
原码
数的 二进制
反码
- 正数的反码和原码相等
- 负数的反码为 除符号位,按位取反
-10
原码 1000 1010
反码 1111 0101
2
3
补码
- 正数的补码 与 原码 相同
- 负数的补码 是原码 除符号位外的所有位 取反,再加1(即 反码+1)
-10
原码 1000 1010
反码 1111 0101
补码 1111 0110
2
3
4
# 点击事件延迟
移动端点击有 300ms 的延迟,因为移动端有双击缩放操作,浏览器在 click 之后要等待 300ms(JS捕获click事件的回调处理),看用户有没有下一次点击,判断这次操作是不是双击
有三种办法解决这个问题:
- meta 标签禁用网页的缩放
<meta name="viewport" content="width=device-width user-scalable= 'no'">
- 更改默认视口宽度
<meta name="viewport" content="width=device-width">
如果能识别网站是响应式的网站,那么移动端浏览器就可以自动禁掉默认的双击缩放行为并去掉300ms的点击延迟
- 调用 js 库,比如 FastClick
click 延时问题可能引起点击穿透,如在一个元素上注册了 touchStart 的监听事件,这个事件会将这个元素隐藏掉,发现当这个元素隐藏后,触发了这个元素下的一个元素的点击事件
# 滚动穿透
若页面超过一屏高度出现滚动条时,fixed定位的弹窗遮罩层上下滑动,下面的内容也会一起滑动——滚动穿透
1、默认情况,平移(滚动)和缩放手势由浏览器专门处理,但可通过 CSS 特性 touch-action 改变触摸手势的行为
2、
Step 1、监听弹窗最外层元素(popup)的 touchmove 事件并阻止默认行为来禁用所有滚动(包括弹窗内部的滚动元素) Step 2、释放弹窗内的滚动元素,允许其滚动:同样监听 touchmove 事件,但是阻止该滚动元素的冒泡行为(stopPropagation),使得在滚动的时候最外层元素(popup)无法接收到 touchmove 事件
# 滚动溢出
弹窗内也含有滚动元素,在滚动元素滚到底部或顶部时,再往下或往上滚动,也会触发页面的滚动,这种现象称之为滚动链(scroll chaining), 也称为滚动溢出(overscroll)
借用 event.preventDefault 的能力,当组件滚动到底部或顶部时,通过调用 event.preventDefault 阻止所有滚动,从而页面滚动也不会触发了,而在滚动之间则不做处理
# with
警告:混淆错误和兼容性的问题
扩展一个语句的作用域链
# if内的函数?
let phrase = "Hello";
if (true) {
let user = "John";
function sayHi() {
alert(`${phrase}, ${user}`);
}
}
sayHi();
2
3
4
5
6
7
8
9
- https://zh.javascript.info/closure这里说因为if内声明的函数,所以报错
- 实际运行,能够正常输出值
# polyfills
补丁
例如浏览器太老,不支持Promise,我们可以自己定制实现现代语言功能
if (!window.Promise) {
window.Promise = ... // 定制实现现代语言功能
}
2
3
# use strict
ECMAscript5 添加的(严格)运行模式,使 JS 在更严格的条件下运行
- 消除 JS 语法的一些不合理、不严谨之处,减少一些怪异行为
- 消除代码运行的一些不安全之处,保证代码运行的安全
- 提高编译器效率,增加运行速度
- 为未来新版本的 JS 做好铺垫
区别:
- 1.禁止使用 with 语句
- 2.禁止 this 关键字指向全局对象
- 3.对象不能有重名的属性
只要函数参数使用了默认值、解构赋值、或者扩展运算符,函数内部就不能显式设定为严格模式,否则会报错
var num = 117
function func1() {
console.log(this.num)
}
(function () {
"use strict";
func1()
})()
"use strict"
function func2() {
console.log(this.num)
}
setTimeout(function () {
func2.call(this)
}, 0)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 定时刷新
setInterval不行,5s一刷新,万一请求10s返回数据,不久轮询了,直接卡死
setTimeout
requestAnimationFrame
<meta http-equiv="refresh" content="20">
// 注释:其中20指每隔20秒刷新一次页面
2
3
# 切面编程
/*实现在function的原型链新增before(fn),after(fn)两个函数*/
Function.prototype.before = function (beforeFn) {
let _this = this;
return function () {
beforeFn.apply(this, arguments);
return _this.apply(this, arguments)
}
}
Function.prototype.after = function (afterFn) {
var _self = this;
return function () {
var ret = _self.apply(this, arguments);
afterFn.apply(this, arguments);
return ret;
}
}
let func1 = () => console.log('func1');
func1 = func1.before(() => {
console.log('==before==');
}).after(() => {
console.log('==after');
});
let func2 = () => console.log('func2');
func2 = func2.before(() => {
console.log('==before==');
}).after(() => {
console.log('==after');
});
function main() {
func1();
func2();
}
main()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
面向切面编程(AOP) 和面向对象编程(OOP)一样,是编程范式
AOP主要应用在 与核心业务无关但又在多个模块使用的功能比如权限控制、日志记录、数据校验、异常处理等领域
# 尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
]递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误
为啥尾递归优化
# 解构赋值
是ES6提供的语法糖,针对可迭代对象的Iterator接口,按顺序获取对应的值赋值
for...of...也是遍历器,遍历数据结构时,寻找Iterator接口
Iterator——为各种数据解构提供统一访问接口,使数据结构能按次序排列处理
解构赋值,是浅拷贝!
解构的不定参数只能出现在 最后一个位置!
解构多层对象嵌套
使用 可选链 或 判断空值 解决
# ES2022
以前定义实例的默认值,只能通过constructor定义
现在
class Counter {
num = 0;
}
2
3
static声明静态字段和方法,静态类字段和方法属于整个类,并非某一具体的实例
class Counter {
// 静态字段
static NUM = 1
// 静态方法
static getNUM() {
return this.NUM
}
}
//只能通过类来直接访问类的静态字段和静态方法
console.log(Counter.NUM) //1
console.log(Counter.getNUM()) // 1
// 无法通过实例访问类的静态字段和静态方法
const counter = new Counter()
console.log(counter.NUM) // undefined
console.log(counter.getNUM()) // TypeError: counter.getNUM is not a function
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
以前await只能和async用,限制一些场景,如在全局作用域使用import的异步加载方式
可以使用.at()取数组的倒数元素
# 拖拽
- dragstart
元素被拖拽时触发【拖拽元素上绑定】 - dragend
被拖拽元素结束拖拽时触发【拖拽元素上绑定】 - dragover 被拖拽元素拖入目标区域后 触发 【目标区域绑定事件】
- drop 被拖拽元素拖入目标区域结束 触发 【在目标区域绑定】